
NVIDIA CUDA-Q is an open-source programming model for building quantum-classical applications. Useful quantum computing workloads will run on heterogeneous computing architectures such as quantum processing units (QPUs), GPUs, and CPUs in tandem to solve real-world problems. CUDA-Q enables the acceleration of such applications by providing the tools to program these computing architectures harmoniously.
The ability to target multiple QPUs and GPUs is essential to scale quantum applications. Distributing workloads over multiple compute endpoints can achieve significant speedups when these workloads can be parallelized. A new CUDA-Q feature enables programming multi-QPU platforms along with multiple GPUs seamlessly.
Much of the acceleration in CUDA-Q is done using Message Passing Interface (MPI), a communication protocol used for parallel programming. It is particularly useful for solving problems that require large amounts of computation, such as weather forecasting and fluid and molecular dynamics simulations. Now, CUDA-Q can be integrated with any MPI implementation using an MPI plugin, so customers can easily use CUDA-Q with the MPI setup they already have.
Scale circuit simulation with multi-GPUs
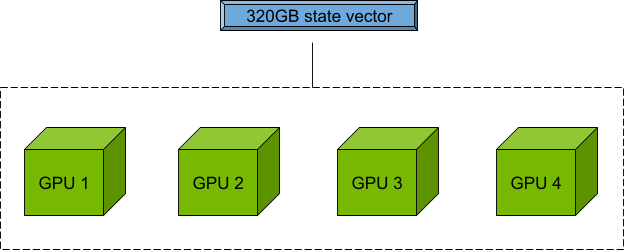
Circuit simulation for \(n\) qubits is limited by the memory required to store the \(2^n\) dimensional state vector. NVIDIA Hopper H100 GPUs offer 80 GB of memory each for the CUDA-Q targets to perform exact state vector simulation beyond the limits of what is feasible with current QPU hardware.
Moreover, the nvidia-mgpu target pools the memory of multiple GPUs in a node and multiple nodes in a cluster to enable scaling and remove the single GPU memory bottleneck. This out-of-the-box software tool in CUDA-Q works the same for a single node as it does for tens or even thousands of nodes. Qubit counts are only limited by the GPU resources available.
So, for a node with four GPUs, each with 80 GB of memory, you can use 80 x 4 = 320 GB of memory to store and manipulate the quantum state vector for circuit simulation.
Parallelization with multi-QPUs
The multi-QPU mode enables you to program future workflows where parallelization can reduce the runtime by a factor of the compute resources available.
Imagine a circuit cutting protocol where one cut requires running multiple subcircuits, the results of which are stitched back together in post-processing. In traditional software, these subcircuits would be executed sequentially. However, with the nvidia-mqpu target in CUDA-Q, execution of these subcircuits will occur in parallel, drastically reducing runtime.
Currently, each QPU in the nvidia-mqpu target is a GPU. With the rate at which quantum hardware is advancing, QPU data centers are fast approaching.
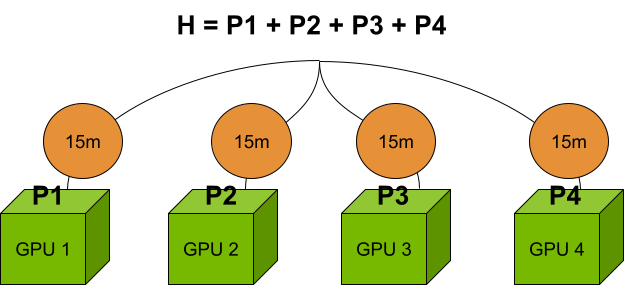
Another common workflow that’s “embarrassingly parallel” is the computation of the expectation value of a Hamiltonian with many terms. With multi-QPU mode, you can define multiple endpoints, where each endpoint can simulate an independent part of the problem. Using the nvidia-mqpu target, you can run, for example, multiple terms of a Hamiltonian in parallel in an asynchronous fashion. For details, see Programming the Quantum-Classical Supercomputer.
For the cluster of four GPUs mentioned previously, calculating the Hamiltonian terms in parallel, compared to evaluating them on a single GPU, achieves a 4x speedup. If the sequential computation takes 1 hour, with multiple endpoints, it only takes 15 minutes. However, the problem size on each GPU is still limited to 80 GB.
Combining multi-QPU and multi-GPU workloads
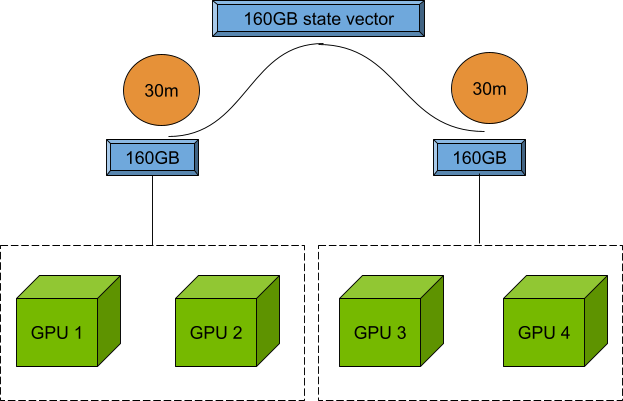
As explained previously, it’s possible to achieve the scale of quantum circuit simulation with the nvidia-gpu target and parallelization with the nvidia-mqpu target. With CUDA-Q 0.6, you can now combine the two, enabling large-scale simulations to run in parallel.
Returning to the previous example, if the sequential computation took 1 hour, with two endpoints, it would only take 30 minutes, but each endpoint can be made of two NVIDIA A100 GPUs and hold a 160 GB state vector.
As a developer, you can now experiment to find the sweet spot between the problem size and the number of parallel endpoints, utilizing your GPUs to a maximum. See the CUDA-Q documentation to learn more about the remote-mqpu target.
MPI plugin
MPI is a communication protocol used for programming parallel computers.
CUDA-Q makes use of MPI and is built with Open MPI, which is an open-source implementation of the MPI protocol. There are other popular MPI implementations such as MPICH and MVAPICH2 and many high-performance computing (HPC) centers or data centers are already set up with a specific implementation.
Now it’s easier than ever to integrate CUDA-Q with any MPI implementation, through an MPI plugin interface. A one-time activation script is needed to create a dynamic library for the implementation. CUDA-Q 0.6 includes plugin implementations compatible with Open MPI and MPICH. Contributions for additional MPI implementations are welcome and should be easy to add.
Learn more about how to use the MPI plugin in the Distributed Computing with MPI section of the CUDA-Q documentation.
Learn more about CUDA-Q
Visit NVIDIA/cuda-quantum to view the full CUDA-Q 0.6 release log. CUDA-Q Quick Start walks you through the setup steps with Python and C++ examples. For advanced use cases for quantum-classical applications, see the CUDA-Q Tutorials. Finally, explore the code, report issues, and make feature suggestions in the CUDA-Q open-source repository.
