MLPerf benchmarks, developed by MLCommons, are critical evaluation tools for organizations to measure the performance of their machine learning models’ training across workloads. MLPerf Training v2.1—the seventh iteration of this AI training-focused benchmark suite—tested performance across a breadth of popular AI use cases, including the following:
- Image classification
- Object detection
- Medical imaging
- Speech recognition
- Natural language processing
- Recommendation
- Reinforcement learning
Many AI applications take advantage of multiple AI models deployed in a pipeline. This means that it is critical for an AI platform to be able to run the full range of models available today as well as provide both the performance and flexibility to support new model innovations.
The NVIDIA AI platform submitted results on all workloads in this round and it continues to be the only platform to have submitted results on all MLPerf Training workloads.
![Diagram shows a user asking their phone to identify the type of flower in an image and the many AI models that may be used to perform this identification task across several domains[SBE1] : audio, vision, recommendation, and TTS.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/11/model-use-case.png)
NVIDIA Hopper delivers a big performance boost
In this round, NVIDIA submitted its first MLPerf Training results using the new H100 Tensor Core GPU, demonstrating up to 6.7x higher performance compared to the first A100 Tensor Core GPU submission and up to 2.6x more performance compared to the latest A100 results.
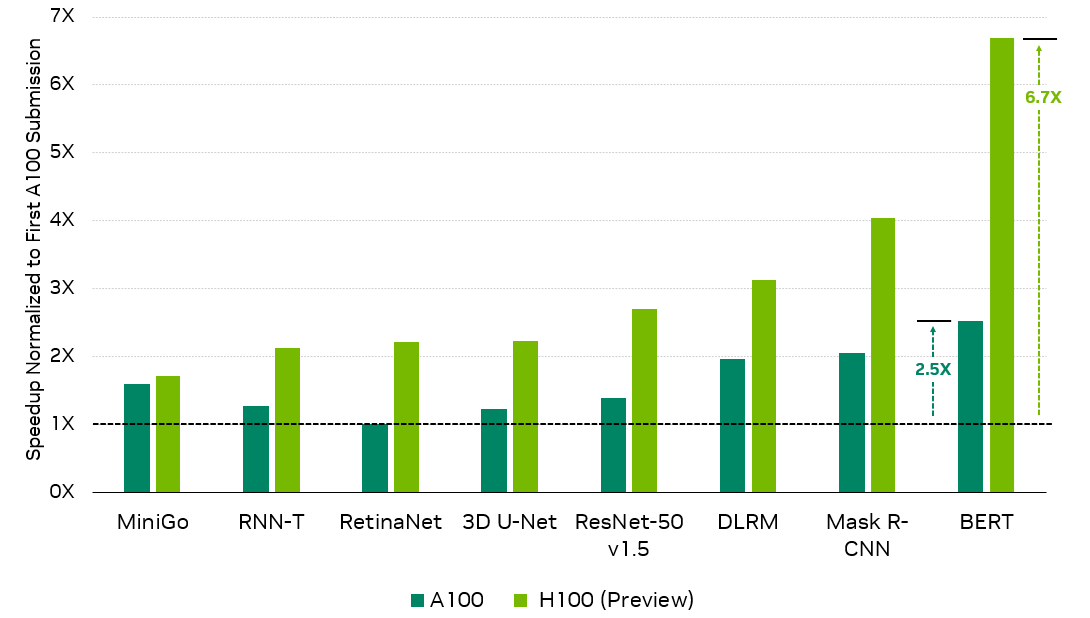
ResNet-50 v1.5: 8x NVIDIA 0.7-18, 8x NVIDIA 2.1-2060, 8x NVIDIA 2.1-2091 | BERT: 8x NVIDIA 0.7-19, 8x NVIDIA 2.1-2062, 8x NVIDIA 2.1-2091 | DLRM: 8x NVIDIA 0.7-17, 8x NVIDIA 2.1-2059, 8x NVIDIA 2.1-2091 | Mask R-CNN: 8x NVIDIA 0.7-19, 8x NVIDIA 2.1-2062, 8x NVIDIA 2.1-2091 | RetinaNet: 8x NVIDIA 2.0-2091, 8x NVIDIA 2.1-2061, 8x NVIDIA 2.1-2091 | RNN-T: 8x NVIDIA 1.0-1060, 8x NVIDIA 2.1-2061, 8x NVIDIA 2.1-2091 | Mini Go: 8x NVIDIA 0.7-20, 8x NVIDIA 2.1-2063, 8x NVIDIA 2.1-2091 | 3D U-Net: 8x NVIDIA 1.0-1059, 8x NVIDIA 2.1-2060, 8x NVIDIA 2.1-2091
First NVIDIA A100 Tensor Core GPU results normalized for throughput due to higher accuracy requirements introduced in MLPerf Training 2.0 where applicable.
The MLPerf name and logo are trademarks. For more information, see www.mlperf.org.
In addition, in its fifth MLPerf Training, A100 continued to deliver excellent performance across the full suite of workloads, delivering up to 2.5x more performance compared to its first submission, as a result of extensive software optimizations.
This post offers a closer look at the work done by NVIDIA to deliver these results.
BERT
For this round of MLPerf, several optimizations were implemented for our BERT submission, including the use of the FP8 format and the implementation of optimizations for FP8 operations, a reduction in CPU overhead, and the application of sequence packing for small scales.
Integration with NVIDIA Transformer Engine
One of the key optimizations employed in our BERT submission in MLPerf Training v2.1 was the use of the NVIDIA Transformer Engine library. The library accelerates transformer models on NVIDIA GPUs and takes advantage of the FP8 data format supported by the NVIDIA Hopper fourth-generation Tensor Cores.
BERT FP8 inputs were used for fully connected layers, as well as for the fused multihead attention kernel that implements multihead attention in a single kernel. Using the FP8 format improves memory access times by reducing the amount of data transferred between memory and streaming multiprocessors (SMs) compared to the FP16 format.
Using the FP8 format for the inputs of matrix multiplications also takes advantage of the higher computational rates of FP8 format compared to the FP16 format on NVIDIA Hopper architecture GPUs. By taking advantage of the FP8 format, Transformer Engine accelerates the end-to-end training time by 37% compared to not using the Transformer Engine on the same hardware.
Transformer Engine abstracts away the FP8 tensor type from the user. As a result, the tensor format at the input and output of the encoder layers remains as FP16. The details of FP8 usage are handled by the Transformer Engine library inside the encoder layer.
Both E4M3 and E5M2 formats are employed for FP8, referred to as a hybrid recipe in Transformer Engine. For more information about FP8 format and recipes, see Using FP8 with Transformer Engine.
FP8 general matrix multiply layers
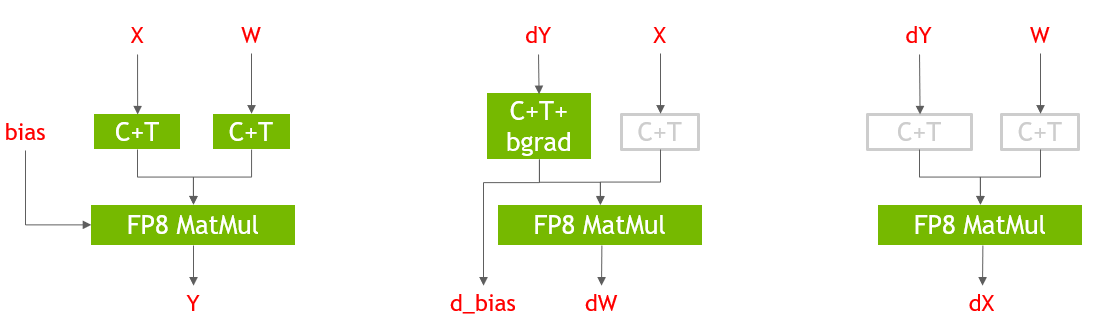
The Transformer Engine library features custom fused kernel implementations to accelerate commonly used NLP and data transformation operations.
Figure 3 shows the FP8 implementation of the forward and backward passes for the Linear layer in PyTorch. The inputs to the GEMM layers are converted to FP8 using the Cast+Transpose (C+T) fused kernel provided by the Transformer Engine library and the GEMM outputs are saved in FP16 precision. FP8 GEMM layers result in a 29% improvement in end-to-end training time. In Figure 3, the C+T operations in gray are redundant and are shown for illustrative purposes only. FP8 GEMM layers use the cuBLAS library in the backend of the Transformer Engine library.
Higher-efficiency, fused multihead attention for FP8
In this round, we implemented a different version of fused multihead attention that is more efficient for BERT use case, inspired by the FlashAttention algorithm.
This implementation does not write out the softmax output or dropout mask in the forward pass to be used in the backward pass. Instead, it recomputes the softmax output in the backward pass and uses the random number generator states directly from the forward pass to regenerate the dropout mask in the backward pass.
This approach is much more efficient, particularly when FP8 inputs and outputs are used due to reduced register pressure. It results in an 8% improvement in end-to-end time-to-train.
Minimize overhead using dataset packing
Previously, for small scales, we used an unpadding strategy to minimize the overhead that stems from varying sequence lengths and additional padding.
An alternative approach is to pack the sequences in a way such that they almost completely fill the batch matrix, making the additional padding negligible while keeping the buffer sizes static across iterations.
In our latest submission, we used a sequence packing algorithm to preprocess training data for small and medium-scale (64 GPUs or less) NVIDIA Hopper submissions. This is similar to the technique employed in previous rounds for larger scales with 1,024 GPUs and more.
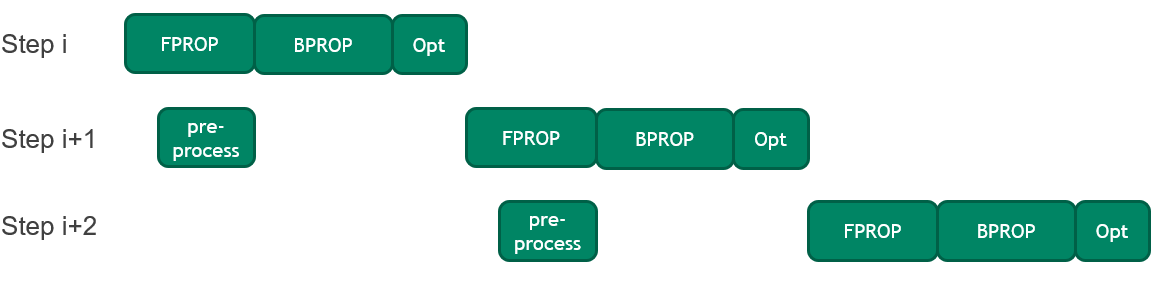
Overlap CPU preprocessing with GPU operations to improve training time
Each training step in BERT involves preprocessing the input sequences (also known as mini-batches) on the CPU before copying them to the GPU.
In this round, an optimization was introduced to pipeline the forward pass execution of the current mini-batch with preprocessing of the next mini-batch. This optimization reduces idle GPU time, which is especially important as GPU execution gets faster. It resulted in a 2% improvement in end-to-end training time.
New hyperparameter and batch sizes optimized for H100
With the new H100 Tensor Core GPUs based on the NVIDIA Hopper architecture, throughput scales extremely well with growing local batch sizes. As a result, we increased per-accelerator batch sizes and optimized the training hyperparameters accordingly.
ResNet-50
In this round of MLPerf, we extended the fusion of convolution and memory-bound operations beyond epilog fusions and improved the performance of the pooling operation.
Conv-BN fprop Fusion
The ResNet-50 model consists of a Conv->BN->Relu->Conv->BN->ReLu pattern, resulting in idle Tensor Cores when memory-bound normalization layers are being executed.
In MLPerf Training 2.1, BatchNorm was split into BatchNorm Stats calculation and BatchNorm Apply.
The programmability of NVIDIA GPUs enabled us to fuse the stats calculation in the epilog of the previous convolution, and fuse Apply in the mainloop of the next convolution.
For weight gradients calculation, however, this means the input must be recomputed by fusing BatchNorm Apply and ReLu in the wgrad. With new, high-performance kernels in cuDNN, this feature yielded a 4.2% end-to-end speedup for small scales.
Faster pooling operations
The ResNet-50 model employs maxPool and AvgPool operations in the stem and classifier blocks. By using the new graph API in cuDNN and taking advantage of the higher DRAM bandwidth in the NVIDIA H100 Tensor Core GPU, we sped up the pooling operations by over 3x. This resulted in a speedup of over 3% in MLPerf Training v2.1.
RetinaNet
The major optimization for RetinaNet in this round of MLPerf was improving score computation in the NVCOCO library to remove CPU bottlenecks for the max-scale submission. Additional optimizations include new fusions, extending the reach of CUDA Graphs for reducing CPU overheads, and using the DALI library to improve data preprocessing in the evaluation phase.
NVCOCO: Accelerating scoring
As GPU execution gets faster, the portions of the code that execute on the CPU can bottleneck performance. This is especially true at large scales where the amount of work executed per GPU is smaller.
Currently, the mAP metric computation during the evaluation phase runs on the CPU, and it was the performance bottleneck in our previous max-scale submission.
In this MLPerf round, we optimized this evaluation computation to eliminate CPU bottlenecks and enable our GPU optimizations to shine. This has particularly helped with the max-scale submission.
The C++ extensions were also further optimized in NVIDIA cocoapi. For its mAP metric computation, we improved COCO’s performance by 3x and overall 20x over the original cocoapi implementation. These optimizations mostly are focused on file I/O, memory access, and load balancing.
We replaced pybind11 with native CPython PyModules as the interface between Python and C++. By reading JSON files directly on the C++ side and interacting with the CPython pointers of NumPy objects, we eliminated deep copies that might have existed before.
Also, loop transformations, such as loop fusion and loop reordering, have significantly improved cache locality and memory access efficiency for multithreading.
We added more parallel regions in OpenMP to exploit additional parallelism and adjusted tasking schedules to better load balance across the threads.
These optimizations in the metric computation have overall resulted in a ~60% end-to-end performance improvement at the 160-node scale. Removing CPU bottlenecks from the critical path also enabled us to increase our maximum scale to 256 nodes from 160 nodes. This yields an additional ~30% reduction in the total time-to-train, despite an increase in the number of epochs required to achieve the target accuracy.
The total end-to-end speedup from the COCO optimization is 2.3x.
Extending CUDA graphs: Sync-free Adam optimizer
CUDA Graphs provides a mechanism to launch multiple GPU kernels without CPU intervention, mitigating CPU overheads.
In MLPerf Training v2.0, CUDA Graphs was used extensively in our RetinaNet submission. However, gradient scaling and the Adam optimizer step were left out of the region that was graph-captured, due to CPU-GPU synchronization in the optimizer implementation.
In this MLPerf Training v2.1 submission, the Adam optimizer was modified to achieve a sync-free operation. This enabled us to further extend the reach of CUDA graphs and reduce CPU overhead.
Additional cuDNN runtime fusion
In addition to the conv-bias-relu fusion used in the previous MLPerf submission, a conv-scale-bias-relu fusion was employed in the RetinaNet backbone by using cuDNN runtime fusion. This enabled us to avoid kernel launch latency and data movements, resulting in a 1.5% end-to-end speedup.
Using NVIDIA DALI during evaluation
The significant speedups achieved in the training passes have resulted in an increase in the proportion of the time spent on the evaluation stages.
NVIDIA DALI was previously employed during training but not during evaluation. To address the relatively slow evaluation iteration times, we used DALI to efficiently load and preprocess data.
Mask R-CNN
In this round of MLPerf, beyond improving the parallelization of different blocks of Mask R-CNN, we enabled the use of new kernel fusions and reduced the CPU overhead in training iterations.
Faster JSON interpreter
Switching from ujson to orjson reduced the loading time of the COCO 2017 annotations file by approximately 1.5 seconds.
Faster evaluation and NVCOCO optimizations
We used the NVCOCO improvements explained for RetinaNet to reduce the end-to-end time for all Mask R-CNN configurations by about 2 seconds. On average, these optimizations reduce evaluation time by approximately 2 seconds per epoch, but only the last evaluation is exposed in end-to-end time.
The optimized NVCOCO library is a drop-in replacement, making the optimizations directly available to end users.
Vectorized batched ROI Align
Region of Interest (ROI) Align performs bilinear interpolation, which requires a fair bit of math work. As this work is the same for all channels, vectorizing across the channel dimension reduced the amount of work needed by about 4x.
The way launch configurations are calculated were also changed to avoid launching more CUDA threads than needed.
Combined, these efforts improved performance for ROI Align forward propagation by about 5x.
Exposing more parallelism in model code
Mask R-CNN, like most models, incorporates many sections of code that can be executed in parallel. For example, mask-head loss calculation involves calculating a loss for multiple proposals, where each proposal loss can be calculated independently.
We achieved a 3-5% speedup by identifying such sections that can be parallelized and placing them on separate CUDA streams.
Removing more CPU-GPU syncs
In sections of the code where CUDA Graphs is not employed, the GPU kernels are launched from the CPU code. CPU code primarily performs bookkeeping tasks, such as managing memory, keeping track of pointers and indices, and so on.
If the CPU code is not fast enough, the GPU kernel finishes and sits idle before the next kernel is launched. Improving CPU performance to the point where the CPU portion of the code runs faster than the GPU portion is critical to maximizing training performance. This requires some amount of CPU run-ahead.
CPU-GPU synchronizations prevent this because they keep the CPU idle until the current GPU work completes, so removing CPU-GPU synchronizations is also critical for training performance.
We have done this in past rounds for submissions using the NVIDIA A100 Tensor Core GPU. However, the significant performance increase provided by the NVIDIA H100 Tensor Core GPU necessitated that more of these CPU-GPU synchronizations be removed.
This had a small impact on the NVIDIA A100 Tensor Core GPU results, as CPU overhead is not as pronounced for that GPU on Mask R-CNN. However, it improved performance on the H100 Tensor Core GPU by 25-30% for the 32-GPU configuration.
Runtime fusions in RPN and FPN
In previous rounds, we sped up the code by using the cudnn v8 API to perform runtime fusions for the ResNet-50 backbone of Mask R-CNN.
In this round, previous work was leveraged for RetinaNet to extend run time fusions to the RPN and FPN modules, further improving end-to-end performance by about 2%.
Boosting AI performance by 6.7x
The NVIDIA H100 GPU based on the NVIDIA Hopper architecture delivers the next large performance leap for the NVIDIA AI platform. It boosts performance by up to 6.7x compared to the first submission using the A100 GPU.
With software improvements alone, the A100 GPU demonstrated up to 2.5x more performance in this latest round compared to its debut submission, showcasing the continuous full-stack innovation delivered by the NVIDIA AI platform.
All software used for NVIDIA MLPerf submissions is available from the MLPerf repository, enabling you to reproduce our benchmark results. We constantly incorporate these cutting-edge MLPerf improvements to our deep learning framework containers. These containers are available on NGC, our software hub for GPU-optimized applications.
