At the heart of the rapidly expanding set of AI-powered applications are powerful AI models. Before these models can be deployed, they must be trained through a process that requires an immense amount of AI computing power. AI training is also an ongoing process, with models constantly retrained with new data to ensure high-quality results. Faster model training means that AI-powered applications can be deployed more quickly, speeding time to value.
MLPerf benchmarks, developed by the MLCommons consortium, are standardized and proven measures of AI performance across popular AI use cases. MLPerf Training v3.0 is the latest version of the AI training-focused suite of MLPerf tests, covering computer vision, language, and recommender systems, among others. The latest MLPerf Training v3.0 suite has been updated to incorporate a new large language model (LLM) test based on the GPT-3 175B model, representing generative AI. It also features an updated DLRM test with a substantially larger dataset to better represent modern AI-based recommenders.
In MLPerf Training v3.0, the NVIDIA AI platform powered by the NVIDIA H100 Tensor Core GPU set new performance records, achieving both the highest performance on a per-accelerator basis and delivering the fastest time to train on every benchmark at scale.
In addition, the full software stack used for MLPerf Training v3.0 is publicly available. Both NVIDIA submissions, as well as the joint submissions NVIDIA made with CoreWeave, were made in the available category of MLPerf. All NVIDIA submissions achieved similar or improved performance compared to NVIDIA H100 preview submissions in MLPerf Training v2.1.
This post takes a closer look at the performance delivered by the NVIDIA AI platform and the H100 Tensor Core GPU in MLPerf Training v3.0.
NVIDIA AI and H100 Tensor Core GPU deliver record results
NVIDIA H100 Tensor Core GPUs, which made their MLPerf Training debut just 6 months ago, set new per-accelerator performance records across all MLPerf Training v3.0 workloads. Looking at the NVIDIA single-node DGX H100 results this round, performance increased by up to 17% in just 6 months on the same hardware through software improvements alone. Compared to the NVIDIA A100 Tensor Core GPU submission in MLPerf Training v2.1, the latest H100 submission delivered up to 3.1x more performance per accelerator.
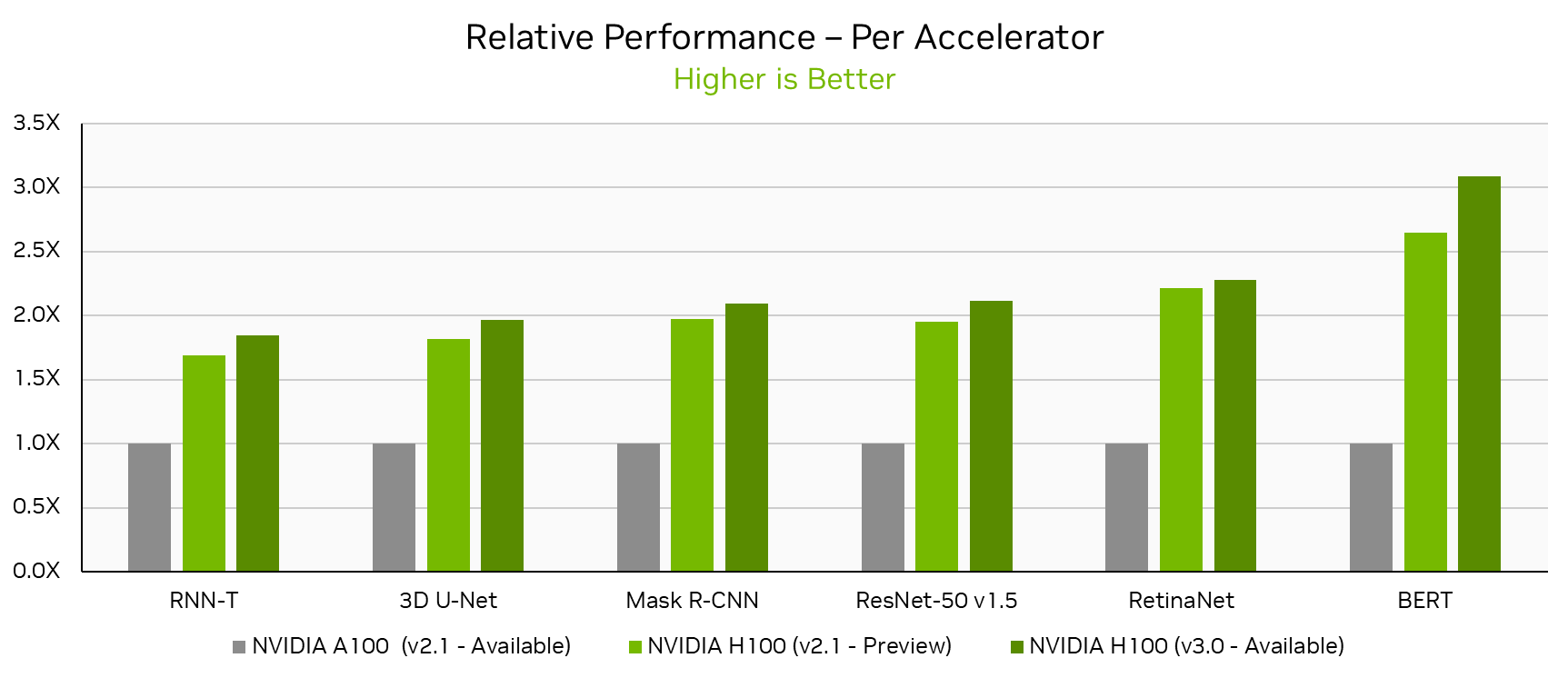
MLPerf result IDs: 2.1-2091, 2.1-2062, 2.1-2059, 2.1-2061, 2.1-2060, 3.0-2062, 3.0-2064. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
In this round, NVIDIA submitted results using the NVIDIA “Pre-Eos” AI supercomputer on up to 768 H100 GPUs. NVIDIA also made a joint submission with cloud service provider CoreWeave, using up to 3,584 H100 GPUs with the CoreWeave publicly available NVIDIA HGX H100 infrastructure.
Across these submissions, the NVIDIA AI platform with H100 GPUs set new time-to-train records at scale across every workload, including the new LLM workload.
| Benchmark | Max Scale Records(minutes) |
| Large language model (GPT-3) | 10.9 |
| Natural language processing (BERT) | 0.13 (8 seconds) |
| Recommendation (DLRMv2) | 1.61 |
| Object detection, heavyweight (Mask R-CNN) | 1.47 |
| Object detection, lightweight (RetinaNet) | 1.51 |
| Image classification (ResNet-50 v1.5) | 0.18 (11 seconds) |
| Image segmentation (3D U-Net) | 0.82 (49 seconds) |
| Speech recognition (RNN-T) | 1.65 |
MLPerf result IDs: 3.0-2002, 3.0-2075, 3.0-2001, 3.0-2077, 3.0-2066, 3.0-2070, 3.0-2003, 3.0-2065. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
The following section details some of the software optimizations behind these results.
NVIDIA software powering MLPerf results
NVIDIA MLPerf Training v3.0 submissions included numerous optimizations that increased performance on existing and updated MLPerf Training workloads and enabled excellent results on the new LLM test.
Large language model
The newly added LLM workload represents a state-of-the-art large language model with 175 billion parameters. Training this model requires full stack craftsmanship, as it stresses every part of an AI supercomputer, including compute, GPU memory bandwidth, and both internode and intranode interconnect capabilities.
In fact, the workload is so demanding that the smallest-scale NVIDIA submission on this workload used 512 of the latest H100 Tensor Core GPUs on the Pre-Eos system, achieving a time to train of 64.3 minutes. Scaling to 768 GPUs on the same Pre-Eos system reduced time-to-train to 44.8 minutes for near-linear scaling efficiency.
NVIDIA and CoreWeave also made joint submissions on the LLM workload using CoreWeave’s NVIDIA HGX H100 infrastructure at several scales, including 768-GPU, 1,536-GPU, and 3,584-GPU submissions. The 768-GPU submission on CoreWeave’s HGX H100 infrastructure delivered nearly identical performance to the 768-GPU Pre-Eos submission, demonstrating that the NVIDIA AI platform delivers great performance in both on-premises and commercially available cloud instances.
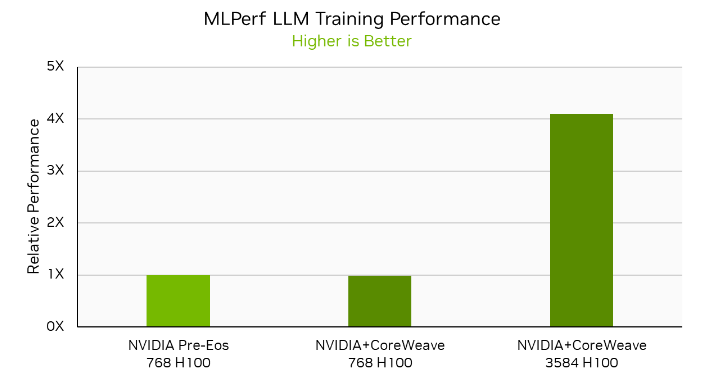
MLPerf result IDs: NVIDIA 3.0-2076, NVIDIA+CoreWeave 3.0-2004, NVIDIA+CoreWeave 3.0-2003. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
NVIDIA and CoreWeave also submitted LLM results on 3,584 GPUs, delivering a time to train of just 10.9 minutes. This is a more than 4x speedup compared to the 768-GPU submissions on H100, demonstrating 89% performance scaling efficiency even when moving from hundreds to thousands of H100 GPUs.
The software stack used in the MLPerf LLM submission includes NVIDIA NeMo framework combined with the NVIDIA Transformer Engine library and NVIDIA cuBLAS library, as well as the intelligent use of 8-bit floating-point precision (FP8) on a per-layer basis on NVIDIA H100 GPUs through these libraries.
BERT
Compared to the prior round, NVIDIA improved per-accelerator H100 performance on the BERT NLP workload by 17%. And NVIDIA and CoreWeave submitted BERT results on up to 3,072 H100 GPUs to deliver a record-setting time to train of 0.134 minutes (a mere 8 seconds).
In order to achieve this performance in publicly available NVIDIA software, the cuDNN library introduced FP8 I/O support in the fused Flash Attention used in the NVIDIA Transformer Engine library. cuDNN fused Flash Attention also supports packed sequence format for Flash Attention I/O, enabling BERT to train at high efficiency without wasting compute on padding tokens. See the cuDNN Developer Guide for more details about cuDNN fused Flash Attention and its documentation.
A summary of the key performance optimizations done in this round for BERT follows:
Data preprocessing
When training models at very large scales, data preprocessing on the CPU may result in significant overhead. To minimize the performance impact of this preprocessing, we overlapped data preprocessing for the next iteration with the computations being performed in the current iteration, reducing iteration time by 3%.
More performant random number generation
In BERT Multi-Head Attention, the online random number generation for the dropout layer starts to become a bottleneck once operations in multi-head attention are fused into a single kernel. This is more pronounced as the Tensor Core throughput of recent NVIDIA GPU architectures has grown faster than the random number generation speed.
To reduce the random number generation bottleneck, we introduced an optimization that uses a comparison of lower precision integer format (8-bit instead of 32-bit) in this MLPerf round, increasing random number generation throughput by 4x. In particular, instead of converting the random 128-bit integer that is produced by the random number generator to four 32-bit integers, we convert it to 16 8-bit integers. This optimization substantially reduces the overhead of random number generation in the multi-head attention block, and results in a 4% end-to-end performance improvement in the application for single-node submission. This optimization does not impact the accuracy or the output quality of the model.
CUDA Graphs
In this submission, we enabled CUDA Graphs for large batch scenarios like training on eight GPUs, through graph-capture support in cuDNN fused Flash Attention and Transformer Engine library, which required carefully handling seed and offset variables of random number generator in multi-head attention.
Optimizations have reduced conversions between FP16 and FP8 formats. In addition, optimizations in cuBLAS library resulted in 5% end-to-end performance improvement, through improved GEMM algorithm heuristics and support for the fusion of GEMM and gelu operations for H100. These optimizations combined boost single-node performance on BERT by 17% compared to the H100 preview submission in MLPerf Training v2.1.
ResNet-50 v1.5
In MLPerf Training v3.0, NVIDIA and CoreWeave made submissions using up to 3,584 H100 Tensor Core GPUs, setting a new at-scale record of 0.183 minutes (just under 11 seconds). Additionally, H100 per-accelerator performance improved by 8.4% compared to the prior submission through software improvements.
In this round, key improvements on the ResNet-50 v1.5 workload include the following:
Faster GroupBatchNorm with NVSHMEM
In this round, we implemented a faster GroupBatchNorm kernel using the NVIDIA NVSHMEM library and reducing inter-GPU communication latency by more than 5x. This new kernel is also able to make use of the high-bandwidth, inter-GPU NVIDIA NVLink interconnect to accelerate communication. This optimization resulted in an end-to-end speedup of 6% in the largest scale submission.
cuDNN kernels
The NVIDIA cuDNN team developed significantly improved convolution kernels that leverage the much faster Tensor Core throughput of the NVIDIA H100 GPU. These kernels led to 5% higher end-to-end performance in both single-node and efficient-scale submissions.
RetinaNet
NVIDIA submitted results on RetinaNet using up to 768 NVIDIA H100 Tensor Core GPUs, achieving a new performance record for the benchmark of just 1.51 minutes. Per-accelerator performance was also enhanced compared to the prior submission.
Optimizations of this round to achieve these results include:
Support for FP32 Master Weights in the Optimizer
The NVIDIA RetinaNet submission in MLPerf Training v3.0 used PyTorch Automatic Mixed Precision (AMP) to leverage the higher throughput that the NVIDIA H100 GPU provides for lower precision data types, like FP16.
However, as model parameters are still maintained in FP32, PyTorch AMP inserts dynamic type casting operations to convert between FP16 and FP32 data types while carrying out tensor operations in the lower precision.
To avoid this overhead, the optimizer maintains a separate set of model parameters stored in FP32 called “master weights.” The model parameters can now be cast entirely to FP16, avoiding the insertion of dynamic type casting operations. The optimizer can update the master weights using the FP16 gradients obtained during the backward pass. This optimization boosted training performance by 10%.
Data preprocessing
The NVIDIA RetinaNet submission uses the NVIDIA Data Loading Library (DALI), a portable, open-source library for decoding and augmenting images, videos, and speech to accelerate deep learning applications.
In MLPerf Training v3.0, the NVIDIA submission used DALI for both data loading and preprocessing of variable-sized images in the dataset. By profiling our large-scale training runs using NVIDIA Nsight Systems, we observed that memory reallocation operations in DALI occur at different times for different processes in the training process, leading to delays in training iterations.
Memory management operations in the DALI image decoder were one primary cause of jitter. These were removed by providing a hint to the largest image size in the dataset—an optimization that boosted performance by 10%.
Optimizations in cuDNN
The cuDNN library has been updated with enhanced kernels that better use the NVIDIA H100 fourth-generation Tensor Cores. These kernels increased the performance of convolutions in our RetinaNet submission, particularly for the smaller-sized ones that are key to at-scale performance, leading to up to 7.5% higher training throughput compared to our prior submission.
3D U-Net
NVIDIA submitted results on 432 NVIDIA H100 Tensor Core GPUs, achieving a new record for the benchmark of 0.82 minutes (49 seconds) to train. Per-accelerator performance on H100 also improved by 8.2% compared to the prior round.
To achieve excellent performance at scale, a faster GroupBatchNorm kernel was one key optimization.
In our largest scale 3D U-Net submission, the instance normalization operation in the neural network needs to perform a reduction of the tensor mean and variance across four GPUs. By using a faster GroupBatchNorm kernel to implement instance normalization, we delivered a 1.5% performance increase.
Mask R-CNN
This round, NVIDIA submitted results on Mask R-CNN using up to 384 H100 GPUs, achieving a new record time to train of 1.47 minutes. Per-accelerator performance also improved by 6.1% compared to the previous submission through software optimizations.
Optimizations this round focused on reducing CPU bottlenecks to ensure that the capabilities of the powerful H100 GPUs were better used.
Faster evaluation
The evaluation process computes the score after inference results have been gathered on a single rank. Since the H100 GPU is able to train significantly faster than the prior-generation A100 GPU, evaluation became a significant performance bottleneck.
In this round, each individual inference result is encoded as JSON (corresponding to a single prediction for each image) before gathering the results on a single rank. After the results were gathered, JSON strings for collections of inference results were formed by concatenating strings from the initial JSON encoding, rather than by decoding and encoding inference results as they passed through the scoring logic. This approach is substantially faster than encoding and decoding and yields a doubling in evaluation speed.
Faster annotations
In previous rounds, annotations—which contain target information for each sample—were loaded from a very large JSON file, a process that took up to 5 seconds. By storing annotations as serialized tensors and loading them, we reduced startup time by more than 80%.
Before annotations can be used for training, they must undergo transformations. Instead of performing these transformations independently for each image, we performed all transformations with a single global kernel as all images undergo the same transformations. This kernel is called once during load and is repeated at the beginning of each epoch.
This optimization reduced the amount of CPU work by nearly 20%. As Mask R-CNN was CPU-limited, training performance increased by almost 20%.
More CUDA graphs
In prior rounds, we CUDA-graphed everything except for loss calculations. We observed that loss calculations accounted for more than 40% of total step time, due to the loss calculation code being CPU bound. By CUDA-graphing the entire model, we improved training throughput by more than 30%.
DLRM_DCNv2
DLRM_DCNv2 is a new benchmark in MLPerf Training v3.0. It replaces the previous DLRM benchmark, with the following updates:
- Multi-hot dataset: The previous DLRM benchmark used a one-hot Criteo dataset. To better represent real-world use and application of recommenders, DLRM_DCNv2 adopts a multi-hot dataset. A multi-hot dataset has been synthesized from the original Criteo one-hot dataset for this purpose.
- Cross layer: The cross layer proposed in the paper DCN V2: Improved Deep and Cross Network and Practical Lessons for Web-scale Learning to Rank Systems is introduced for DLRM_DCNv2.
- Adagrad optimizer: The SGD optimizer used in DLRM is replaced with Adagrad optimizer in DLRM_DCNv2, as Adagrad is more commonly used in real-life recommenders.
Our submission uses the embedding collection in NVIDIA Merlin HugeCTR, which supports many sharding strategies and horizontally fuses embedding operations associated with different embedding shards to deliver excellent performance.
For scale-out training, we employed a hierarchical embedding strategy to leverage the hierarchical nature of the network fabric. This approach resulted in the following benefits:
- Embedding vectors in the same node are reduced by first leveraging NVIDIA NVLink connections to reduce the number of bytes needed to be transferred through the InfiniBand networking connecting GPUs between nodes.
- The reduced embedding vectors are then placed on GPUs that share the same InfiniBand rails as the destination GPU, minimizing transmission latency in rail-optimized systems.
The NVIDIA submission employed a module called input distributor in the embedding collection for performance and flexibility. This module converts the data-parallel input from the data reader to the model-parallel input needed by the embedding operations. To reduce the amount of traffic associated with the input distribution, category filtering is employed to only transmit the categories needed by each GPU. Furthermore, input data is prefetched and distributed to overlap the input distribution of the next iteration with the current iteration, thereby boosting training throughput.
MLPerf Training v3.0 takeaways
The NVIDIA AI platform delivered record-setting performance in MLPerf Training v3.0, highlighting the exceptional capabilities of the NVIDIA H100 GPU and the NVIDIA AI platform for the full breadth of workloads—from training mature networks like ResNet-50 and BERT to training cutting-edge LLMs like GPT-3 175B. The NVIDIA joint submission with CoreWeave using their publicly available NVIDIA HGX H100 infrastructure showcased that the NVIDIA platform and the H100 GPU deliver great performance at very large scale on publicly-available cloud infrastructure.
The NVIDIA platform delivers the highest performance, and greatest versatility, and is available everywhere. All software used for NVIDIA MLPerf submissions is available from the MLPerf repository, so you can reproduce these results. All NVIDIA AI software used to achieve these results is also available in the enterprise-grade software suite, NVIDIA AI Enterprise.
