This is the first post in the Accelerating IO series, which describes the architecture, components, storage, and benefits of Magnum IO, the IO subsystem of the modern data center.
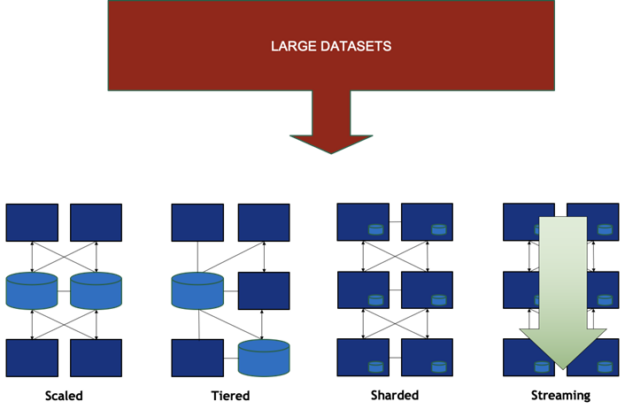
Previously the boundary of the unit of computing, sheet metal no longer constrains the resources that can be applied to a single problem or the data set that can be housed. The new unit is the data center. A single box can hold not just one GPU, CPU, and NIC, but a host of cooperating resources that operate on an ocean of data. Gone are the days when a single box could hold all of the computing resources and data of interest, so resources are now becoming physically distributed. Data sets may be scaled across nodes, sharded, or streamed from one place to another, as shown in Figure 1.
Larger cooperative computing jobs need efficient “east-west” communication across the data center in order to scale. Workflows of increasing complexity are likewise spread across the hierarchy of resources within and across nodes. The newest workflows are often a mashup of high-performance computing (HPC), deep learning, data analytics, and visualization, all going on concurrently on shared data and computing resources. Workflows are often composed of microservices. Microservice deployment with containers and Kubernetes is increasingly common in HPC, not just in the enterprise. There may be an unpredictable pipeline of data flowing among microservices, and the number and location of microservices may also vary with dynamic load.
The distributed set of resources throughout the data center must still operate as a cohesive unit to execute a mix of scaled applications and a set of microservices. Access to data and the unpredictable movement of data among stages presents a serious challenge. This requires more bandwidth, lower latency, less interference with and reliance on CPUs, and in-network computing. This calls for a principled bolstering of general IO performance capabilities under flexible abstractions, rather than relying on special-case tuning for a single-app scenario. It also demands fine-tuned management of all IO traffic for improved quality of service, failure prediction, reliability and availability.
NVIDIA Magnum IO is the IO subsystem for the modern accelerated data center. The Magnum IO architecture presents you with an organized arrangement of capabilities with which to best design your applications, frameworks, or infrastructure to run in a data center equipped with state-of-the-art, high compute capacity GPUs, storage, and high-performance interconnect. Magnum IO offers abstractions to hide the complexity of the underlying software layers and yet still allow you to enjoy the breakthrough performance of evolving technologies from NVIDIA developer innovation. This flexible abstraction introduces a separation of concerns that protects you from the dizzying complexity and unpredictability of underlying data management so that you can just get your data.
Magnum IO architecture
The name Magnum IO is derived from multi-GPU, multi-node input/output. Inside a data center, there’s a hierarchy of resources across which data must be managed. There’s a hierarchy of computing, memory, and storage resources at the GPU, node, sub-cluster, and data center levels. Access, movement, and management of data across all NVIDIA GPUs and NVIDIA networks must be controlled and abstracted through the varied set of APIs, libraries, and programming models that NVIDIA offers.
This is what Magnum IO does. Underneath those abstractions, implementations can optimize performance and utility. For example, compute can happen in the network while data is moving. Management of data can be isolated from malicious code running on the CPU by offloading to a DPU (data processing unit). Regardless of the configuration of the data center and its network, management, efficiency, maintainability, and reliability can be streamlined. The Magnum IO architecture specifies what features are provided and how.
Architectural principles
Any architecture is defined by a set of principles. There are four fundamental principles that are common to both the CUDA architecture and the Magnum IO architecture: concurrency, asynchrony, hierarchy, and tools and telemetry. Magnum IO’s higher-level abstractions add a fifth, flexibility.
Concurrency
- CUDA: The CUDA programming model enables programs to take advantage of the massively parallel GPU cores by exposing parallelism with computational kernels run on a grid of data. To counter Amdahl’s Law and remove scaling bottlenecks, successive CUDA releases have aimed to reduce latency and other overheads in CPU-GPU coordination.
- Magnum IO: Similarly, IO is parallelized across threads (for example, using NVSHMEM), across many GPUs within each node, and is scaled across nodes. Fully connected networks avoid fabric bottlenecks. RDMA (Remote Direct Memory Access) is fundamental to reducing overheads and avoiding CPU bandwidth and throughput bottlenecks.
Asynchrony
- CUDA: Avoiding blocking operations is essential to concurrency. The CUDA streams and graphs enable deferred execution so that work can be enqueued rapidly but dependencies are resolved at runtime after work is submitted.
- Magnum IO: Many of the programming interfaces that are part of Magnum IO offer stream-oriented APIs, such as NCCL, NVSHMEM, and cuFile.
Hierarchy
- CUDA: The CUDA programming model constrains users to present datasets in a hierarchical grid of many blocks, each with many threads, which can be easily mapped onto symmetric multiprocessors. This constraint enables you to be more effective in using the hierarchical organization of compute resources, data paths, and hardware synchronization to both harvest data and control locality to scale more efficiently. CUDA also provides mechanisms to share GPUs and communicate across processes in the same node.
- Magnum IO: Magnum IO enables the best use of memory and storage locality within various parts of the overall hierarchy, whether it’s within a node, a sub-cluster, or a whole data center.
Tools and telemetry
- CUDA: Developer tools provide deep insight into what goes on inside a CUDA application and the GPU resources that it is using.
- Magnum IO: Magnum IO extends that scope to span the operations of the data center. It incorporates real-time telemetry, performance analysis, and failure detection to provide you with a deep view into the run-time behavior of the system.
Flexible abstraction
- Magnum IO: Magnum IO has both low-level interfaces that put you in control, and higher-level, productivity-enhancing abstractions that manage locality, routing, and performance trade-offs automatically. Beneath those abstractions, Magnum IO implementations are free to use the latest hardware and software features of the CUDA platform and other NVIDIA or open-source technologies. They can also exercise the freedom to make choices about where work gets done and how data is managed, under higher-level interfaces.
Audience
The Magnum IO architecture is relevant to the following audiences:
- End users. Common frameworks and interfaces that have been enabled with Magnum IO enjoy the performance benefits of lower layers that are highly optimized for every platform and topology.
- Application developers. The architecture defines the space and features that guide designers to efficiently create enduring software architectures and frameworks. Magnum IO provides the easiest path to performance.
- Middleware developers. The SDKs that deliver Magnum IO technologies provide all the tools needed for low-level developers to get the job done.
- Administrators. IO management, including provisioning, telemetry, and analytics, helps admins monitor, preventatively troubleshoot, and maintain the data center fabric in top condition.
Layers
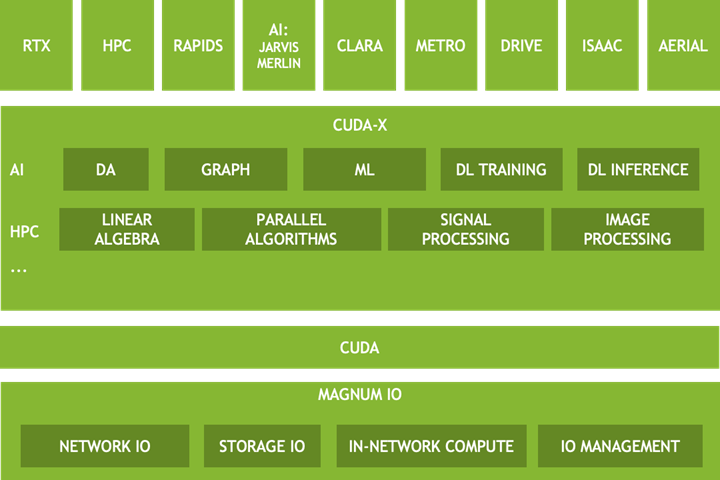
Figure 2 shows multiple layers in the Magnum IO architecture. The upper layers have a fundamental reliance on the following data-related abstractions.
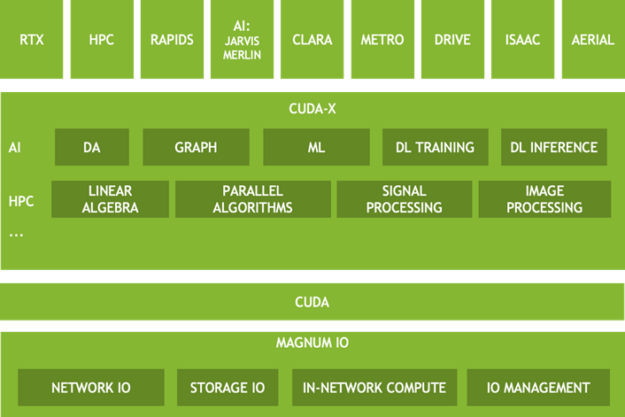
- Verticals—Components are specialized for a variety of application domains. Some aspects of Magnum IO may be unique to a particular vertical.
- CUDA-X—A broad set of highly optimized, domain-specific libraries based on CUDA. Two of many subcategories are shown: HPC and AI. The set of those functionalities deeply depends on the data center’s IO subsystem.
- CUDA—Many Magnum IO capabilities are layered on top of, or overlap with the CUDA driver and toolkit. While some verticals and some of CUDA-X depend on Magnum IO, other parts depend only on CUDA itself.
- Magnum IO—Data-related technologies can be divided into the four categories of Network IO, Storage IO, In-network compute, and IO management.
The architecture is intended to form a mental model for you to consider when developing applications and frameworks and infrastructure for the data center.
Magnum IO components
Figure 3 shows the technologies related to data at rest, data on the move, and data at work for the IO subsystem of the data center.

Here are some of the common themes across the features:
- Flexible abstraction enables innovation and optimization beneath high-level interfaces and standards.
- Hardware features and low-level technologies are exposed through easy-to-use, enduring interfaces.
- CPU offload both avoids the host CPU as a bottleneck and isolates services from malicious agents running on the host CPU.
- Performance optimization is achievable with an easy on-ramp, and selective controls enable expert tuning.
- Management provides visibility, maintainability, and control that makes data center solutions maintainable for the long haul.
Call to action
We invite you to join and view the GTC Fall session, Magnum IO: The IO Subsystem for the Modern, Accelerated Data Center. There are several new technologies that you can try:
- The GPUDirect Storage open beta v0.8 Early Access can enable multi-X bandwidth improvements from skipping an extra copy through a CPU bounce buffer and reducing the latency for smaller transfers. It works on today’s hardware but involves installing kernel drivers and user-level libraries. For more information, see the following resources
- Accelerating Storage with Magnum IO and GPUDirect Storage (GTC Fall 2020 session)
- Watch upcoming RAPIDS releases for support of GPUDirect Storage, so that you can try it out on file formats like Parquet with cuDF.
- NVSHMEM 1.1.3, just released in September 2020, brings new signaling functionalities to one-sided GPU-GPU data transfers. Download and try it!
- NCCL 2.7.8, updated in July 2020, includes support for point-to-point transfers, which also enable a broader set of collectives like all_gatherv and all_scatterv.
For more information about the performance advantages of these technologies, see the GTC Fall 2020 session, In-Network Computing: Accelerating scientific computing and deep learning applications.
NVIDIA thrives on solving end-to-end problems that lead to groundbreaking solutions. We have an established track record of connecting CUDA platform developers with application developers who bring forward requirements and high-quality reproducers for challenging problems. We also develop new technologies and revised roadmaps to further our collaboration. We invite you to work with us more closely to help create new science!
