
Three trends continue to drive the AI inference market for both training and inference: growing data sets, increasingly complex and diverse networks, and real-time AI services. MLPerf Inference 0.7, the most recent version of the industry-standard AI benchmark, addresses these three trends, giving developers and organizations useful data to inform platform choices, both in the datacenter and at the edge.
The benchmark has expanded the usages covered to include recommender systems, speech recognition, and medical imaging systems. It has upgraded its natural language processing (NLP) workloads to further challenge systems under test. The following table shows the current set of tests. For more information about these workloads, see the MLPerf GitHub repo.
| Application | Network Name |
| Recommendation* | DLRM (99% and 99.9% accuracy targets) |
| NLP* | BERT (99% and 99.9% accuracy targets) |
| Speech Recognition* | RNN-T |
| Medical Imaging* | 3D U-Net (99% and 99.9% accuracy targets) |
| Image Classification | ResNet-50 v1.5 |
| Object Detection | Single-Shot Detector with MobileNet-v1 |
| Objection Detection | Single-Shot Detector with ResNet-34 |
*New workload
Additionally, the benchmark tests across several scenarios, both for Data Center and Edge:
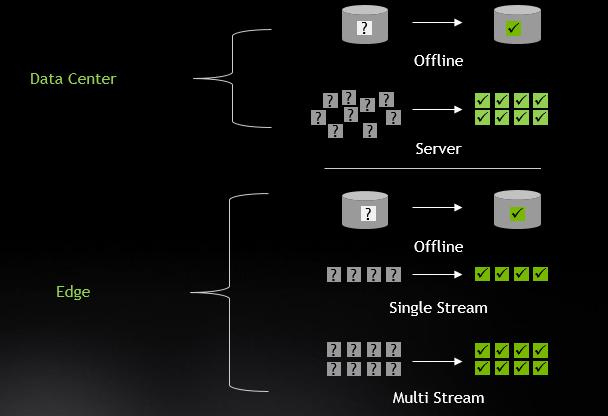
NVIDIA handily won across all tests and scenarios in both the Data Center and Edge categories. While much of this great performance traces back to our GPU architectures, more has to do with the great optimization work by our engineers, which is now available to the developer community.
In this post, I drill down into the ingredients that led to these excellent results, including software optimization to improve efficiency of execution, Multi-Instance GPU (MIG) to enable one A100 GPU to operate as up to seven independent GPUs, and the Triton Inference Server to support easy deployment of inference applications at datacenter scale.
Optimizations examined
NVIDIA GPUs support both int8 and FP16 precision inferencing at high throughput so that you can achieve great inferencing performance by default, without any quantization effort. However, quantizing the network to int8 precision while maintaining accuracy is the highest performance option, enabling 2x higher math throughput rates.
In this submission, we found that FP16 was required to meet the highest accuracy target for BERT. For this workload we used our FP16 Tensor Cores. In other workloads, we met the highest accuracy target (>99.9% of FP32 for DLRM and 3D-Unet) using int8 precision. In addition, the performance of int8 submissions benefited from speedups across the board in the TensorRT 7.2 software release.
Many inferencing workloads require significant preprocessing work. The NVIDIA open-source DALI library is designed to accelerate preprocessing on GPU and avoid CPU bottlenecks. In this submission, we used DALI to implement the wav-to-mel conversion for the RNN-T benchmark.
NLP inferencing operates on a piece of input text with a particular sequence length (the number of words in the input). For batched inferencing, one approach is to pad all the inputs to the same sequence length. However, this adds compute overhead. TensorRT 7.2 adds three plugins to support variable sequence length processing for NLP. Our BERT submission used these plugins to gain >35% end-to-end performance.
Accelerated sparse matrix processing is a new capability that has been introduced in A100. Sparsifying a network does require a retraining run and recalibration of weights to function correctly, so sparsity is not an available optimization in the Closed category but it is permitted in the Open category. Our Open category BERT submission used sparsity to achieve a 21% improvement in throughput while preserving the same accuracy as our Closed submission.
Understanding MIG in MLPerf
A100 introduces the new Multi-Instances GPU (MIG) technology that allows A100 to be partitioned into up to seven GPU instances, each of which provisioned with its own hardware-isolated compute resources, L2 cache, and GPU memory. MIG allows you to choose whether you’d like A100 to operate as a single large GPU or as many smaller GPUs that can each serve a different workload with isolation between them. Figure 2 shows the MLPerf results that put this technology to the test.
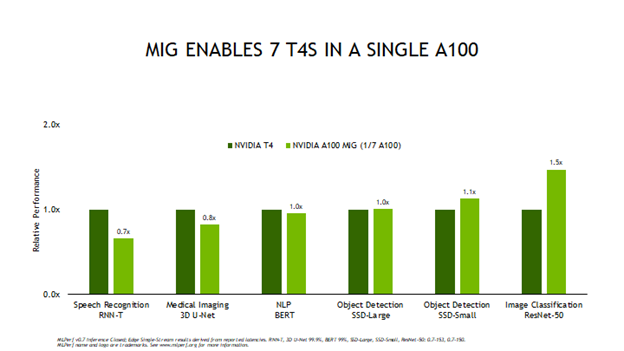
Figure 2 compares the Edge Offline performance of a single MIG instance compared to a full T4 GPU, as A100 can support up to seven MIG instances. You can see that more than four of the MIG test results score higher than a full T4 GPU. What this means for applications is that you can load up a single A100 with multiple networks and applications and run each of them with about equal or better performance than a T4. That reduces the number of servers deployed, frees up rack space, and reduces energy consumption. In addition, running multiple simultaneous networks on a single A100 helps keep GPU utilization high, so infrastructure managers can make optimal use of deployed compute resources.
Triton Inference Server
After a network has been trained and optimized, it’s ready to be deployed but that’s not as simple as flipping a switch. There are several challenges to address before an AI-powered service can go live. These include provisioning the right number of servers to maintain SLAs and ensure great user experiences for all services running on the AI infrastructure. However, the “right number” can change over time or due to a sudden shift in workload demand. An ideal solution also implements load-balancing so that infrastructure is optimally utilized, but never oversubscribed. In addition, some managers want to run multiple networks on individual GPUs. Triton Inference Server solves these challenges and more, making it much easier for infrastructure managers to deploy and maintain their server fleet responsible for delivering AI services.
In this round, we submitted results using Triton Inference Server as well, which simplifies the deployment of AI models at scale in production. This open-source inference serving software lets teams deploy trained AI models from any framework (TensorFlow, TensorRT, PyTorch, ONNX Runtime, or a custom framework). They can also deploy from local storage, Google Cloud Platform, or Amazon S3 on any GPU– or CPU-based infrastructure (cloud, data center, or edge).
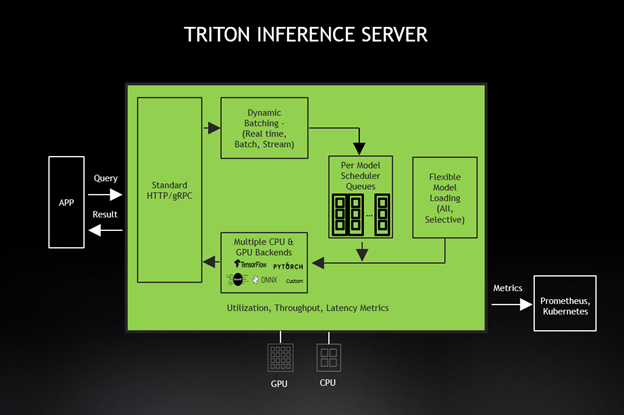
Triton, also available as a Docker container, is designed for a microservices-based application. Triton tightly integrates with Kubernetes, which brings dynamic load-balancing to keep all network inference operations moving smoothly. GPU metrics from Triton help Kubernetes shift inference work to an available GPU and scale to hundreds of GPUs when needed. The new Triton 2.3 supports serverless inferencing with KFServing, Python custom backends, decoupled inference serving for conversational AI, and support for A100 MIG as well as Azure ML and DeepStream 5.0 integrations.
Figure 4 shows Triton’s overall efficiency compared to running A100 custom inference serving solution, with both configurations running with TensorRT.
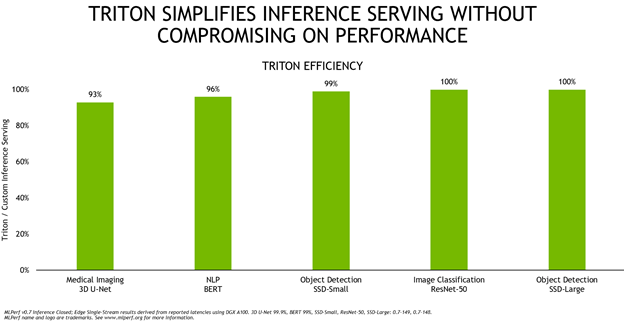
Triton is highly efficient and delivers equal performance or close to it across these five networks. To deliver such performance, the team brought many optimizations to Triton, such as new lightweight data structures for low latency communication with applications, batched data loading for improved dynamic batching, and CUDA graphs for the TensorRT backend for higher inference performance. These enhancements are available to every application as part of the 20.09 Triton container. In addition to this efficiency, Triton eases deployment, whether on-premises or in the cloud. This keeps all network inferencing moving smoothly, even when unexpected demand spikes hit.
Accelerate inference applications today
Given the continuing trends driving AI inference, the NVIDIA inference platform and full-stack approach deliver the best performance, highest versatility, and best programmability, as evidenced by the MLPerf Inference 0.7 test performance. Much of the work that went into making these wins happen is now available to you and the rest of the developer community, primarily in the form of open-source software. In addition, TensorRT and Triton Inference Server are freely available from NVIDIA NGC, along with pretrained models, deep learning frameworks, industry application frameworks, and Helm charts. The A100 GPU has demonstrated its ample inference capabilities. Along with the full NVIDIA inference platform, the A100 GPU is ready to take on the toughest AI challenges.
