NVIDIA GPUDirect RDMA is a technology which enables a direct path for data exchange between the GPU and third-party peer devices using standard features of PCI Express. Examples of third-party devices include network interfaces, video acquisition devices, storage adapters, and medical equipment. Enabled on Tesla and Quadro-class GPUs, GPUDirect RDMA relies on the ability of NVIDIA GPUs to expose portions of device memory on a PCI Express Base Address Register region (BAR. See this white paper for more technical details).
Both Open MPI and MVAPICH2 now support GPUDirect RDMA, exposed via CUDA-aware MPI. Since January 2014 the Mellanox Infiniband software stack has supported GPUDirect RDMA on Mellanox ConnectX-3 and Connect-IB devices.
This post is a detailed look at the performance obtainable with available hardware platforms. The main audience for this post is designers and users of GPU-accelerated clusters employing CUDA-aware MPI, and architects and designers of GPU-accelerated low-latency systems, such as in healthcare, aviation, and high-energy physics. It is also complementary to a recent post (Exploring the PCIe Bus Routes) by Cirrascale.
Though the details may change in future hardware, this post suggests expected levels of performance and gives useful hints for performance verification.
Infiniband
Infiniband (IB) is a high-performance low-latency interconnection network commonly employed in High-Performance Computing (HPC). The IB standard specifies different link speed grades, such as QDR (40Gb/s) and FDR (56Gb/s). IB network interfaces support sophisticated hardware capabilities, like RDMA, and a variety of communication APIs, like IB Verbs which is widely used in MPI implementations. For example, thanks to RDMA, an IB network interface can access the memory of remote nodes without any involvement of the remote CPU (one-sided communication).
Benchmarks
As we are interested in the low-level performance of our platforms, we used three IB Verbs-level benchmark programs. For latency we used ibv_ud_pingpong from libibverbs-1.1.7, while for bandwidth we adopted ib_rdma_bw from perftest-1.3.0. The former uses the IBV_WR_SEND primitive and the UD protocol; the latter the IBV_WR_RDMA_WRITE primitive and the RC protocol. Those test programs have been properly modified both to target GPU memory and take advantage of GPUDirect RDMA. We also employed a modified version of ib_write_bw, out of perfest-2.0, to exploit the full peak performance of the PCIe x16 Gen3 link on the Connect-IB HCA. The end of this post gives the details of the hardware platforms and the software we used.
Results
In the following we employed 64KB and 4B messages, respectively, for bandwidth and latency, with 1000 iterations. We performed our tests on two cluster nodes at a time, connected by cables to an IB switch. We used a single rail unless otherwise stated. GPU ECC is on.
In general, the source and destination memory can be either host or GPU memory. Due to the design of the latency test, it is not possible to distinguish the GPU-to-Host from the Host-to-GPU latency. As a reference, on our platform N.2 (SYS-1027GR-TRF), the Host-to-Host latency measured with ibv_ud_pingpong is 1.3us. In the diagrams below, SYSMEM is the RAM memory attached to a socket, i.e. directly connected to the processor, while device memory is not explicitly shown.
I) Host memory to GPU memory
In this case, on the transmitter (TX) node, the IB card is fetching data from a host memory buffer. The IB card on the receiver (RX) node is placing the incoming data on the GPU memory. When writing on GPU memory, the bandwidth reaches its peak FDR (56Gb/s) value. Latency is 1.7μs, roughly 0.5μs worse than the host-to-host case. We ascribe this effect to the additional latency of the data path involving the GPU memory.
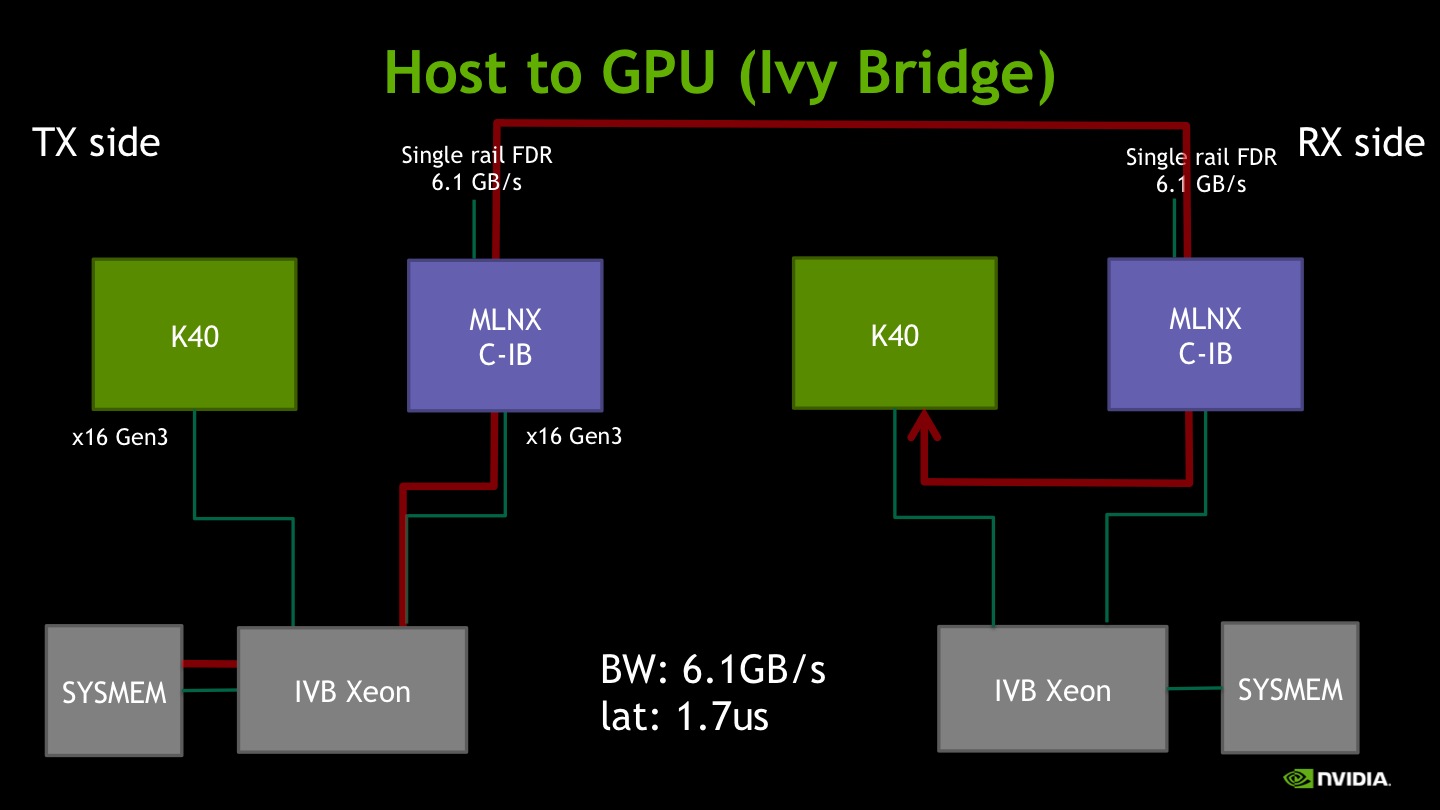
As the measured bandwidth is equal to the IB FDR peak (6.1GB/s), we also tested the dual-rail performance obtaining 9.8GB/s (vs 12.3GB/s in the Host-to-Host case). So writing to GPU memory from the IB HCA shows 20% less peak bandwidth than writing to host memory. This reveals an architectural hardware limit of the Ivy Bridge Xeon as demonstrated by the experiments with platform N.1 based on the PCIe switch in Section VI.
II) GPU memory to Host memory
When testing transmission from GPU memory, the bandwidth looks limited to 3.4GB/s, well away from the FDR peak (6.1GB/s). It is possible to gain an additional 10% improvement, up to 3.7GB/s, by boosting the clock of the K40 to 875MHz:
$ sudo nvidia-smi -i 0 -ac 3004,875We believe that the PCIe host interface integrated into the CPU is restricting the number of in-flight transactions. If there are not enough outstanding transactions the read bandwidth becomes latency limited. By increasing the GPU clock the overall path latency is reduced and thus improves the bandwidth.
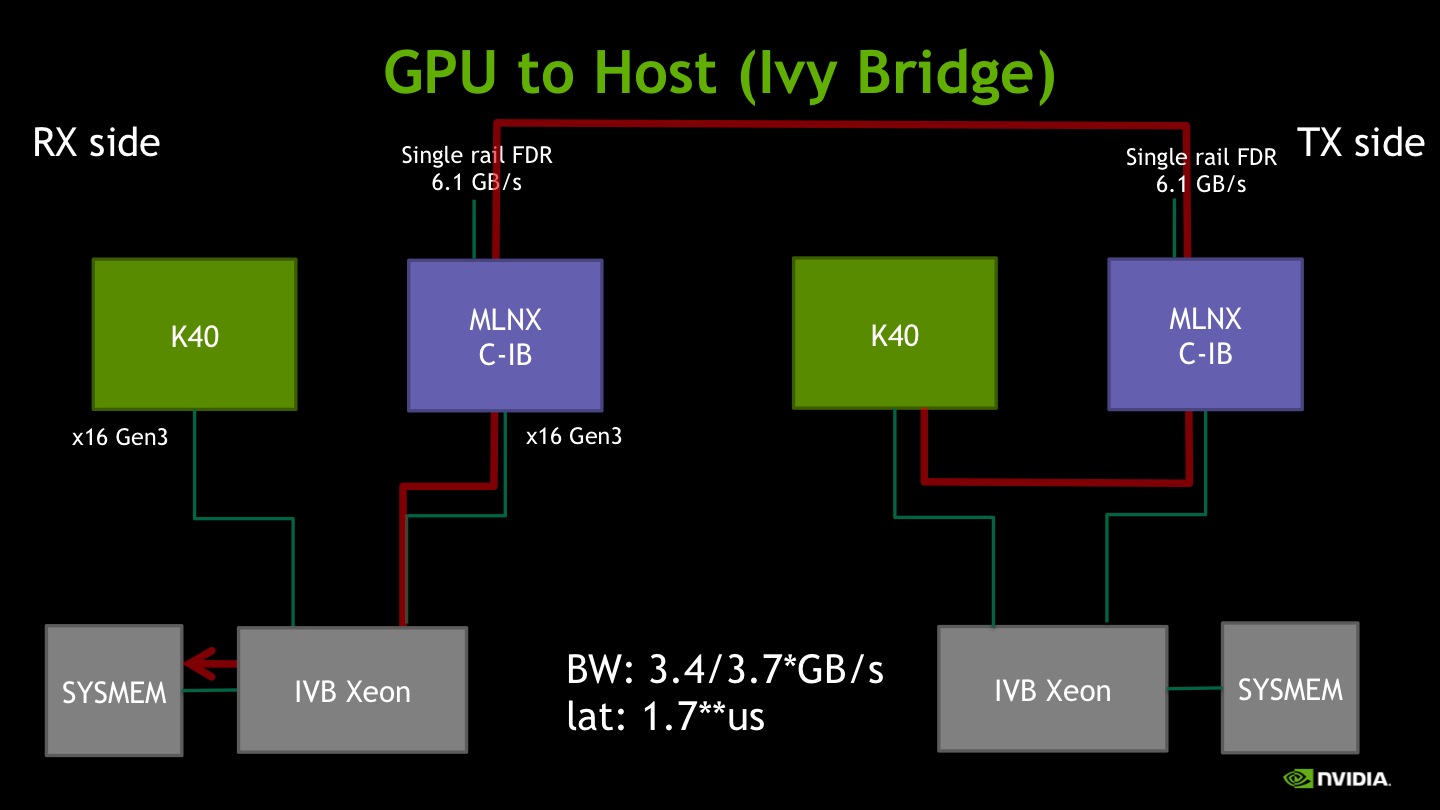
As stated previously, the latency obtained is the same as in the Host-to-GPU case due to the design of the test.
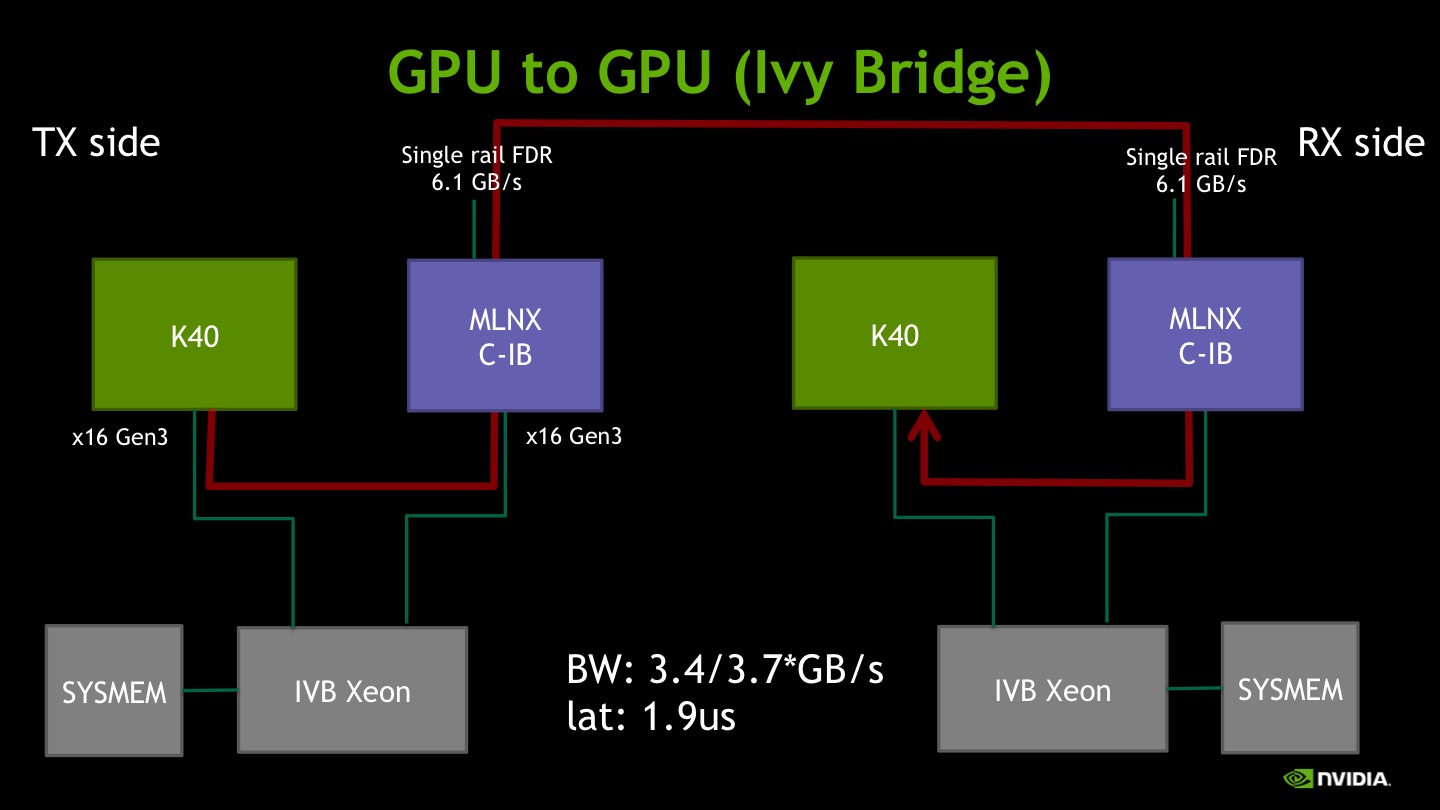
III) GPU memory to GPU memory
This test uses GPU memory as both the target and the destination. Bandwidth is the same as in the previous experiment, suggesting that writing to GPU memory does not show additional bottlenecks. Latency increases somewhat: a possible explanation is that reading GPU memory incurs an additional latency with respect to host memory, and that the ping-pong test accesses GPU memory twice, instead of just once as in the previous two cases.
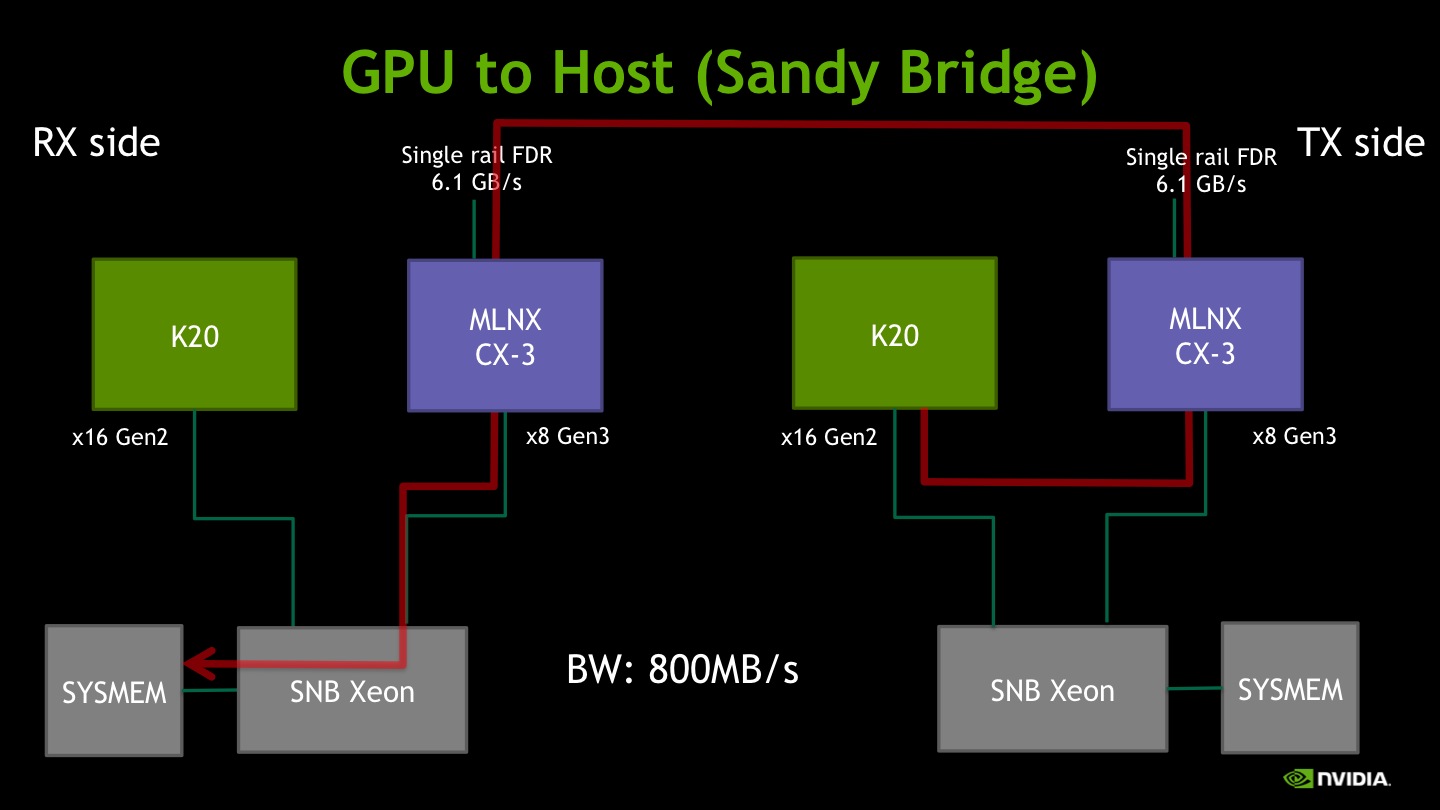
IV) Sandy Bridge Xeon
Testing the previous generation platform, the peer-to-peer reading bandwidth seems even more limited, in this case around 800MB/s. For more extensive benchmarking of Sandy Bridge and Westmere platforms, please refer to this paper.
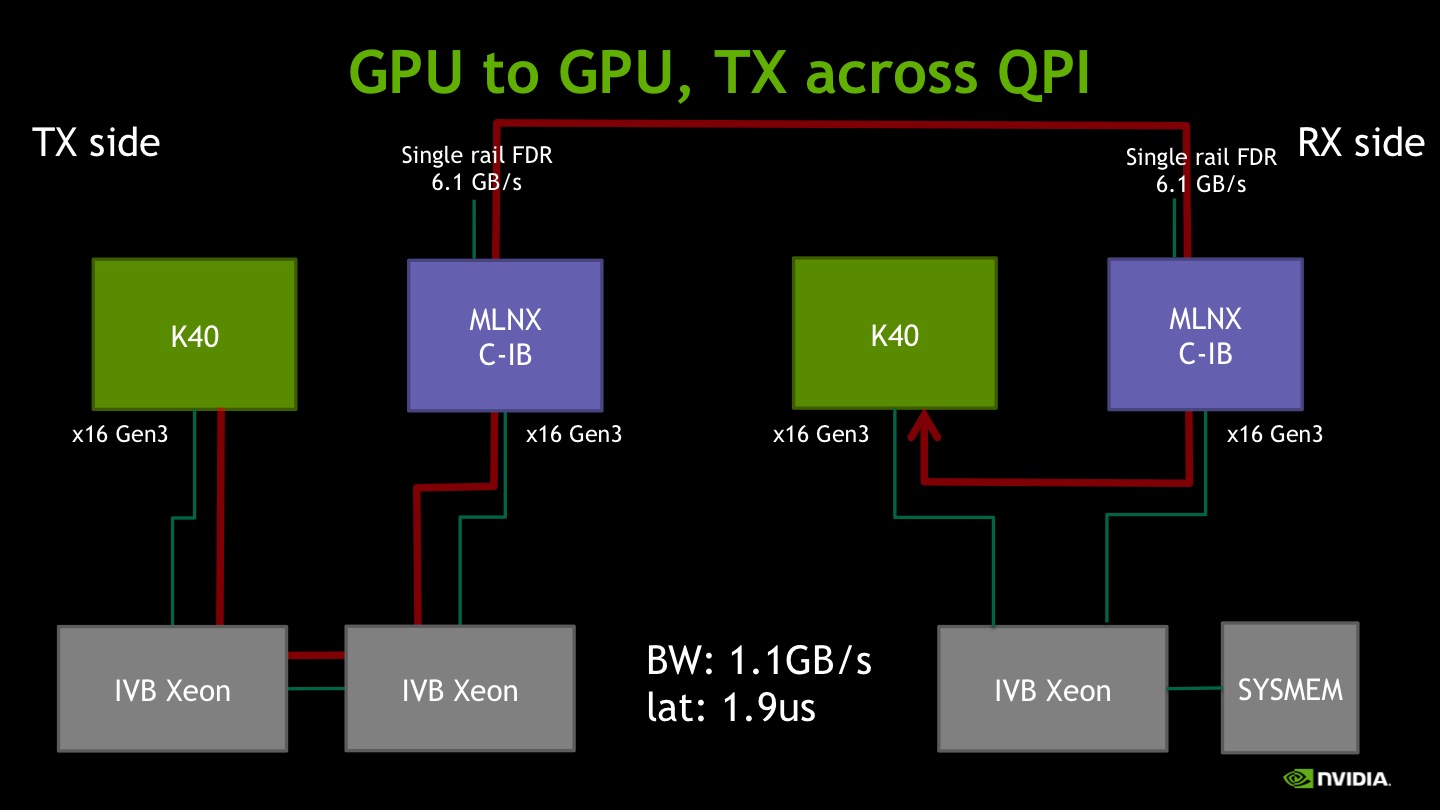
V) Inter-socket traffic
In modern dual-socket cluster nodes, it is common to have one Infiniband adapter and one GPU sharing a socket, and a second GPU attached to the other socket. The aim of the next two experiments is to assess the available performance when the Infiniband adapter accesses the second GPU. In the first case, the transmitting node fetches data from GPU memory crossing the inter-socket QPI bus. More specifically, the GPU board is in a slot that connects to one processor socket, while the IB adapter slot connects to the other socket. The observed bandwidth is roughly 1.1GB/s while the latency is similar to the previous case.
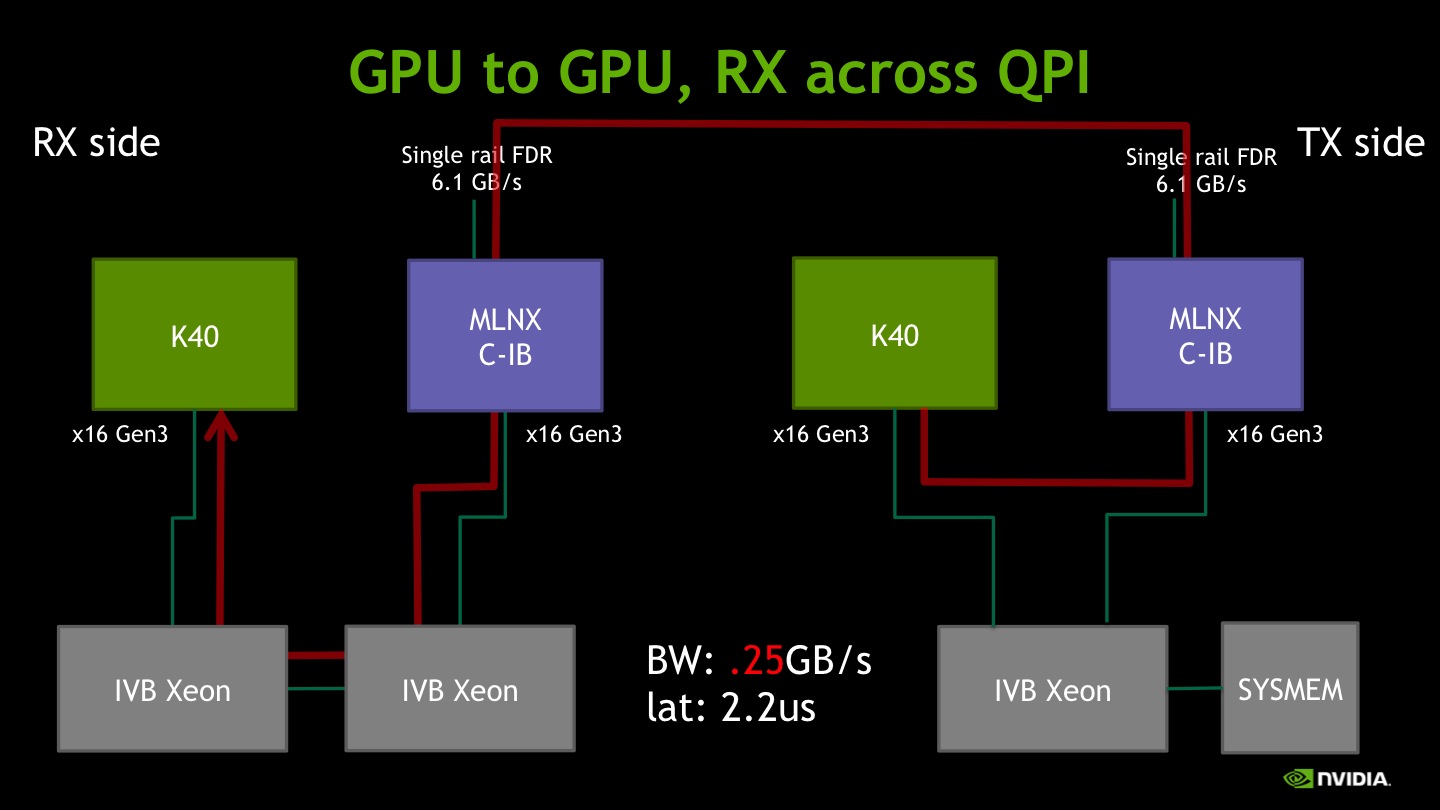
The reversed data path, where the IB card is pushing data toward the GPU across the QPI bus, shows even more limitations with 250MB/s of peak performance. In this case, even latency is somewhat affected, though by a lesser extent.
VI) PCIe switch
Finally we switch to platform N.1, where the GPU and the IB adapter are mounted on a riser-card and are connected by a PCIe switch (Avago Technologies, formerly PLX).
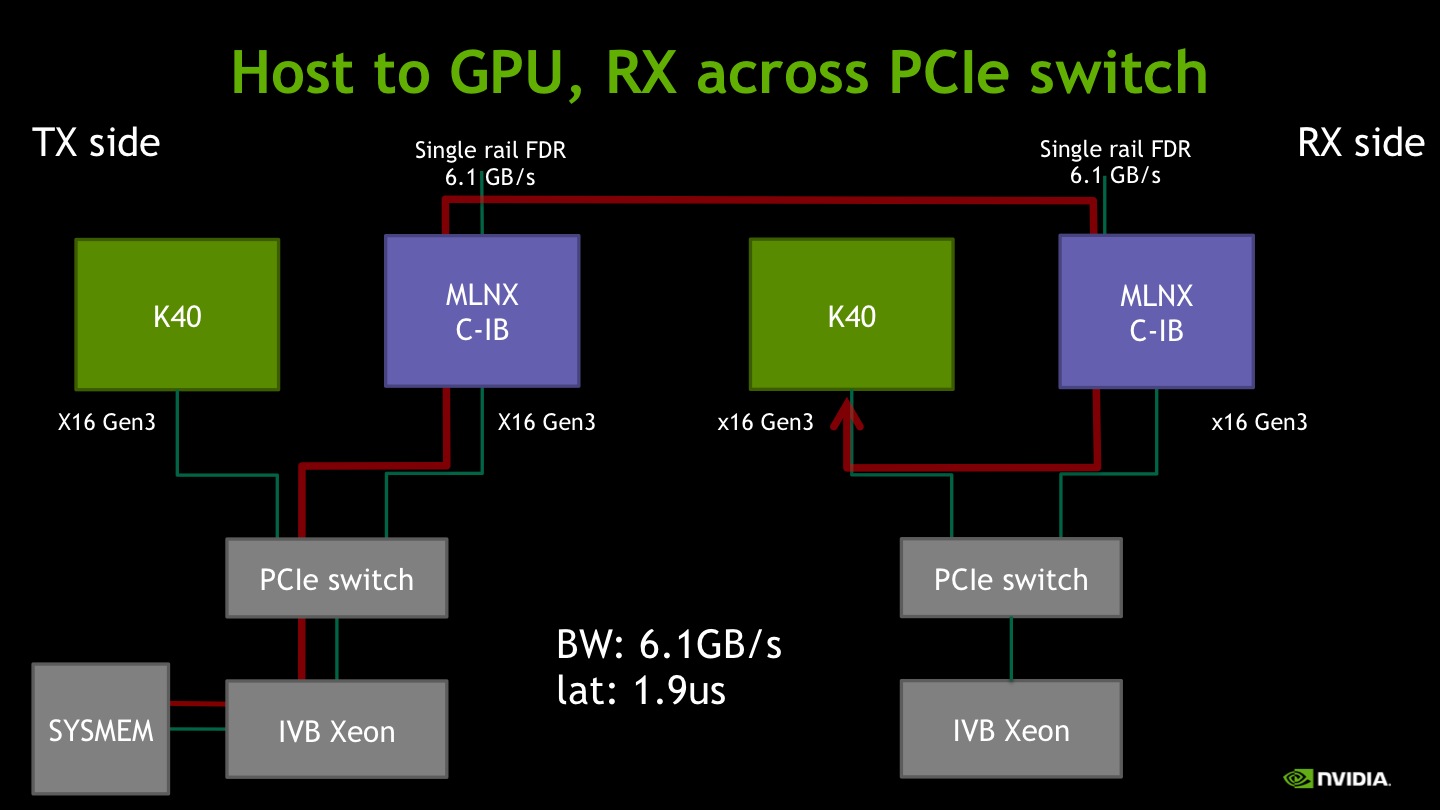
When the source is host memory and the destination is GPU memory, the observed bandwidth is in excess of 6GB/s, close to the FDR peak. Latency is higher than I) and II), probably because on the transmission side the presence of the PCIe switch introduces more overhead on the path to the host memory.
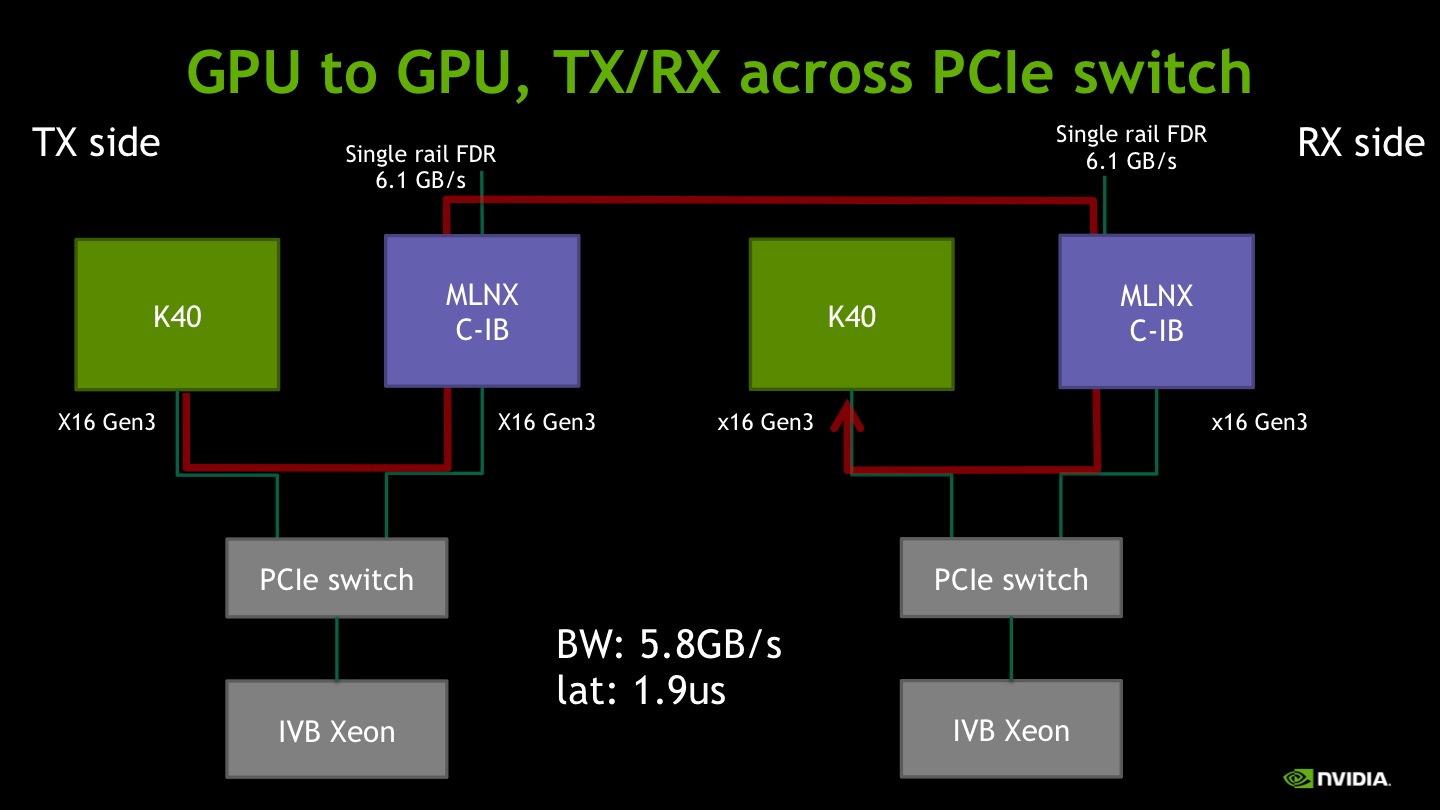
When GPU memory is used on both sides, we observe a small decrease of the bandwidth.
Still, a question remains: is 5.8 GB/s the best bandwidth we can get out of the Tesla K40? More specifically, is it limited by the PLX internal design, the GPU design or by the IB HCA ability to pump enough data out of the GPU? To answer this question we used the ib_write_bw test in dual-rail mode, which is able to reach the PCIe X16 Gen3 peak bandwidth of 12.3GB/s in host-to-host experiments on the same platform. First we benchmark the host-to-GPU case, to get rid of any effect limiting the read bandwidth. We get 11.6GB/s which is close but not equal to the peak. This might be due either to the GPU design or to the PCIe switch somehow limiting the peer-to-peer traffic between two downstream ports.

Then we benchmark the GPU-to-GPU case.
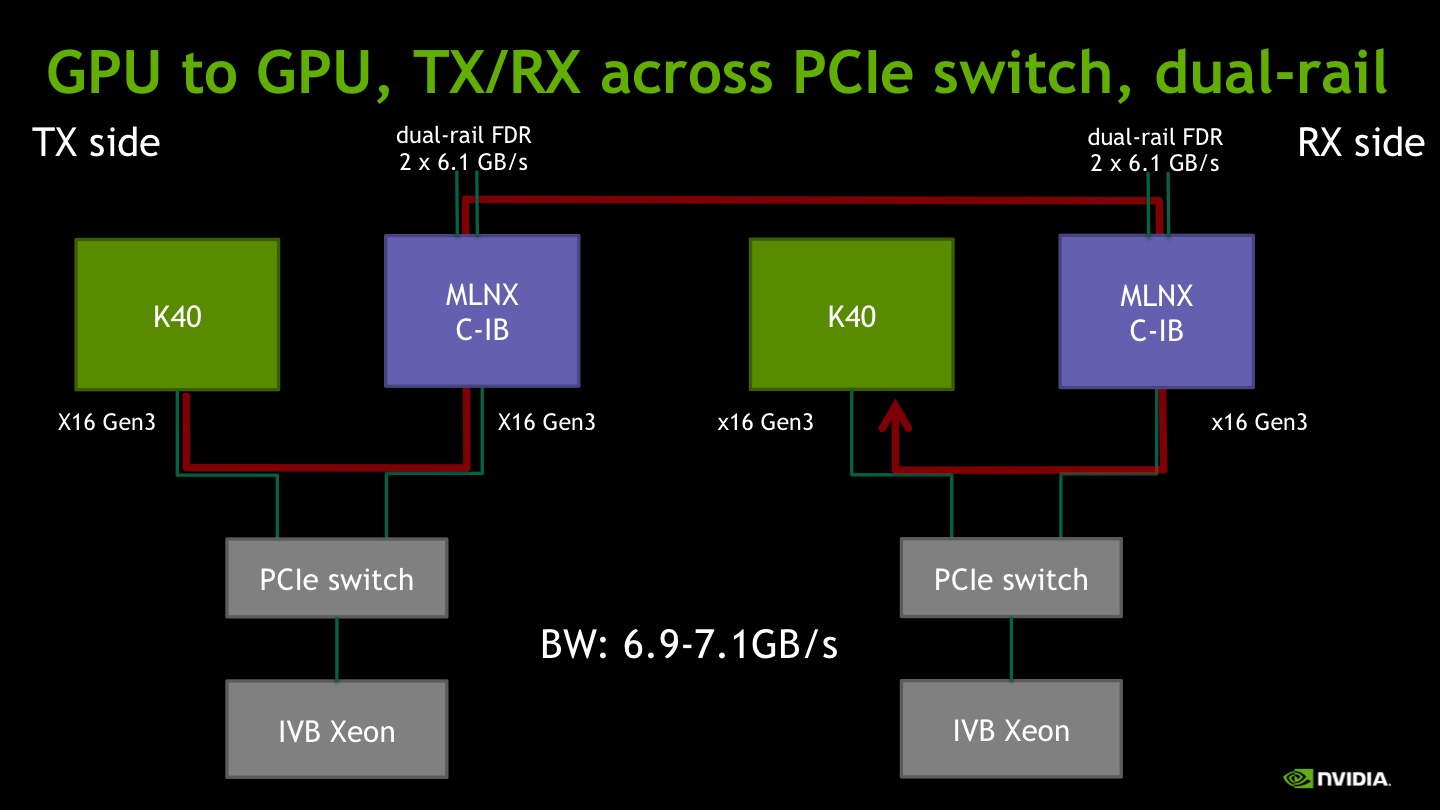
The observed average bandwidth fluctuates between 6.9 and 7.1GB/s, while peak bandwidth reaches as high as 7.4GB/s, depending on the message size. We obtained the same results in the GPU-to-Host case.
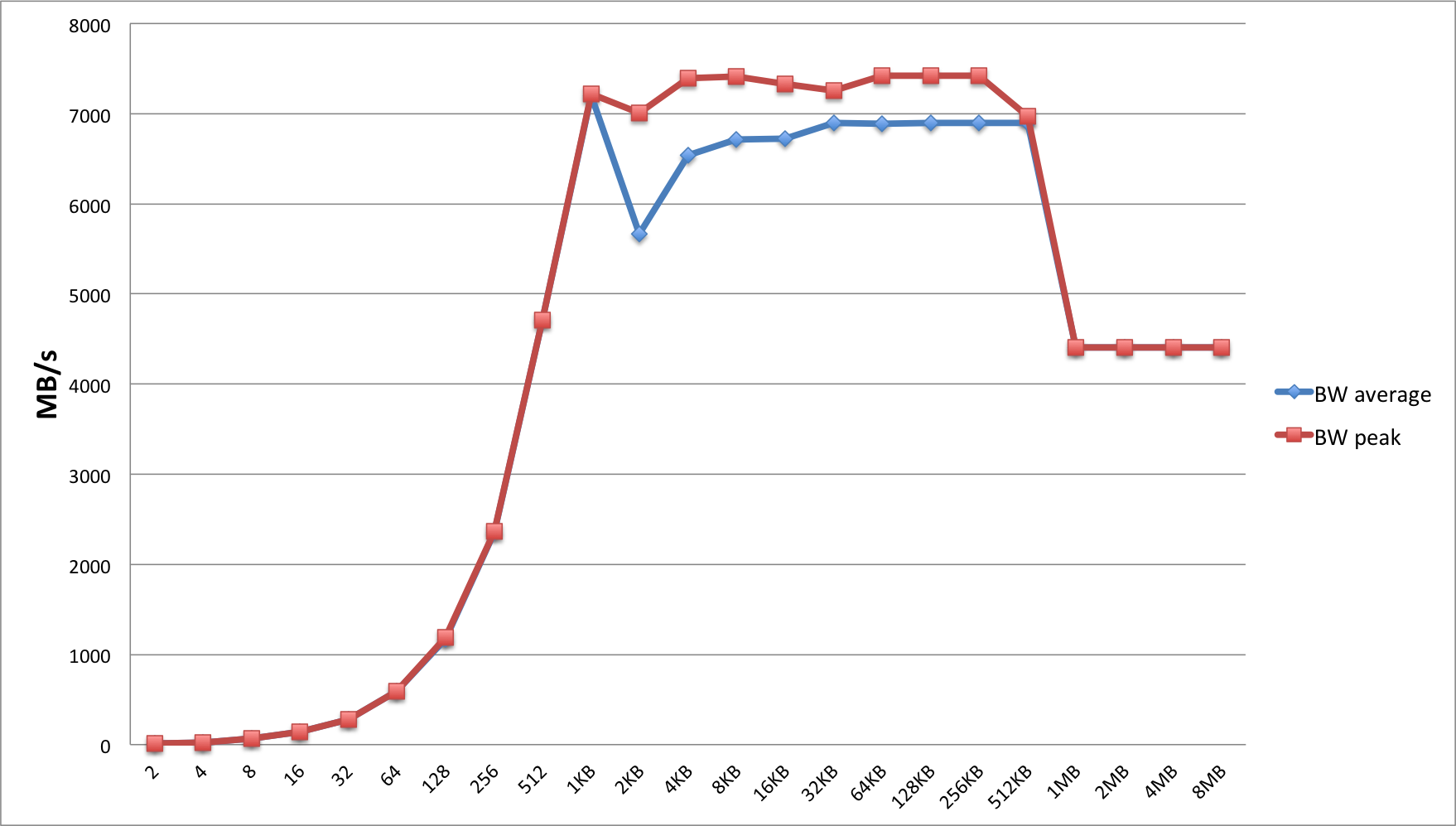
This case is limited by the available (peer-to-peer) GPU read bandwidth on the sender side. To give an idea, the graph above shows both the peak and the average bandwidth for different message sizes over 1000 iterations. The drop in performance beyond 512KB is probably due to the working set approaching the size (1536KB) of the K40 L2 cache.
Conclusions
GPUDirect RDMA provides a latency consistently below 2us, which is a good improvement over staging to/from host memory and moving it via Infiniband. This is so because staging uses either (synchronous) cudaMemcpy or cudaMemcpyAsync, which can easily take 8μs and 9μs respectively. In comparison, Infiniband has a 1.3μs host-to-host latency. Therefore the expected GPU-to-GPU send/recv latencies are 1.9μs (Figure 1.9) and 2×8+1.3~17μs (paying the copy cost twice) respectively for the GPUDirect RDMA and the staged cases, for small message sizes.
By using a simple performance model it can be shown that GPUDirect RDMA is faster than the staging approach for message sizes up to 400-500KB (on Ivy Bridge Xeon).
| Platform | Host-to-Host | Host-to-GPU | GPU-to-Host | GPU-to-GPU |
|---|---|---|---|---|
| Ivy Bridge | 12.3 | 9.8 | 3.7 | 3.7 |
| PCIe Switch (PLX) | 12.3 | 11.6 | 7 | 7 |
On the other hand, GPUDirect RDMA bandwidth performance may suffer from PCIe architectural bottlenecks, PCIe bus topology and NUMA-like effects. On recent server platforms, the obtainable performance can still be well below the expected peak, though better than on the Sandy Bridge Xeon platform, which we showed is severely limited (800MB/s). Paradoxically, on the Westmere Xeon platform, peer-to-peer read bandwidth (1.5GB/s, not shown here) was better than on Sandy Bridge (800MB/s). On Ivy Bridge Xeon systems, PCIe peer-to-peer write bandwidth to GPU memory is 9.8GB/s (12.3GB/s to host memory), while PCIe peer-to-peer read bandwidth is much less (3.4-3.7GB/s). Those limitations are mainly ascribed to bottlenecks of the host platform rather than of the GPU, as our experiments with the GPU and the IB adapter directly attached to a PCIe switch demonstrate. In the latter case, the available bandwidth is actually larger than that of a single FDR port (6.1GB/s), and close to the peak when writing (11.6 vs 12.3GB/s) and roughly 7GB/s for reading.
In general, for both bandwidth and latency, the number and type of traversed chipsets/bridges/switches do actually matter. Crossing the inter-socket bus (in our case QPI) is allowed, but it introduces a huge bottleneck, especially in one direction (250MB/s for write vs 1.1GB/s for read bandwidth). If in doubt, we strongly suggest to check the topology of your servers. Since release 340 of the NVIDIA display driver, the nvidia-smi command line tool can be used to display topological information about the system, including the full connectivity matrix of the different peer-to-peer data paths, including IB devices. For example on our N.1 platform (described in the Platforms section below), we see the following topology report.
$ nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 mlx5_0 CPU Affinity
GPU0 X PIX PHB SOC SOC PHB 0,1,2,3,4,5,6,7,8,9
GPU1 PIX X PHB SOC SOC PHB 0,1,2,3,4,5,6,7,8,9
GPU2 PHB PHB X SOC SOC PIX 0,1,2,3,4,5,6,7,8,9
GPU3 SOC SOC SOC X PHB SOC 10,11,12,13,14,15,16,17,18,19
GPU4 SOC SOC SOC PHB X SOC 10,11,12,13,14,15,16,17,18,19
mlx5_0 PHB PHB PIX SOC SOC X
Legend:
X = Self
SOC = Path traverses a socket-level link (e.g. QPI)
PHB = Path traverses a PCIe host bridge
PXB = Path traverses multiple PCIe internal switches
PIX = Path traverses a PCIe internal switch
In the example above, mlx5_0 and GPU2 are marked as being connected by a PCIe switch, so we expect very good performance.
Platforms
This is a brief description of the platform used in the benchmarks.
Servers
- Super Micro Computer 2U SYS-2027GR-TRFH, with a riser card hosting a PCIe switch (PLX Technology PEX 8747).
- Super Micro Computer 1U SYS-1027GR-TRF.
CPUs
- Ivy Bridge Xeon (IVB) E5-2690 v2 @ 3.00GHz.
- Sandy Bridge Xeon (SNB), only for one test
GPUs
- NVIDIA K40m (GK110B).
- NVIDIA K20 (GK110), only for the SNB Xeon bandwidth test.
Infiniband Hardware
- Mellanox dual-port Connect-IB, hosting a PCIe Gen3 X16 link and two FDR ports.
- Mellanox single-port ConnectX-3, only for the SNB Xeon bandwidth test
- Mellanox FDR switch
SW
- CUDA 6.0
- NVIDIA Display driver r331
- Mellanox OFED 2.2