This is the third post in the Accelerating IO series, which has the goal of describing the architecture, components, and benefits of Magnum IO, the IO subsystem of the modern data center.
The first post in this series introduced the Magnum IO architecture; positioned it in the broader context of CUDA, CUDA-X, and vertical application domains; and listed the four major components of the architecture. The second post delved deep into the Network IO components of Magnum IO. This third post covers two shorter areas: computing that occurs in the network adapter or switch and IO management. Whether your interests are in InfiniBand or Ethernet, NVIDIA Mellanox solutions have you covered.
HDR 200G InfiniBand and NDR 400G, the next-generation network
InfiniBand is the ideal choice of interconnect for AI supercomputing. It is being used in eight of the top 10 supercomputers in the world, and 60 of the top hundred, based on the November 2020 TOP500 supercomputers list. InfiniBand also accelerates the top Green500 supercomputer. Being a standard-based interconnect, InfiniBand enjoys the continuous development of new capabilities for higher applications performance, and scalability.
InfiniBand technology is based on four main fundamentals:
- An endpoint that can execute and manage all the network functions at the network level and therefore increase the CPU or GPU time that can be dedicated for the real applications. Because the endpoint is located near CPU/GPU memory, it can also manage memory operations in an effective and efficient way, for example, using RDMA, GPUDirect RDMA, and GPUDirect Storage.
- A switching network that is designed for scale, based on a pure software-defined network (SDN). InfiniBand switches, for example, do not require an embedded server within every switch appliance for managing the switch and running its operating system. This makes InfiniBand a leading cost-performance network fabric compared to other networks. The simple switch architecture leaves room to enable other technology innovations such as in-network computing for manipulating the data as it is being transferred through the network. An important example is the Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) technology, which has demonstrated great performance improvements for scientific and deep learning application frameworks.
- Centralized management for the entire InfiniBand network from a single place. You can design and build any sort of network topology with a common IB-switch building block and customize and optimize the data center network for its target applications. There is no need to create different switch configurations for different parts of the network and no need to deal with multiple complex network algorithms. InfiniBand was created to improve performance and reduce OPEX.
- Backward and forward compatibility. InfiniBand is open source with open APIs.
At SuperComputing 20, NVIDIA announced the seventh generation of the NVIDIA Mellanox InfiniBand architecture, featuring NDR 400Gb/s (100 Gb/s per lane) InfiniBand. This gives AI developers and scientific researchers the fastest networking performance available to take on the world’s most challenging problems. Figure 1 shows that InfiniBand continues to set performance records with NDR InfiniBand:
- 2x the data throughout with 400Gb/s bandwidth per port.
- 4x Message Passing Interface (MPI) performance for all-to-all operations with a new In-Network Computing acceleration engine for all-to-all operations.
- Higher switch radix, supporting 64 ports of 400Gb/s or 128 ports of 200Gb/s. The higher radix enables building low-latency network topologies connecting more than one million nodes in a three-hop Dragonfly+ network topology.
- The largest high-performance switch system, based on non-blocking, two layers fat tree topology design, providing 2048 ports of 400Gb/s or 4096 ports of 200Gb/s, a total of 1.6 petabit of bi-directional data throughput.
- Increased AI network acceleration with the SHARP technology, enabling 32x higher capacity for large message reduction operations in the network.

High-speed Ethernet: 200G and 400G Ethernet
Ethernet and InfiniBand each have their unique advantages. NVIDIA Mellanox covers the bases with this pair of solutions. There are several cases where an Ethernet-based solution is preferred by customers. Some storage systems only work with Ethernet. There’s increasing interest in security, and the incumbent protocol is IPSec, which is not available on InfiniBand. The Precision Time Protocol (PTP) is used to synchronize clocks throughout a network at sub-microsecond granularities, such as for high-frequency trading. In many cases, the longstanding expertise in Ethernet-based tools for orchestration and provisioning, analyzers that monitor security, performance tuning, compliance, or technical support is what drives customer selection, rather than other cost or performance concerns.
Both Ethernet and InfiniBand solutions interoperate with best-practice tools of broad interest, such as sFlow and NetFlow network monitoring and analysis solutions, and automation tools, like Ansible, Puppet, and SaltStack.
Ethernet has become ubiquitous, in part because it is perceived as easy to configure and manage. However, GPUDirect RDMA and GPUDirect Storage over Ethernet require that the network fabric be configured to support RDMA over Converged Ethernet (RoCE). RoCE can be complicated to configure and manage on most network vendors’ equipment. The NVIDIA Mellanox Ethernet switches eliminate this complexity by enabling RoCE with a single command as well as providing RoCE-specific visibility and troubleshooting features.
NVIDIA Mellanox Ethernet switches, which now operate at up to 400 Gb/s, deliver the highest levels of performance, as they offer the lowest latency packet forwarding of any Ethernet switches on the market. The NVIDIA Mellanox Ethernet switches also provide unique congestion avoidance innovations that provide application-level performance benefits for RoCE based workloads:

Ethernet switches have been proven to scale, with all the largest data centers in the world running pure Ethernet fabrics using the simple and well-understood leaf and spine topologies. Ethernet fabrics from NVIDIA are easy to automate, with NVIDIA-provided turnkey product-ready automation tools freely available and posted on GitHub.
High-speed Ethernet switches from NVIDIA are shipping today with 100GbE, 200GbE, and even 400GbE speeds for the highest levels of performance for Ethernet-based storage and GPU connectivity.
NVIDIA InfiniBand in-network compute
In-network computing engines refer to preconfigured computing engines located on the data path of network adapters or switches. These engines can process data or perform predefined algorithms tasks on the data while being transferred within the network. Two examples for such engines are the hardware MPI tag matching and InfiniBand SHARP.
Hardware tag-matching engine
The MPI standard allows for matching messages to be received based on tags that are embedded in the message. Processing every message to evaluate whether its tags match the conditions of interest is time-consuming and wasteful.
MPI send/receive operations require matching source and destination message parameters to deliver data to the correct destination. The order of matching must follow the order in which sends and receives are posted. The key challenges for providing efficient tag-matching support include the following:
- Managing the metadata needed for tag matching.
- Making temporary copies of data to minimize the latency between tag-matching and data delivery.
- Keeping track of posted receives that have not been matched.
- Handling unexpected message arrival.
- Overlapping tag-matching and the associated data delivery with ongoing computation.
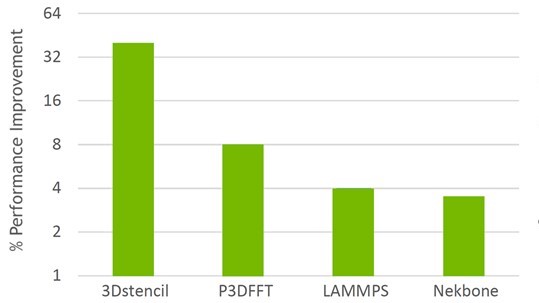
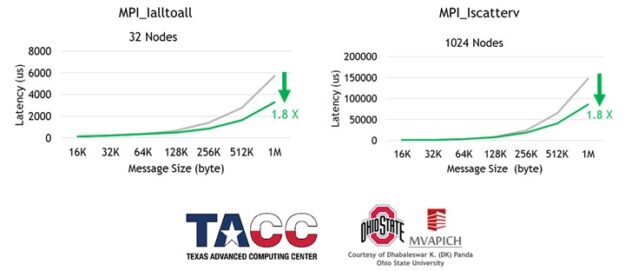
Support for asynchronous, hardware-based tag matching and data delivery is part of ConnectX-6 (or later) network adapters. The network hardware-based tag matching reduces the latency of multiple MPI operations, while also increasing the overlapping between MPI compute and communication (Figures 3 and 4).
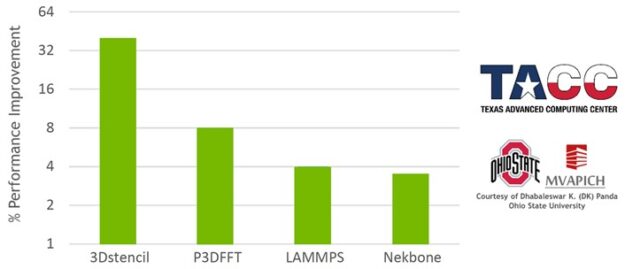
SHARP: Scalable Hierarchical Aggregation and Reduction Protocol
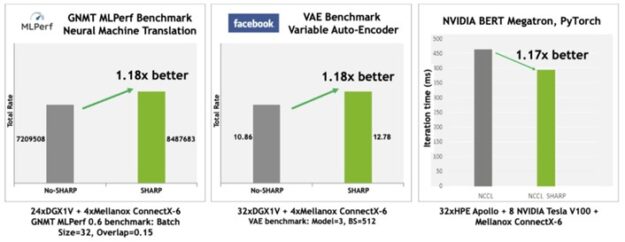
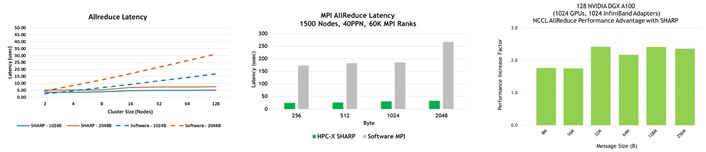
NVIDIA Mellanox InfiniBand SHARP improves the performance of collective operations by processing data aggregation and reduction operations as it traverses the network, eliminating the need for sending data multiple times between endpoints. This innovative approach not only decreases the amount of data traversing the network, but offers additional benefits, including freeing valuable CPU resources for computation rather than using them to process communication overhead. It also progresses such communication in an asynchronous manner, independent of the host processing state.
Without SHARP, data must be sent from each endpoint to the switch, back down to endpoints where collectives are computed, back up to the switch, and then back to the endpoints. That’s four traversal steps. With SHARP, the collective operations happen in the switch, so the number of traversal steps is halved: from endpoints to the switch and back. This leads to a 2x improvement in bandwidth for such collective operations and a reduction of 7x in MPI allreduce latency (Figure 5). Of course, the throughput demand overheads are also dropped from the CPU or GPU that would otherwise be used for computation.
- Operations supported:
- Floating point data: barrier, reduce, allreduce, broadcast, gather and allgather
- Signed and unsigned integer data: Operands of size 64, 32, and 16 bits
- Reduction operations supported: sum, min, max, minloc, maxloc and bitwise AND, OR, and XOR.
The SHARP technology is integrated in most of the open-source and commercial MPI software packages as well as OpenSHMEM, NCCL, and other IO frameworks.
InfiniBand and Ethernet IO management
While boosting performance is of interest to end users and a clear architecture aids developers, IO management is of critical importance to you as an administrator and the end users that you serve. NVIDIA Mellanox NetQ and UFM management platforms enable IT managers to easily configure, manage, and optimize their Ethernet connected data centers (NetQ) or InfiniBand-connected data centers (UFM) operations.
Ethernet NetQ
NVIDIA Mellanox NetQ is a highly scalable, modern, network operations tool set that provides visibility, troubleshooting, and lifecycle management of open Ethernet networks in real time. NetQ delivers actionable insights and operational intelligence about the health of the data center and campus Ethernet networks—from the container or host all the way to the switch and port, enabling a NetDevOps approach. NetQ is the leading Ethernet network operations tool that uses telemetry for deep troubleshooting, visibility, and automated workflows from a single GUI interface, reducing maintenance and network downtimes.
NetQ is also available as a secure cloud service, making it even easier to install, deploy, and scale the network. A cloud-based deployment of NetQ offers instant upgrades, zero maintenance, and minimizes appliance management efforts.
With the addition of full lifecycle management functionality, NetQ combines the ability to easily upgrade, configure, and deploy network elements with a full suite of operations capabilities, such as visibility, troubleshooting, validation, trace, and comparative look-back functionality.
NetQ includes the Mellanox What Just Happened (WJH) advanced streaming telemetry technology that goes beyond conventional telemetry solutions by providing actionable details on abnormal network behavior. Traditional solutions try to extrapolate root causes of network issues by analyzing network counters and statistical packet sampling. WJH eliminates the guesswork from network troubleshooting.
The WJH solution uses the unique hardware capabilities built into the NVIDIA Mellanox Spectrum family of Ethernet switch ASICs to inspect packets at multi-terabit speeds—faster than software or firmware-based solutions. WJH can help in the diagnosing and repair of your datacenter network, including software problems. WJH inspects packets across all ports at line-rate, at speeds that overwhelm traditional deep packet inspection (DPI) solutions. WJH saves you hours of onsite technical support services for troubleshooting, maintenance, and repair of computer software.
InfiniBand Unified Fabric Manager

The NVIDIA Mellanox InfiniBand Unified Fabric Manager UFM platforms revolutionize data center networking management. By combining enhanced and real-time network telemetry with AI-powered cyber intelligence and analytics, the UFM platforms empower IT managers to discover operation anomalies and predict network failures for preventive maintenance.
The UFM platforms comprise multiple levels of solutions and capabilities to suit datacenter needs and requirements. At the basic level, the UFM Telemetry platform provides network validation tools, and monitors the network performance and conditions. It captures, for example, rich real-time network telemetry information, workload usage data, and system configuration, and then streams it to a defined on-premises or cloud-based database for further analysis.
The mid-tier UFM Enterprise platform adds enhanced network monitoring, management, workload optimizations, and periodic configuration checks. In addition to including all the UFM Telemetry services, it provides network setup, connectivity validation, and secure cable management capabilities, automated network discovery and network provisioning, traffic monitoring, and congestion discovery. UFM Enterprise also enables job scheduler provisioning and integration with Slurm or Platform LSF, in addition to network provisioning and integration with OpenStack, Azure Cloud, and VMware.
The enhanced UFM Cyber-AI platform includes all the UFM Telemetry and UFM Enterprise services. The unique advantages of the Cyber-AI platform are based on capturing rich telemetry information over time and using deep learning algorithms. The platform learns the data center’s “heartbeat,” operation mode, conditions, usage, and workload network signatures. It builds an enhanced database of telemetry information and discovers correlations between events. It detects performance degradations, usage, and profile changes over time, and provides alerts of abnormal system and application behavior, and potential system failures. It can also perform corrective actions.
The Cyber-AI platform can translate and correlate changes in the data center heartbeat to indicate future performance degradations or abnormal usage of the data center computing resources. Such changes and correlations trigger predictive analytics and initiate alerts that indicate abnormal system and application behavior, as well as potential system failures. System administrators can quickly detect and respond to such potential security threats and address upcoming failures in an efficient manner, saving OPEX and maintaining end-user SLAs. Predictability is optimized over time with the collection of additional system data.
Summary
A new generation of networking hardware and software is arriving. It brings higher data rates, larger switch system capacity, and SHARP hierarchical reduction capabilities for 32 independent operations in a single switch. Try out some of the new technologies:
- Download NVIDIA HPC-X MPI and experiment with hardware tag matching and SHARP for your applications.
- Contact NVIDIA to use the InfiniBand In-Network Computing engines directly for your applications.
- Try NVIDIA Ethernet switching in a virtual “hands on” environment with Cumulus in the Cloud.
- Experience the benefits of easier network management and explore how to optimize the network operations with NetQ and WJH for Ethernet and UFM for InfiniBand.
- Learn more about the new Mellanox NDR InfiniBand technologies.
- Learn more about the Mellanox 200 & 400 Gigabit Ethernet switches that are shipping today.
NVIDIA thrives on solving end-to-end problems that lead to groundbreaking solutions. We have an established track record of connecting CUDA developers with application developers who bring forward requirements and high-quality reproducers for challenging problems and developing new technologies and revised roadmaps to further collaboration. We invite you to engage more deeply with us to do our life’s work in new science!
