This is the second post in the Accelerating IO series, which describes the architecture, components, and benefits of Magnum IO, the IO subsystem of the modern data center.
The first post in this series introduced the Magnum IO architecture and positioned it in the broader context of CUDA, CUDA-X, and vertical application domains. Of the four major components of the architecture, the first of those components, Network IO, is the subject of this post, with the following features:
- ASAP2 (Accelerated Switch and Packet Processing)–Offload the data plane and potentially the control plane.
- MPI and UCX with GPUDirect remote direct memory access (RDMA) in HPC-X–Maximize performance with CUDA awareness.
- NCCL (NVIDIA Collectives Communications Library)–Tailor to the platform and topology.
- NVSHMEM (NVIDIA OpenSHMEM)–Accelerate fine-grained, low-latency communication, integrated with computation.
The following subsections provide high-level descriptions of each of the four features. In many cases, benefits are highlighted with case studies or proof points.
NVIDIA provides a range of scalable IO solutions that are seamlessly integrated by Magnum IO:
- NVIDIA NVLink enables high-speed peer-to-peer communication between GPUs within a node.
- NVIDIA InfiniBand and Ethernet networking solutions provide a range of technologies for building scalable systems. InfiniBand and Ethernet support up to data speeds of 200 gigabits per second end to end with the lowest latencies in the industry.
- RDMA is naturally supported on InfiniBand, and is available via RoCE (RDMA over Converged Ethernet). RDMA enables a direct, zero-copy data path between memories in different nodes, which boosts efficiency and avoids CPU overhead.
- Hardware acceleration is provided through both network adapters (also referred to as HCAs for InfiniBand or NICs for Ethernet) and switches.
- Communication libraries like CUDA-aware MPI, UCX (unified communication X), NCCL, and NVSHMEM draw on various technologies from the GPUDirect family. These are described later in this post.
ASAP2
Packet processing is one of the facets of Magnum IO’s Network IO component, and ASAP2 is the feature that enhances switch and packet processing on Ethernet. Network administrators set policies to govern forwarding, dropping, and redirecting packets flowing through the network. The agent that manages these policies is the control plane and the agent that implements them is the data plane.
Software-defined networking (SDN) is a popular technique for setting control plane policies. SDN acts as a virtual software switch or router, working in conjunction with physical networking devices. It can flexibly adjust to the data center’s demands on the fly, and easily perform tasks such as load balancing devices across services and adjusting the network’s architecture automatically to optimize performance. It can also enhance security by implementing distributed connection-aware firewalls. SDN policies get encoded in a match/action table.
The processing for the control and data planes could all be done on the CPU. But that would use an expensive resource to do something that could be offloaded. There are two levels of offloading available:
- Just the data plane. The ConnectX family of network adapters can implement the decisions in the match/action table, thus offloading the CPU and boosting performance and dropping CPU utilization.
- Both the control plane and data plane. The BlueField data processing unit (DPU) family of SmartNICs has a programmable Arm CPU and additional accelerating hardware. It can manage both the SDN control plane and the data plane.
Offloading data steering and security from the CPU into the network boosts efficiency, adds control, and isolates those functions from malicious or buggy applications on the CPU that could disrupt the smooth flow of data through the network or corrupt adjacent applications. The set of features that accelerate switch and packet processing are known as ASAP2. Magnum IO’s ASAP2 features boost performance, enable isolation by shifting work to a more appropriate part of the hierarchy, and provide a flexible abstraction for lower-level management.
MPI and UCX with GPUDirect RDMA in HPC-X
Communication stacks enable scalable applications to achieve performance close to peak hardware capabilities across a wide range of configurations. This includes clusters optimized for deep learning and HPC like the NVIDIA DGX line of products as well as more general purpose, cloud-based configurations that are suitable for data science workloads. These configurations can have several underlying communication mechanisms, including shared memory CPU socket to socket transports, TCP/IP, InfiniBand, NVLink, and PCIe. In addition, there are multiple software mechanisms and technologies that must be used efficiently to make full use of the underlying network hardware. Communication libraries have the job of hiding these complexities and providing consistent and highly scalable APIs that are portable both intra-node and inter-node across a broad range of systems. Magnum IO provides several communication libraries that meet the needs of different application usage models and have been made CUDA-aware and optimized for systems with NVIDIA GPUs.
UCX
The Unified Communication X (UCX) library is a community-driven, open-source approach that implements communication and associated APIs over multiple transports and device generations. UCX development is managed by the UCF consortium and includes contributions from NVIDIA. The idea is that you can flexibly leverage CPU or GPU buffers, InfiniBand, Ethernet/RoCE, GPUDirect RDMA, or plugins like InfiniBand MPI Tag Matching for in-network computing based on your infrastructure. The objective of Magnum IO is to enable IO acceleration for all data center users.
UCX is a flexible abstraction that allows multiple programming models and runtime systems to leverage all these network capabilities and mechanisms of the platform through a common but broad API. UCX can choose what it thinks are best transports by default, and you can override defaults to exercise greater control over how to achieve highest performance on their infrastructure if you wish. After UCX itself is made CUDA-aware, layer higher-level communications interfaces on top of UCX to reap the enabling benefits. UCX is used as an underlying conduit to accelerate GPU workloads underneath well-known MPI implementations such Open MPI, MPICH, or commercial offerings that use UCX. New initiatives such as UCX-Py and Spark-RAPIDS directly use UCX APIs to accelerate data science workloads.
NVIDIA Mellanox HPC-X is a comprehensive software package offering MPI, UCX, and other libraries such as SHARP for performing at supercomputer scale. It offers HPC developers key performance features such as multiple transport support, management of HCA/switch hardware resources, efficient memory management, and configurable hierarchical collective operations. It also enables monitoring system statistics such as wallclock time, communication volume, packet loss, and file IO. With its rich set of features and proven track record, HPC-X enables Magnum IO users a flexible programmable interface to manage communications and achieve highest reliability, scalability, and performance on Mellanox switch hardware.
Underlying technologies
There are several underlying technologies that contribute to best performance in CUDA-aware IO middleware. There are two kinds of scaling at play: scale up and scale out. The number of nodes increases over time, and large clusters like Summit are an example. This increases the demand for inter-node communication performance. The number of GPUs per node is also increasing; eight GPUs per node is now common. This increases the criticality of intra-node communication. With increased communication volume on these two fronts, low-latency and high-bandwidth between GPUs are realized through three technologies:
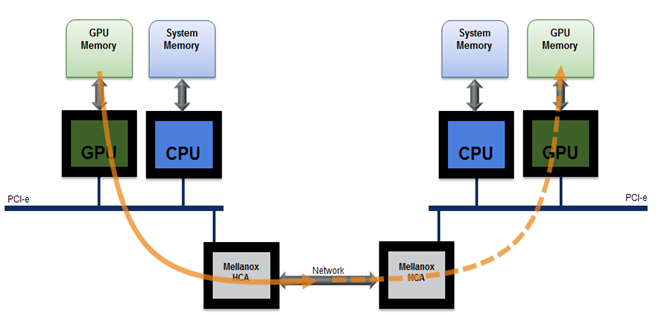
- GPUDirect RDMA (GDR) performs zero-copy data movement between remote GPU memory and local GPU memory without any intermediate copies, shown in Figure 1. This involves opening a window to be able to directly address GPU memory by the network adapter’s DMA engine.
- GPUDirect Copy uses a similar mechanism to move data back and forth from the CPU.
- GPUDirect P2P, for peer-to-peer, enables GPUs to access each other’s memories with loads, stores, and atomic memory operations, over either NVLink or PCIe.
UCX uses all three of these capabilities where supported.
The other part of CUDA awareness is path selection and staging through intermediate pinned buffers. On some CPU platforms, the direct PCIe path between the GPU and the network adapter may be functional but unable to provide good performance. For more information, see Benchmarking GPUDirect RDMA on Modern Server Platforms. Similarly, on some platforms, direct access may not be functional between GPUs or between GPU and the network adapter. In these cases, UCX can efficiently move data by pipelining copies through intermediate buffers on the CPU.
Evaluation of CUDA-aware UCX
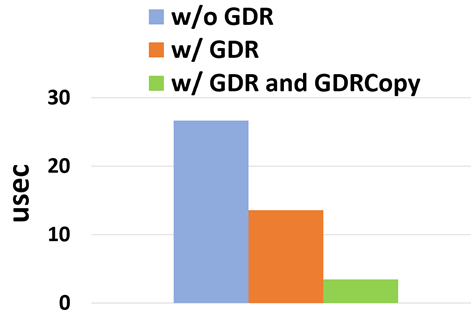
GPU-to-GPU transfers over the network were evaluated on a portion of Selene with Open MPI using the ping-pong and multi-pair bandwidth tests from the OSU Micro-Benchmarks. Figure 2 shows the latency results and Figure 3 shows the bandwidth results. Two related technologies are used:
- GPUDirect RDMA reduces the latency of small MPI messages by avoiding costly CUDA copies through host memory at the sender. MPI send/recv, when implemented using an eager protocol, requires an additional copy from an intermediate buffer to the user buffer at the receiver.
- The GDRCopy library based on GPUDirect RDMA technology accelerates the MPI send/recv copy and reduces the GPU-GPU MPI latency to 3.4 microseconds between two nodes of the Selene supercomputer, compared to 26.6 microseconds without GPUDirect RDMA.
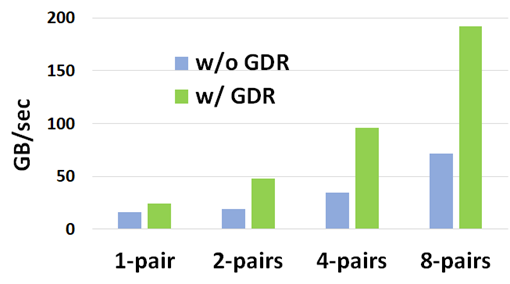
Modern server architectures like DGX-A100 match each of eight GPUs with an HDR 200 Gbps InfiniBand adapter. GPUDirect RDMA is essential to scale aggregate MPI bandwidth between nodes as applications scale to use all the GPUs on the node. Figure 3 shows how GPUDirect RDMA allows MPI bandwidth to scale up to 192 GB/sec across eight process pairs using eight network adapters (24 GB/sec per adapter), compared to 71 GB/sec without GPUDirect RDMA. The performance difference is due to PCIe and CPU memory bottlenecks when copying data through CPU memory.
HPC applications extensively use the MPI programming model. Support is in place for transparently layering UCX under a variety of MPI implementations like HPC-X, Open MPI, and MPICH. Data analytics and enterprise applications often do not use MPI, yet UCX’s interfaces are available to be used directly as a solution. Some applications have a requirement that processes or GPUs can be added to or removed from a job. UCX affords this flexibility, while MPI’s pattern of creating an enduring set of ranks that participate in communicators does not. An example of an application that prefers to scale across nodes with UCX compared MPI is RAPIDS cuDF.
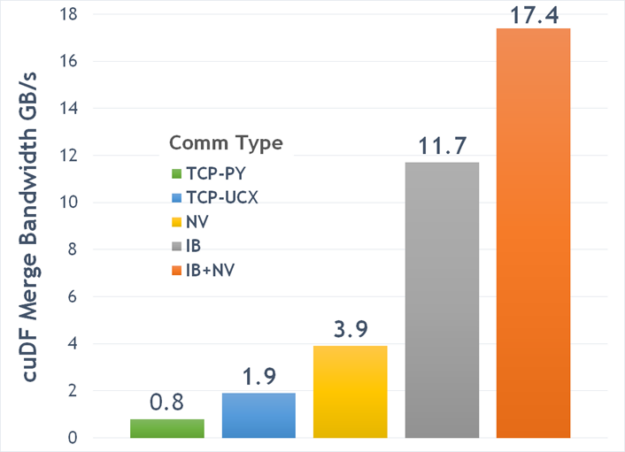
Figure 4 shows a comparison of bandwidths on different transports on DGX-1V for the cuMerge benchmark, which merges two dask-cudf dataframes with random data that’s equally distributed across eight GPUs. Python sockets (TCP-PY) had rather poor bandwidth. All of the other options used UCX: TCP (TCP-UCX), NVLink among GPUs when NVLink connections are available on the DGX-1 and CPU-CPU connections between halves where necessary (NV), InfiniBand (IB) adapters connections to a switch and back, and a hybrid of InfiniBand and NVLink to get the best of both (IB + NV). Clearly, UCX provides huge gains.
NCCL
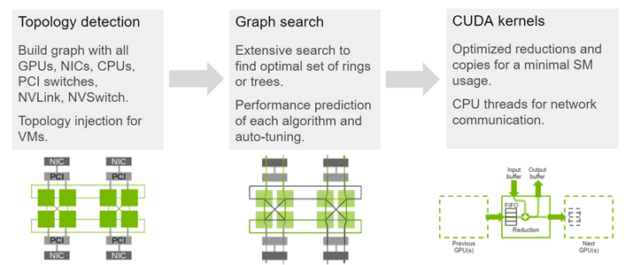
Collectives are an essential ingredient for training in deep learning. After each forward or backward propagation pass, an AllReduce operation is required to communicate partial results across the network. The NVIDIA AI libraries in CUDA-X depend on NCCL to provide a programming abstraction that is highly tuned for each platform and topology through advanced topology detection, generic path search, and algorithms optimized for NVIDIA architectures.
In addition to AllReduce, NCCL also enables model-level parallelism by implementing optimized send and receive operations that enable you to split large models across multiple GPUs. SHARP is complementary to and used by NCCL.
NCCL APIs are initiated from the CPU, but they execute on the GPU and they move or exchange data among GPU memories. The implementation can leverage NVLink to aggregate the bandwidth of multiple high-speed NICs. Figure 5 highlights the NCCL architecture. The following performance has been achieved: DGX-1 at 48 GB/s, DGX-2 at 85 GB/s, and DGX A100 at 192 GB/s.
As of version 2.7, NCCL supports point-to-point send and receive operations to cover all communication needs. This is essential to address the broader range of all communication patterns. NCCL now covers the most-used MPI primitives. It executes on the GPU, using GPU-symmetric multiprocessors, whereas MPI is all on the CPU. NCCL uses CUDA stream semantics, with a stream parameter. It has MPI-like semantics that ease the transition between MPI and NCCL. You can explicitly choose between MPI and NCCL, based on CPU/GPU and CUDA interaction. For more information about how to create an NCCL communicator from an MPI communicator, see Communicator Creation and Management Functions. Figure 6 shows API examples and graphically illustrates some point-to-point communication patterns.

NCCL can use three different algorithms to perform AllReduce operations and optimize bandwidth and efficiency in CUDA. NCCL was originally introduced in 2015 with the Ring AllReduce algorithm. Tree was introduced in NCCL 2.4 to improve performance at scale and has been tested up to 24,000 GPUs. Finally, NCCL can use in-network collective operations like SHARP when available.
NVSHMEM
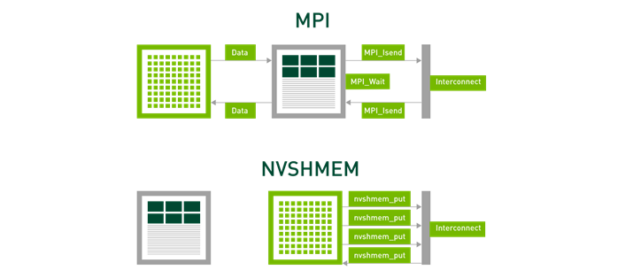
Many scalable applications perform fine-grained communication that’s tightly coupled with computation. For such applications, existing communication libraries like MPI that support communication only at kernel boundaries can incur significant kernel launch. They place communication latencies on the critical path to performance.
NVSHMEM provides a GPU-initiated communication model that enables you to perform communication directly from within running CUDA kernels. This enables you to take advantage of the GPU threading model, hide communication latencies, and reduce kernel launch overheads incurred by CPU-initiated communication models. NVSHMEM is optimized for peer-to-peer communication using NVLink, as well as remote communication using InfiniBand. Through a single, flexible API, NVSHMEM can be used efficiently for both local and remote communication.
NVIDIA embraces standards wherever possible and extends them where necessary. The OpenSHMEM standard offers a partitioned global address space (PGAS) library for one-sided communication among CPU memories. NVSHMEM extends the standard OpenSHMEM APIs with support for communication from GPU threads, blocks, and warps; direct data movement between GPU memories; and deferred execution APIs from the CPU that support CUDA Streams and CUDA Graphs.
Figure 7 shows that MPI separates out computation and communication into different phases. Even though the data can be transferred directly from GPU memory as described earlier, the send and receive actions are performed on the CPU and serialization with kernel-based computation is necessary. NVSHMEM allows computation and communication to be integrated, tightly interleaved, and concurrent compared to serialization. This is important for the fine-grained, low-latency communications that are essential for strong scaling. The NVSHMEM one-sided communication avoids the overheads of MPI’s tag matching and the generality of being able to handle wild cards. Why pay the price for something if your application doesn’t need it?
NVSHMEM 1.1.3 was just released, with the following new features:
- Add signaling API and combined put-with-signal API from OpenSHMEM 1.5 that reduce overheads for point-to-point communication patterns
- Optimized signaling APIs for peer-to-peer-connected GPUs
- Optimized performance of the nvshmem_fence function
- Optimized latency of the NVSHMEM atomics API
NVSHMEM was moved to maturity through close collaborations with several groups in DoE Labs, where use cases were worked through, bugs were reported, fixes were exercised, and performance and feature improvements were evaluated. These interactions occurred in the context of the Summit on Summit, Sierra, and Perlmutter Series of engagements between application developers seeking to do new science and CUDA platform developers solving end-to-end problems by introducing new technologies and shaping product road maps. For more information about the program, see Summit on Summit, Sierra, and Perlmutter’ Hits 2nd Anniversary of Team-Effort Problem-Solving. For more information about the NVSHMEM advantages, see Scaling Scientific Computing with NVSHMEM. Examples are taken from strong scaling on the Lassen Supercomputer and the NVIDIA DGX SuperPOD, and on productivity in Kokkos, as measured by a reduction in lines of code.
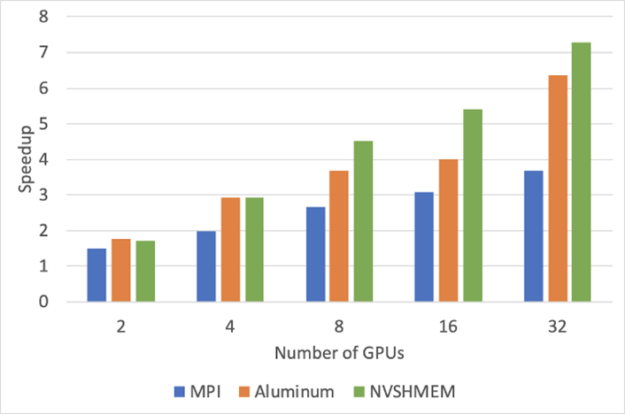
Figure 8 shows an evaluation of a convolution benchmark running in the Livermore Big Artificial Neural Net (LBANN) framework. It was executed on up to eight nodes of the Lassen system, each of which has four GPUs, on a data set of 1024×1024 images, 16 channels, and 16 3×3 filters. The LBANN framework was written to provide a generic interface for communication libraries, including MPI, Livermore’s GPU-aware Aluminum implementation. It performs CPU-side sends and receives using a stream interface, and NVSHMEM one-sided put operations. While Aluminum consistently provides more speedup relative to a single GPU than MPI in this experiment, the NVSHMEM lower overheads and tighter integration of computation and communication always win.
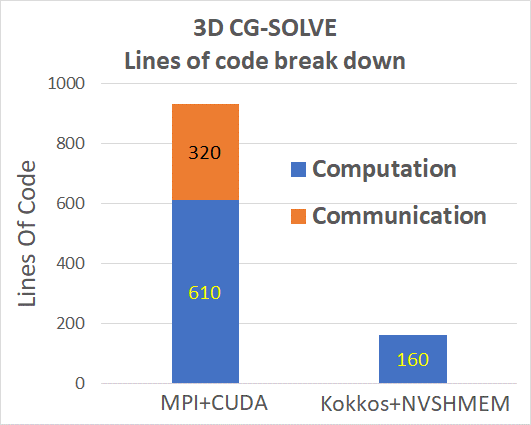
A conjugate gradient solver is a stencil code that performs a matrix-vector multiplication and accesses memory in a mix of each node and partitions spread across many nodes. The implementation option that provides maximal performance involves lots of complexity, as measured by many lines of code (LOC). In that option, which requires upwards of 1,000 LOC, communication and computation are distinct but complex strategies are used to overlap them. The Kokkos implementation that uses NVSHMEM underneath integrates communication and computation in under 200 LOC. Figure 9 shows the nearly 6x improvement in LOC. Kokkos architects suggest that the performance level achieved through Kokkos’ natural support for the distributed, shared array models for which NVSHMEM is a good fit. It offers a reasonable productivity trade-off for GPU-GPU communication within the node. New strategies that involve communication aggregation and caching are under investigation for cross-node communications in the context of Kokkos remote spaces.
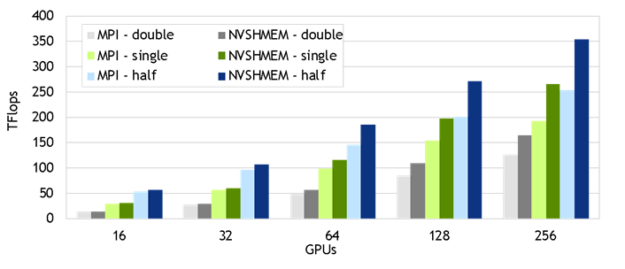
Our most recent NVSHMEM results were gathered for the Wilson-Dslash operator mini-app in the QUDA library on the Selene DGX SuperPOD. Quantum chromodynamics (QCD) is a theory formulated in 4D: space and time. QUDA solves the discretized version (Lattice QCD). A 643 x 128 global problem size was used to demonstrate strong scaling in four dimensions. The NVSHMEM calls from inside GPU kernels were encapsulated inside the QUDA library. The NVSHMEM-based implementation of QUDA should be released shortly, so that you can achieve gains like the 1.30-1.46x speedups from NVSHMEM over MPI shown in Figure 10. These gains come from fusing the boundary communications along the four dimensions with in-kernel computation. This enables concurrency of packing, transfer, unpacking, and computation within the same kernel and avoids CPU-GPU synchronization.
Support for teams and team-based collectives is coming soon. Teams enable you to partition NVSHMEM processing elements (PEs), like MPI ranks, into application-defined groups. Teams also introduce a new and more convenient collective communication API that can enable new performance optimizations for collective communication. Teams define a communication scope, enabling application developers to more naturally express data exchange among team members using either point-to-point or collective communication. For more information about the OpenSHMEM teams API, see Designing, Implementing, and Evaluating the Upcoming OpenSHMEM Teams API.
Summary
Providing flexible abstractions and highly tuned implementations of Network IO is fundamental to enabling efficient data sharing across the data center. In this post, we’ve illustrated technologies that relate to moving data among GPUs over PCIe and NVLink, between the CPU and GPU, and among GPUs reached using network adapters. Data access, movement, and management are provided underneath the variety of programming interfaces that users prefer, including MPI, UCX, NCCL, and NVSHMEM. We’ve provided concrete examples of multi-X performance improvement underneath this range of interfaces on various platforms.
For more information, see the following two GTC Fall 2020 talks:
- Magnum IO: The IO Subsystem for the Modern, Accelerated Data Center
- In-Network Computing: Accelerating scientific computing and deep learning applications
For more information about the programming interfaces discussed in this post, see the following resources:
- NVSHMEM 1.1.3, just released in September 2020, brings new signaling functionalities to one-sided GPU-GPU data transfers. Download and try it!
- NCCL 2.7.8, updated in July of 2020, includes support for point-to-point transfers, which also enable a broader set of collectives like
all_gathervandall_scatterv.
NVIDIA thrives on solving end-to-end problems that lead to groundbreaking solutions. We have an established track record of connecting CUDA platform developers with application developers who bring forward requirements and high-quality reproducers. Both bring challenging problems, developing new technologies, and revised roadmaps to further our collaboration. We invite you to engage more deeply with us to do our life’s work in new science!
