
MLPerf is an industry-wide AI consortium that has developed a suite of performance benchmarks covering a range of leading AI workloads that are widely in use today. The latest MLPerf v0.7 training submission includes vision, language, recommenders, and reinforcement learning.
NVIDIA submitted MLPerf v0.7 training results for all eight tests and the NVIDIA platform set records in all benchmarks in the commercially available solutions category, setting 16 performance records with eight on a per-chip basis and eight at scale.
| Benchmark | Max Scale Records | Per Accelerator Records |
| Recommendation (DLRM) | 3.33 min. | 0.44 hrs. |
| NLP (BERT) | 0.81 min. | 6.53 hrs. |
| Reinforcement Learning (Minigo) | 17.07 min. | 39.96 hrs. |
| Translation (Non-recurrent) Transformer | 0.62 min. | 1.05 hrs. |
| Translation (Recurrent) GNMT | 0.71 min. | 1.04 hrs. |
| Object Detection (Heavy Weight) Mask R-CNN | 10.46 min. | 10.95 hrs. |
| Object Detection (Light Weight) SSD | 0.82 min. | 1.36 hrs. |
| Image Classification (ResNet-50 v1.5) | 0.76 min. | 5.30 hrs. |
For more information about configuration, see the list of MLPerf disclosures in the Summary section.
NVIDIA engineers have developed a host of innovations to achieve these levels of performance. This post details many of the optimizations used to deliver the outstanding scale and performance.
Many of these improvements have been made available on NGC, which is the hub for NVIDIA GPU-optimized software. The AI community can thus realize the benefits of these optimizations in their real-world applications, not just better benchmark scores. To replicate NVIDIA MLPerf performance level on your workloads, see Accelerating AI Training with MLPerf Containers and Models from NVIDIA NGC.
Large-scale
Large-scale training requires system hardware and software to be precisely tuned to work together and support the unique performance requirements that arise at scale. NVIDIA has made major advances on both dimensions that are available today for production use.
On the system side, the key element is our new DGX SuperPOD. DGX SuperPOD is based on the NVIDIA DGX A100 with the latest NVIDIA A100 Tensor Core GPU, third-generation NVIDIA NVLink, NVSwitch, and the NVIDIA Mellanox ConnectX-6 VPI 200Gb/s HDR InfiniBand. These were combined into a top 10 supercomputer with the following resources:
- 2,240 NVIDIA A100 Tensor Core GPUs
- 280 NVIDIA DGX A100 systems
- 494 Mellanox 200G HDR InfiniBand switches
- 7 PB of all flash storage
On the software side, NGC 20.06 enables several new capabilities, including the following:
- Distributed optimizer support. As training scales, if every GPU does the full optimizer work, the optimizer can dominate the overall training time. NGC 20.06 introduces distributed optimizer support for PyTorch.
- CUDA Graphs support in MXNet. On a large scale, batch sizes are reduced to the minimum and CPU-side overhead can easily become the performance limiter if the CPU is required to continuously re-analyze the input and re-create output commands targeted to the GPU. Graphs allow the work of creating CUDA commands to be done one time and then saved and reused through the rest of the training cycle.
- Improved communication efficiency with Mellanox HDR InfiniBand and NCCL 2.7.5.
Now, I describe these changes in more detail.
Distributed optimizer
When training neural networks on many GPUs, each GPU typically processes a small minibatch with few samples. This means the forward pass and backward pass in each training iteration run quickly, as there is little work to be done. However, the optimizer (such as SGD or Adam) at the end of each training iteration takes constant time irrespective of the number of GPUs, as its runtime depends only on the size of the model (number of weights), not the size of the minibatch per GPU. This means that optimizer step execution becomes dominant when running on a large scale.
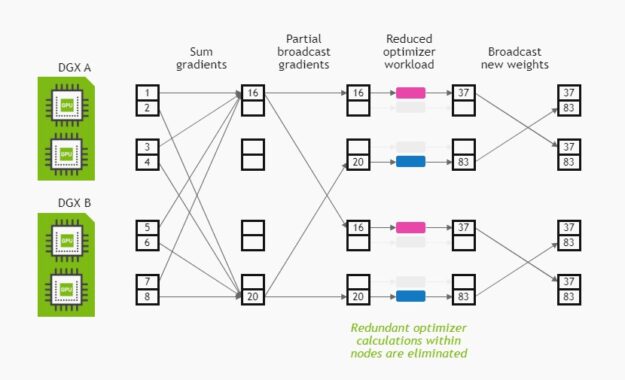
To avoid this, we implemented a distributed optimizer algorithm that distributes the optimizer workload among GPUs inside a DGX node, leading to an up to 16x reduction in optimizer time on a DGX-2H (8x on a DGX A100). Using the flexibility provided by NCCL, this can be achieved by partitioning the reduction of gradient values that is performed before the optimizer step into three segments: a reduce-scatter, a parallel allreduce, and a final all-gather. We insert the optimizer update before the final all-gather. This way, each GPU within a node updates a unique shard of the model, and the final all-gather distributes the updated weights among GPUs. Figure 1 shows the distributed optimizer algorithm.
CUDA Graphs
Because training iteration time on the GPU becomes so short, it can be critical to ensure that the CPU can keep up with the GPU on large scales. This can be challenging because the number of kernels launched to execute an iteration is roughly proportional to the number of the layers in the neural network, so the launch work that the host CPU performs remains constant irrespective of the number of GPUs and potentially becoming the bottleneck when many GPUs are used.
There are many ways to address this problem, but two methods relied on in this MLPerf round were ensuring the use of well-optimized, low-overhead CPU-side code, as well as enabling the CUDA 10 feature called CUDA Graphs. Graphs enable the construction of a dependency graph of GPU work on the CPU, then submitting the entire graph to the GPU with a single host-device interaction. This is the ideal scenario, as it moves the dependency resolution between kernels entirely to the GPU and fully removes host-side execution from the critical path.
NCCL 2.7.5
Includes many enhancements over previous NCCL versions, such as support for third-generation NVLink on A100 GPUs and Mellanox HDR InfiniBand, better performance for collective allreduce operations, as well as a brand-new, all-to-all primitive used in the DLRM benchmark. I discuss this later in the post.
Workloads
Two of the most important AI use cases today are recommenders and natural language processing (NLP). They underpin many of the interactions you have while shopping online, watching media content, searching the web, or interacting with a voice assistant. These are both new to MLPerf this submission round and NVIDIA delivered new innovations on these workloads.
Recommendations (DLRM)
We submitted the DLRM benchmark with two different implementations: One using NGC PyTorch 20.06, and one using the recently announced Merlin HugeCTR v2.2 framework.
In both, we implemented a hybrid parallel version of DLRM that distributes embedding tables among GPUs in a model-parallel fashion, then switches to data parallelism for the MLP segment of the neural network. In support of this, NCCL 2.7 includes a brand-new, highly optimized, all-to-all implementation to accelerate the data exchange at the interface between the model and data parallel segments.
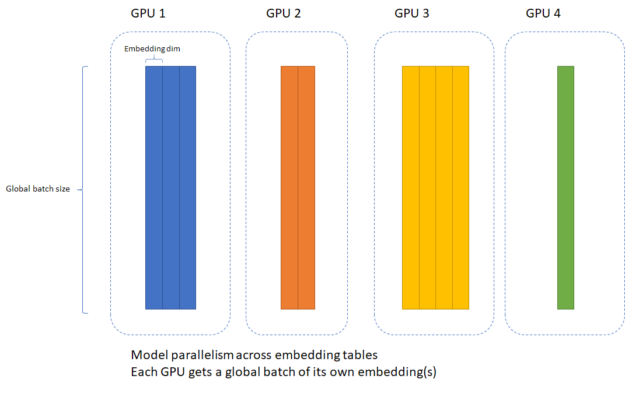
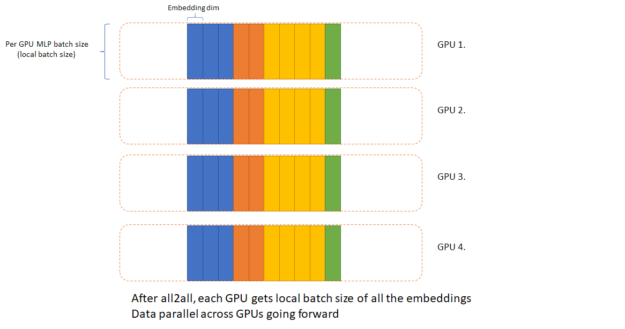
Merlin HugeCTR includes many optimizations focusing specifically on accelerated recommender training, such as highly optimized dataflow between embeddings, inter-GPU communication in hybrid parallelism, an optimized memory allocator to minimize host-side overhead, and many general improvements to reduce CPU overhead. With these optimizations, HugeCTR can run more efficiently with smaller batch sizes or on more GPUs than other frameworks.
For the PyTorch submission, we developed a highly optimized MLP primitive in the NVIDIA Apex library, apex.MLP, that includes optimizations for the host-side performance to keep the GPU supplied with work, as well as interlayer fusions, such as combining relu and bias operations into individual kernels.
Finally, in both PyTorch and HugeCTR, we accelerated embedding lookups and dot interactions, two key operations in DLRM and recommenders in general, with optimized GPU kernels that achieve higher performance.
NLP (BERT)
In the BERT model, several key optimizations led to dramatic performance improvements over the original BERT code.
A key building block of BERT networks is multi-head attention (MHA). This neural network segment attends over input sequence data to figure out which input tokens matter the most. In BERT, there are 24 Transformer blocks, each containing one MHA block, so having a fast implementation is crucial.
For this purpose, we developed apex.multihead_attn, a highly performant yet flexible MHA implementation that features minimal host-side overhead to accelerate GPU work submission, horizontal fusions among linear layers, complete removal of format transposes, as well as vertical layer fusions such as fusing softmax and dropout. For BERT, using Apex MHA improved performance by nearly 40% end-to-end. The MHA module can be configured with parameters, enabling easy adoption for many different models.
Outside of MHA, we also implemented vertical layer fusions in the GELU activation layers used in the feed-forward networks, combining them with the bias addition layers that precede them.
Here are the software improvements implemented on the remaining models:
- Image classification and ResNet-50
- Lightweight object detection and SSD
- Non-recurrent translation and Transformer
- Recurrent translation and GNMT
- Reinforcement learning
Image classification (ResNet-50)
For ResNet-50, our MLPerf v0.7 submission builds upon the highly optimized implementation used in past MLPerf submissions, with several key advancements.
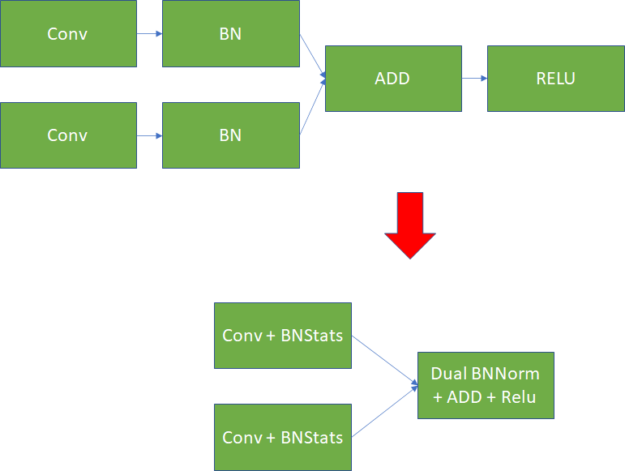
We improved the interlayer fusion scheme further by supporting fused convolution-batchnorm-relu operations in every layer of ResNet. Previously, these were restricted to non-residual layers, leading to wasted memory bandwidth in the network whenever residual tensors are added in. Figure 3 shows the difference.
Another major improvement was the use of CUDA Graphs. ResNet-50 uses fully static input data sizes from one iteration to the next, so that it can benefit from a scheme where the entire network’s forward-backward iteration is constructed as a CUDA graph one time before the actual training. The training itself is then able to launch the previously constructed graph, enabling the host CPU to supply the GPU with an entire ResNet worth of work with a single host-device interaction, eliminating any launch overheads that might prevent the GPU from executing at maximum speed.
Finally, we continuously optimized the convolution implementation provided by cuDNN for better performance.
Lightweight object detection (SSD)
For MLPerf v0.7, NVIDIA submitted the SSD object detection benchmark with two different frameworks for the first time: PyTorch for a single node with a few GPUs, and MXNet at maximum scale with thousands of GPUs.
The move to MXNet for the large-scale SSD training runs was motivated by MXNet’s excellent runtime performance due to hybridization, which enabled us to write imperative code but execute it with the low host-side overhead of symbolic graph execution. SSD training iteration times on a large scale become short while the number of GPU kernels to launch remains constant. Paying careful attention to CPU overhead becomes critical. The switch to MXNet also enabled us to take advantage of MXNet’s experimental support for CUDA Graphs, which reduces host-side overhead even further.
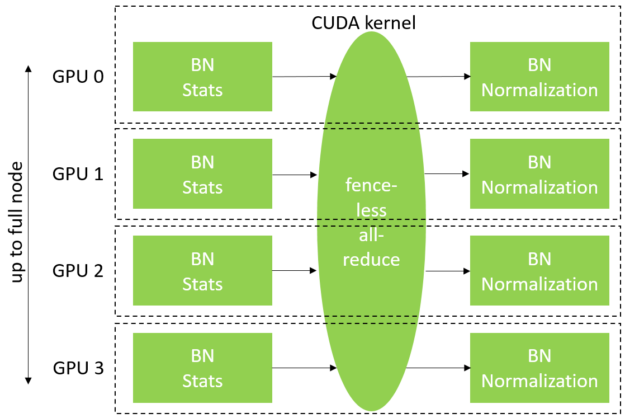
Executing at such a large scale means the batch size per GPU becomes tiny. In our largest submission, each GPU processes just two images per iteration. With batch sizes this small, the effectiveness of batch normalization (BN) operations starts to degrade, as not enough samples are seen by each BN layer to produce meaningful batch statistics to normalize the activation tensor.
To make it work, the group BN implementation exchanges BN statistics across GPUs within a DGX node, effectively enlarging the BN span to emulate a larger batch size. In this round of MLPerf, we improved our group BN kernels to enable them to span the entire node (up to 16 GPUs in a DGX-2H) while also significantly improving their performance with a fenceless synchronization algorithm. Figure 4 shows an overview of group BN.
There were several other key optimizations performed to enable large-scale execution:
- We used NVIDIA DALI to supply evaluation with input data quickly enough to keep the GPUs busy.
- We carefully eliminated load imbalance between GPUs in the input data pipeline by tuning where and when data is moved from the CPU to the GPU.
These optimizations enabled V100 MLPerf submissions to improve time to train by 2.3x compared to MLPerf v0.6 and at a significantly larger scale.
For more information about configuration, see the list of MLPerf disclosures in the Summary section.
Heavyweight object detection (Mask R-CNN)
Advanced object detection networks often contain complex operations that don’t involve tensor math and can become a bottleneck if not optimized. Examples that can be seen in Mask R-CNN include a region-proposal network (RPN), non-maximum suppression, bounding box and mask head loss computations, nearest-neighbor interpolation, and region of interest calculations.
To improve performance on this type of network, we developed optimized versions of these functions that are now used in the Mask R-CNN codebase. In addition to improving performance on each algorithm individually, we also introduced batched computation support for many of them.
Batched computation means that instead of the host CPU iterating over samples in the batch and launching individual kernels for each one, the entire operation is run on the GPU in a single kernel, reducing host overhead and improving parallel efficiency on the GPU. Tensor operations generally already operate as one compute step across an entire batch of inputs. Now, these other operations can get similar efficiency benefits.

Non-recurrent translation (Transformer)
The Transformer neural machine translation benchmark benefits from several key improvements in MLPerf v0.7.
Like BERT, Transformer relies on MHA modules in all its macro-layers. The MHA structure in BERT and Transformer is similar, so Transformer also enjoys the performance benefits of apex.multihead_attn described earlier.
Second, the large-scale Transformer submissions benefit from the distributed optimizer implementation previously described in the At scale section, as weight update time otherwise becomes a limiting factor when running on many GPUs, with small minibatch sizes per GPU.
These improvements enabled V100 to improve performance from MLPerf v0.6 by nearly 2x performance and run at 2x larger scale.
For more information about configuration, see the list of MLPerf disclosures in the Summary section.
Recurrent translation (GNMT)
For the LSTM-based GNMT benchmark, we use a persistent LSTM implementation from cuDNN that stores recurrent layer weights on-chip to reduce weight matrix load bandwidth. In MLPerf v0.7, we optimized these kernels to achieve high performance down to smaller minibatch sizes than they were previously capable of, allowing us to distribute GNMT on a larger number of GPUs, each running a smaller batch size. As with Transformer, we also used the multi-GPU distributed optimizer that distributes the optimizer work among GPUs within a DGX node.
Reinforcement learning (Minigo)
Minigo learns by playing games against itself: self play. At its heart, it uses a neural network model, in combination with a powerful search algorithm, to predict moves and the eventual winner of a game.
After self play completes a predetermined number of games (N), the model is updated by a train process (ResNet-like training with Go board positions as input) that feeds off a buffer of self-play games completed using many previous models. Subsequently, the updated model is used to self-play newer games and this loop continues until Minigo achieves target accuracy. Each iteration of this loop is a generation.
We train Minigo on a large-scale, distributed, MPI-based system that performs the following tasks:
- Tightly scheduling each self-play process (C++ based Go game engine) and multi-node distributed train process (Horovod-TensorFlow) across as many as 224 nodes of DGX A100.
- Orchestrating data communication between self-play and train nodes.
- Eliminating the overhead of restarting self-play and train processes every generation.
- Scheduling multiple self-play processes per GPU to achieve high GPU utilization.
Popular frameworks like TensorFlow and PyTorch support training neural networks but not complex environments like training Go. Further, we employ TensorRT-based inference with FP16 precision in self play, and FP16 mixed precision for train processes to use the high-throughput Tensor Cores available in NVIDIA DGX A100 systems.
The lessons from Minigo are applicable to accelerating massive deep reinforcement learning problems in general, examples of which include training autonomous agents for video games, driverless transportation, and neural architecture search.
Summary
MLPerf v0.7 showcases the continuous innovation that is happening in the AI domain. The NVIDIA platform delivers leadership performance with tight integration of hardware, data center technologies, and software to realize the full potential.
We are constantly improving our AI platform and making those improvements freely available to the broader AI community using NGC, and you can download them now.
MLPerf v0.7 submission information
Per-Chip Performance arrived at by comparing performance at the same scale when possible.
Per Accelerator comparison using reported performance for MLPerf 0.7 NVIDIA 8xA100. MLPerf ID DLRM: 0.7-17, ResNet50 v1.5: 0.7-18, 0.7-15, BERT, GNMT, Mask R-CNN, SSD, Transformer: 07-19, Minigo: 0.7-20.
MLPerf ID Max Scale: ResNet50 v1.5: 0.7-37, Mask R-CNN: 0.7-28, SSD: 0.7-33, GNMT: 0.7-34, Transformer: 0.7-30, Minigo: 0.7-36 BERT: 0.7-38, DLRM: 0.7-17.
MLPerf ID Max Scale Comparison for SSD and Transformer for V100: SSD: 0.6-27, 0.7-53 Transformer: 0.6-28, 0.7-52.
The MLPerf name and logo are trademarks. For more information, see mlperf.org.
