
Supercomputers are significant investments. However they are extremely valuable tools for researchers and scientists. To effectively and securely share the computational might of these data centers, NVIDIA introduced the Cloud-Native Supercomputing architecture. It combines bare metal performance, multitenancy, and performance isolation for supercomputing.
Magnum IO, the I/O subsystem for data centers, introduces new enhancements necessary to accelerate I/O and communications supporting multitenant data centers. We call these enhancements Magnum IO for Cloud-Native Supercomputing architecture.
They are delivered by the NVIDIA Quantum-2 InfiniBand platform, which includes the NVIDIA Quantum-2 switch family, BlueField-3 DPUs and ConnectX-7 network adapters.
What are the challenges of this evolutionary environment?
GPU-based high performance computing has been transforming science and augmenting experimentation with machine learning and simulation. The GPUs running these deep-learning frameworks and simulation tools can consume petabytes of data and cause congestion and bottlenecks across the data center. Complicating things further, multiple instances of these applications running at the same time across a shared supercomputing infrastructure adversely affect each applications performance, resulting in unpredictable run-times.
Magnum IO for Cloud-Native Supercomputing Architecture features new and improved capabilities to mitigate the negative impact on end-user’s performance running in a multitenant environment. It delivers deterministic levels of performance, as if their application is the only one running on the network.
Third generation of NVIDIA SHARP
Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) technology improves the performance of MPI operations by offloading collective operations from the host CPU to the switch network by eliminating the need to send data multiple times between endpoints. This approach decreases the amount of data traversing the network as aggregation nodes are reached, and dramatically reduces the MPI operations time.
Implementing collective communication algorithms in the network also has additional benefits, such as freeing up valuable CPU resources for computation rather than using them to process communication.
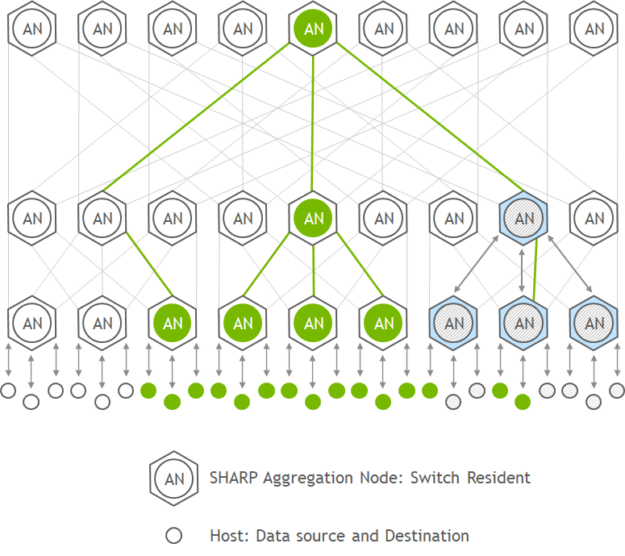
The recently announced NVIDIA Quantum-2 InfiniBand switch provides virtually unlimited scalability for large data aggregation through the network. With support for unlimited small message reductions and multiple large message reductions flows per switch, multiple tenants running applications across a shared system can now leverage the full benefits of SHARP.
Watch the In-Network Computing with NVIDIA SHARP Video.
Performance isolation
Multitenant supercomputing involves many user applications running on shared infrastructure, potentially overlapping use of physical servers, storage, networks, and the I/O traffic patterns these applications generate.
NVIDIA Quantum InfiniBand manages network congestion when it is detected and exercises controls to reduce it at the source. But with multitenancy, user applications may be unaware of indiscriminate interference with neighboring application traffic, so isolation is required to deliver expected performance levels.
With the latest NVIDIA Quantum-2 InfiniBand platform and Magnum IO, innovative proactive monitoring and congestion management delivers the needed traffic isolation. This nearly eliminates performance jitter, and ensuring predictive performance expected as if the application is being run on a dedicated system.
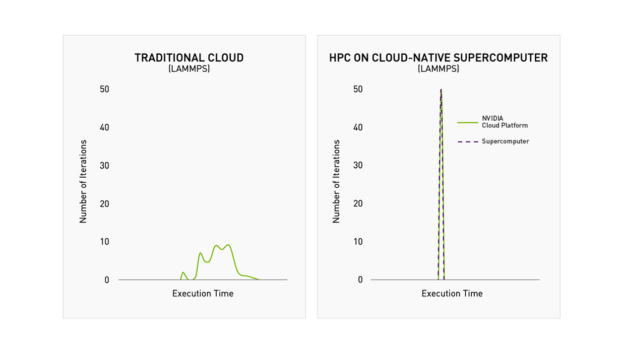
Purpose built for secure, multitenant, bare-metal performance
NVIDIA Cloud-Native Supercomputing architecture uses Magnum IO to bring together maximum performance, security, and orchestration in a multitenant environment.
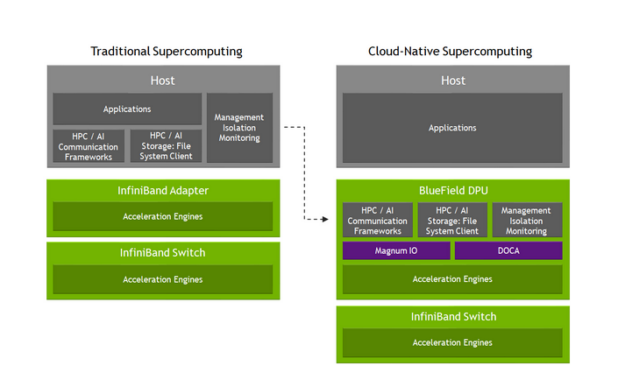
Another core element that enables this architecture transition is the data processing unit (DPU), also known as BlueField. As a fully integrated data center-on-a-chip platform, BlueField offloads and manages data center infrastructure instead of the host processor, enabling security and orchestration of the supercomputer.
BlueField can also provide additional offloads of the communication frameworks, yielding 100% communication-computation overlap while achieving an exceptional 44% performance increase for MPI_Alltoall and a 36% performance increase for MPI_iAllgather. When combined with the latest advancements of NVIDIA Quantum-2, this architecture showcases performance isolation for bare-metal performance, in a secure multinode architecture.
Magnum IO removes I/O bottlenecks and exposes the latest in hardware-level acceleration engines, in-network computing, and congestion control that is necessary to support today’s multitenant data centers with bare-metal performance.
For more information, see the following resources:
