Magnum IO is the collection of IO technologies from NVIDIA and Mellanox that make up the IO subsystem of the modern data center and enable applications at scale. If you are trying to scale up your application to multiple GPUs, or scaling it out across multiple nodes, you are probably using some of the libraries in Magnum IO. NVIDIA is now publishing the Magnum IO Developer Environment 21.04 as an NGC container, containing a comprehensive set of tools to scale IO. This allows you to begin scaling your applications on a laptop, desktop, workstation, or in the cloud.
Magnum IO brings the ability to improve end-to-end wall clock time of IO bound applications. Imagine a workflow with three stages:
- ETL (extract, transform, load)
- Scaled-out compute
- Post-processing and output
The first-stage ETL jobs are dominated by reading large amounts of data into GPUs and can achieve optimal performance by using Magnum IO GPUDirect Storage (GDS) for directly copying data from storage into GPU memory. This also helps reduce the CPU utilization and improves overall data center utilization.
The second stage, which comprises a distributed communication GPU-to-GPU IO intense job, can benefit from optimizing communication with NCCL message-passing or NVSHMEM shared memory models, on low latency InfiniBand networks.
The final post-processing and output stages, as well as the checkpointing and temporary storage during the workflow, can again improve performance with GDS. Magnum IO management layers also enable monitoring, troubleshooting, and detecting anomalies of all the stages of the workflow.
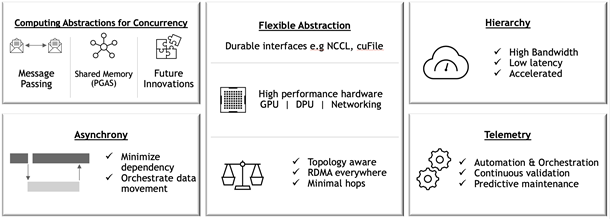
Scaling applications to run efficiently is often a complex and time-consuming task. We understand that the changes to code to adopt the Magnum IO technologies can be invasive, and any changes require development, debugging, testing, and benchmarking. Magnum IO libraries also work alongside the profilers, logging, and monitoring tools needed to observe what’s happening, locate bottlenecks, and address them. You should understand the performance tradeoffs of each stage of the computation and understand the relationships and between the hardware components in the system.
Magnum IO libraries provide APIs that manage the underlying hardware, allowing you to focus on the algorithmic aspects of your applications. The APIs are designed to be high-level so that they are easy to integrate with, but also to expose finer controls for when you start fine-tuning performance, after the behaviors and tradeoffs of the application running at scale are understood.
The high bandwidth and low latency offered by NVLink operating at 300GB/s, and InfiniBand in NVIDIA DGX A100 systems also opens new possibilities for algorithms. The NVLink bandwidth between GPUs now makes remote memory almost local. The total number of PCIe lanes from remote storage may exceed those from local storage. Magnum IO libraries on NVIDIA hardware allow algorithms to take full advantage of the GPU memory across all nodes, rather than sacrificing efficiency to avoid what was bottlenecking IO with high latencies in the past.
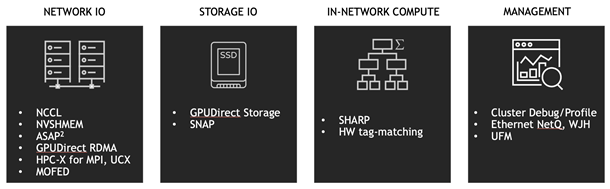
Magnum IO: GPU-to-GPU communications
Core to Magnum IO are libraries that allow GPUs to talk directly to each other over the fasted links available.
NCCL
The NVIDIA Collective Communications Library (NCCL, pronounced “nickel”) is a library providing inter-GPU communication primitives that are topology-aware and can be easily integrated into applications.
NCCL is smart about IO on systems with complex topology: systems with multiple CPUs, GPUs, PCI busses, and network interfaces. It can selectively use NVLink, Ethernet, and InfiniBand, using multiple links when possible. Consider using NCCL APIs whenever you plan your application or library to run on a mix of multi-GPU multi-node systems in a data center, cloud, or hybrid system. At runtime, NCCL determines the topology and optimizes layout and communication methods.
NVSHMEM
NVSHMEM creates a global address space for data that spans the memory of multiple GPUs and can be accessed with fine-grained GPU-initiated operations, CPU-initiated operations, and operations on CUDA streams.
In many HPC workflows, models and simulations are run that far exceed the size of a single GPU or node. NVSHMEM allows for a simpler asynchronous communication model in a shared address space that spans GPUs within or across nodes, with lower overheads, possibly resulting in stronger scaling compared to a traditional Message Passing Interface (MPI).
UCX
Unified Communication X (UCX) uses high-speed networks, including InfiniBand, for inter-node communication and shared memory mechanisms for efficient intra-node communication. If you need a standard CPU-driven MPI, PGAS OpenSHMEM libraries, and RPC, GPU-aware communication is layered on top of UCX.
UCX is appropriate when driving IO from the CPU, or when system memory is being shared. UCX enables offloading the IO operations to both host adapter (HCA) and switch, which reduces CPU load. UCX simplifies the portability of many peer-to-peer operations in MPI systems.
Magnum IO: Storage-to-GPU communications
Magnum IO also addresses the need to move data between GPUs and storage systems, both local and remote, with as little overhead as possible along the way.
GDS
NVIDIA GPUDirect Storage (GDS) enables a direct data path for Remote Direct Memory Access (RDMA) transfers between GPU memory and storage, which avoids a bounce buffer and management by the CPU. This direct path increases system bandwidth and decreases the latency and utilization load on the CPU.
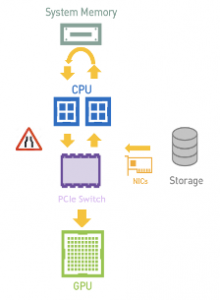

a) Without GDS 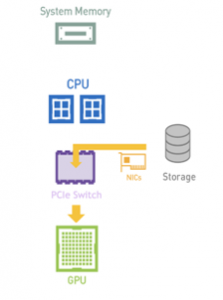

b) With GDS
GDS and the cuFile APIs should be used whenever data needs to move directly between storage and the GPU. With storage systems that support GDS, significant increases in performance on clients are observed when IO is a bottleneck. In cases where the storage system does not support GDS, IO transparently falls back to normal file reads and writes.
Moving the IO decode/encode from the CPU to GPU creates new opportunities for direct data transfers between storage and GPU memory which can benefit from GDS performance. An increasing number of data formats are supported in CUDA.
Magnum IO: Profiling and optimization
NVIDIA Nsight Systems lets you see what’s happening in the system and NVIDIA Cumulus NetQ allows you to analyze what’s happening on the NICs and switches. This is critical to finding some causes of bottlenecks in multi-node applications.
Nsight Systems
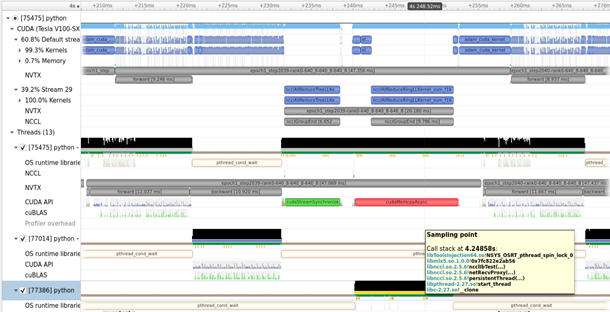
Nsight Systems is a low-overhead performance analysis tool designed to provide insights that you need to optimize your software. It provides everything that you would expect from a profiler for a GPU. Nsight Systems has a tight integration with many core CUDA libraries, giving you detailed information on what is happening.
Nsight Systems allows you to see exactly what’s happening on the system, what code is taking a long time, and when algorithms are waiting on GPU/CPU compute, or device IO. Nsight Systems is relevant to Magnum IO and included in the Magnum IO container for convenience, but its scope spans well outside of Magnum IO to monitoring compute that’s unrelated to IO.
NetQ
NetQ is a highly scalable, modern, network operations tool set that provides visibility, troubleshooting and lifecycle management of your open networks in real time. It enables network profiling functionality that can be used along with Nsight Systems or application logs to observe the network’s behavior while the application is running.
NetQ is part of Magnum IO itself, given its integral involvement in managing IO in addition to profiling it.
Getting started with the Magnum IO Developer Environment
We are launching the Magnum IO Developer Environment as a container hosted on NVIDIA NGC for GTC 21. A bare-metal installer for Ubuntu and RHEL may be coming soon. The container provides a sealed environment with the latest versions of the libraries compatible with each other. It makes it easy for you to begin optimizing your application’s IO. Installing and working with the container does not interfere with any existing system setup, which may have different versions of the components.
The Magnum IO components included in the 21.04 container are as follows:
- Ubuntu 20.04
- CUDA
- Nsight Systems CLI
- GDS
- GPUDirect RDMA
- GPUDirect P2P
- NCCL
- UCX
- NVSHMEM
The first step is to profile the application and find the bottlenecks, then evaluate which of the Magnum IO tools, libraries, or algorithm changes are appropriate for removing those bottlenecks and optimizing the application.
Download the developer environment today: Magnum IO SDK.
