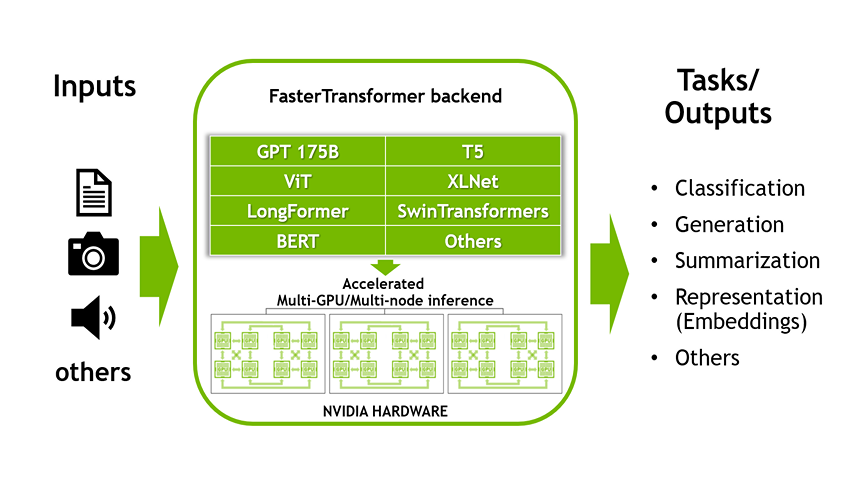
This is the first part of a two-part series discussing the NVIDIA Triton Inference Server’s FasterTransformer (FT) library, one of the fastest libraries for distributed inference of transformers of any size (up to trillions of parameters). It provides an overview of FasterTransformer, including the benefits of using the library.

Deploying GPT-J and T5 with Triton Inference Server (Part 2) is a guide that illustrates the use of the FasterTransformer library in Triton Inference Server to serve T5-3B and GPT-J 6B models in an optimal manner with tensor parallelism.
Transformers are among the most influential AI model architectures today and are shaping the direction for future R&D in AI. Invented first as a tool for natural language processing (NLP), they are now used for almost any AI task, including computer vision, automatic speech recognition, classification of molecule structures, and processing of financial data. Accounting for such widespread use is the attention mechanism, which noticeably increases the computational efficiency, quality, and accuracy of the models.
Large transformer-based models with hundreds of billions of parameters behave like a gigantic encyclopedia and brain that contains information about everything it has learned. They structurize, represent, and summarize all this knowledge in a unique way. Having such models with this vast amount of prior knowledge allows us to use new and powerful one-shot or few-shot learning techniques to solve many NLP tasks.
Thanks to their computational efficiency, transformers scale well–and by increasing the size of the network and the amount of training data, researchers can improve observations and increase accuracy.
Training such large models is a non-trivial task, however. The models may require more memory than one GPU supplies–or even hundreds of GPUs. Thankfully, NVIDIA researchers have created powerful open-source tools, such as the NeMo framework, that optimize the training process.
Fast and optimized inference allows enterprises to realize the full potential of these large models. The latest research demonstrates that increasing the size of the model as well as the dataset increases the quality of such a model on downstream tasks in different domains (NLP, CV, and others).
At the same time, data show that such a technique also works in multi-domain tasks. (See research papers like OpenAI’s DALLE-2 and Google’s Imagen on text-to-image generation, for example.) Research directions such as p-tuning that rely on “frozen” copies of huge models even increase the importance of having a stable and optimized inference pipeline. Optimized inference of such large models requires distributed multi-GPU multi-node solutions.
Accelerated inference of large transformers
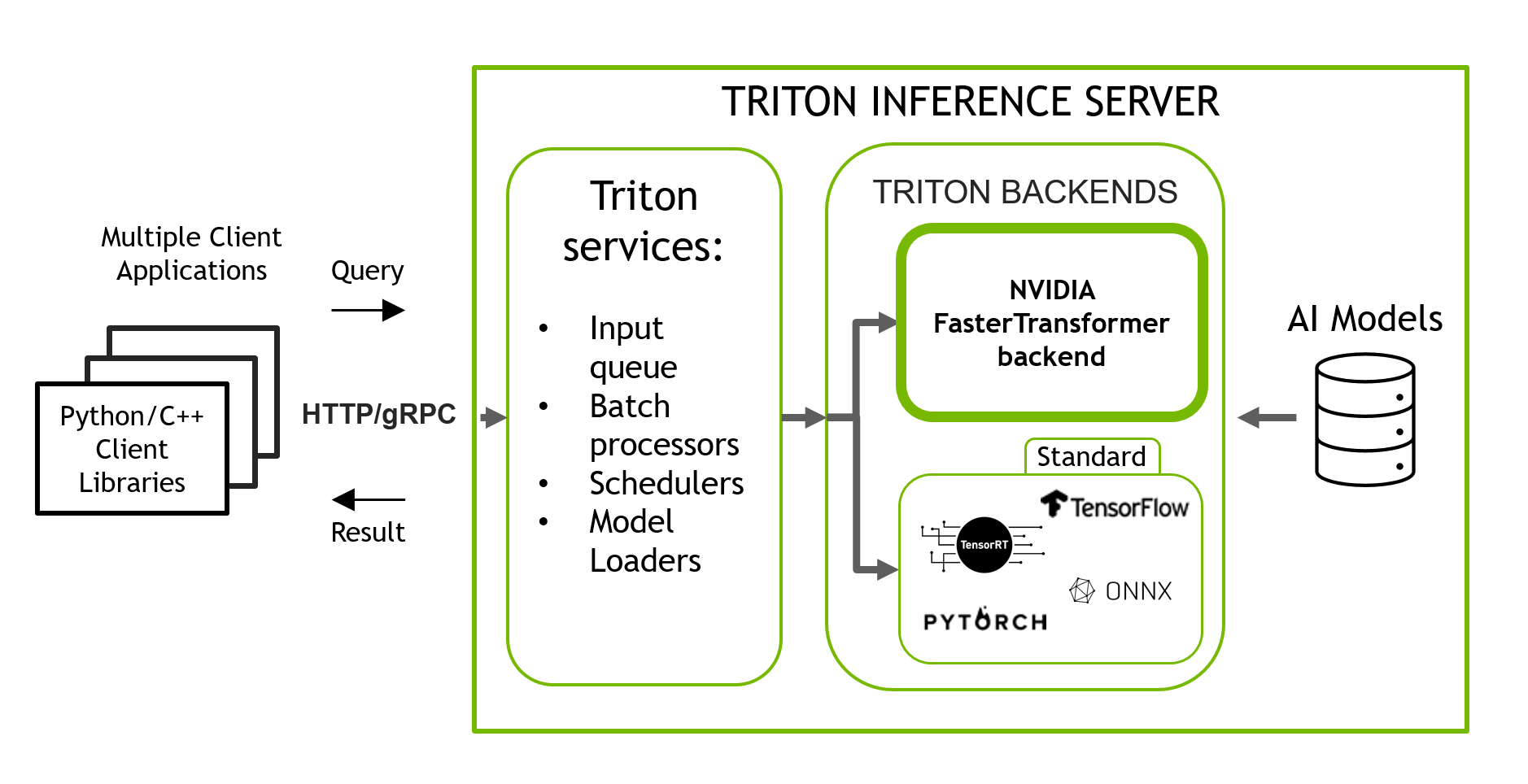
NVIDIA Triton Inference Server is an open-source inference serving software that helps standardize model deployment and execution, delivering fast and scalable AI in production. Triton is a stable and fast inference serving software that allows you to run inference of your ML/DL models in a simple manner with a pre-baked docker container using only one line of code and a simple JSON-like config.
Triton supports models using multiple backends such as PyTorch, TorchScript, Tensorflow, ONNX Runtime, OpenVINO and others. It has a backend for large transformer based models called NVIDIA’s FasterTransformer (FT). FT is a library implementing an accelerated engine for the inference of transformer-based neural networks, with a special emphasis on large models, spanning many GPUs and nodes in a distributed manner.
FasterTransformer contains the implementation of the highly-optimized version of the transformer block that contains the encoder and decoder parts.
Using this block, you can run the inference of both the full encoder-decoder architectures like T5, as well as encoder-only models, such as BERT, or decoder-only models, such as GPT. It is written in C++/CUDA and relies on the highly optimized cuBLAS, cuBLASLt , and cuSPARSELt libraries. This allows you to build the fastest transformer inference pipeline on GPU.
There are two parts to FasterTransformer. The first is the library which is used to convert a trained Transformer model into an optimized format ready for distributed inference. The second part is the backend which is used by Triton to execute the model on multiple GPUs.
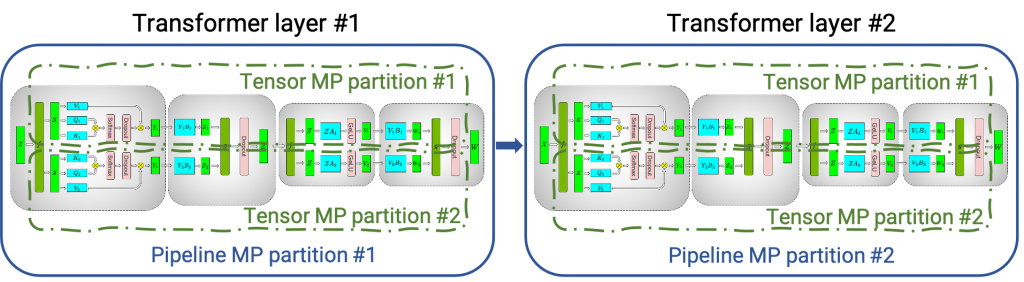
The distinctive feature of FT in comparison with other compilers like NVIDIA TensorRT is that it supports the inference of large transformer models in a distributed manner.
Figure 1 shows how a neural network with multiple classical transformer/attention layers could be split onto multiple GPUs and nodes using tensor parallelism (TP) and pipeline parallelism (PP) techniques.
Tensor parallelism occurs when each tensor is split up into multiple chunks, and each chunk of the tensor can be placed on a separate GPU. During computation, each chunk gets processed separately in-parallel on different GPUs and the results (final tensor) can be computed by combining results from multiple GPUs.
Pipeline parallelism occurs when a model is split up in-depth and different full layers are placed onto different GPUs/nodes.
Under the hood, enabling inter/intra-node communication relies on MPI and NVIDIA NCCL. Using this software stack, you can run large transformers in tensor parallelism mode on multiple GPUs to reduce computational latency.
At the same time, TP and PP may be combined together to run large transformer models with billions and trillions of parameters (which amount to terabytes of weights) on multi-GPU and multi-node environments.
Aside from the source codes in C, FasterTransformer also provides TensorFlow integration (using the TensorFlow op), PyTorch integration (using the PyTorch op), and Triton integration as a backend.
Currently, TensorFlow op only supports a single GPU, while PyTorch op and Triton backend both support multi-GPU and multi-node.
To prevent the additional work of splitting the model for model parallelism, FasterTransformer also provides a tool to split and convert models from different formats to the FasterTransformer binary file format. Then FasterTransformer can load the model in a binary format directly.
At this time, FT supports models like Megatron-LM GPT-3, GPT-J, BERT, ViT, Swin Transformer, Longformer, T5, and XLNet. You can check the latest support matrix in the FasterTransformer repo on GitHub.
FT works on GPUs with compute capability >= 7.0, such as V100, A10, A100, and others.
Optimizations in FasterTransformer
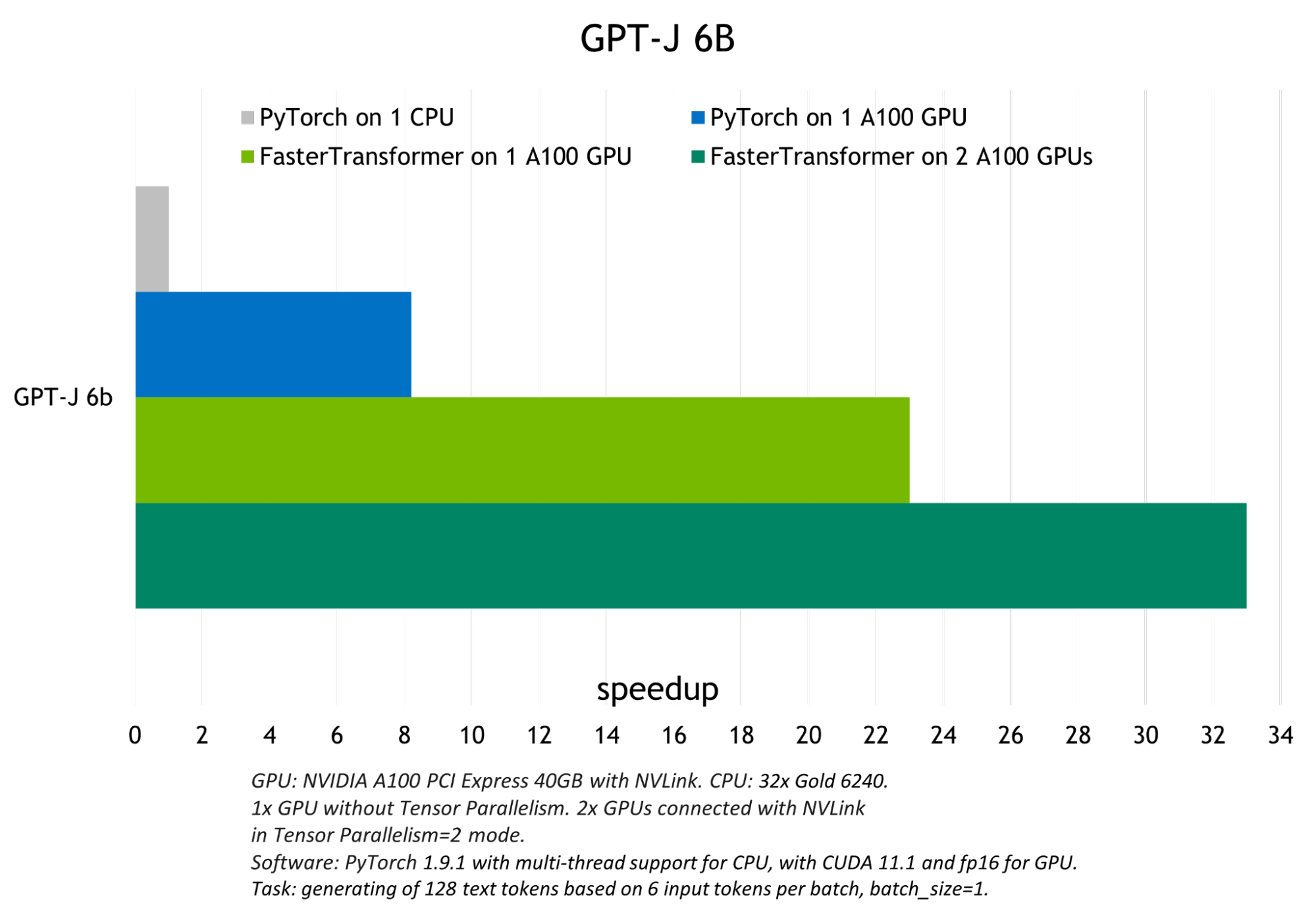
FT enables you to get a faster inference pipeline, with lower latency and higher throughput for the transformer-based NNs in comparison to the common frameworks for deep learning training.
Some of the optimization techniques that allow FT to have the fastest inference for the GPT-3 and other large transformer models include:
Layer fusion – The set of techniques in the pre-processing stage that combine multiple layers of NNs into a single one that would be computed with one single kernel. This technique reduces data transfer and increases math density, thus accelerating computation at the inference stage. For example, all the operations in the multi-head attention block can be combined into one kernel.
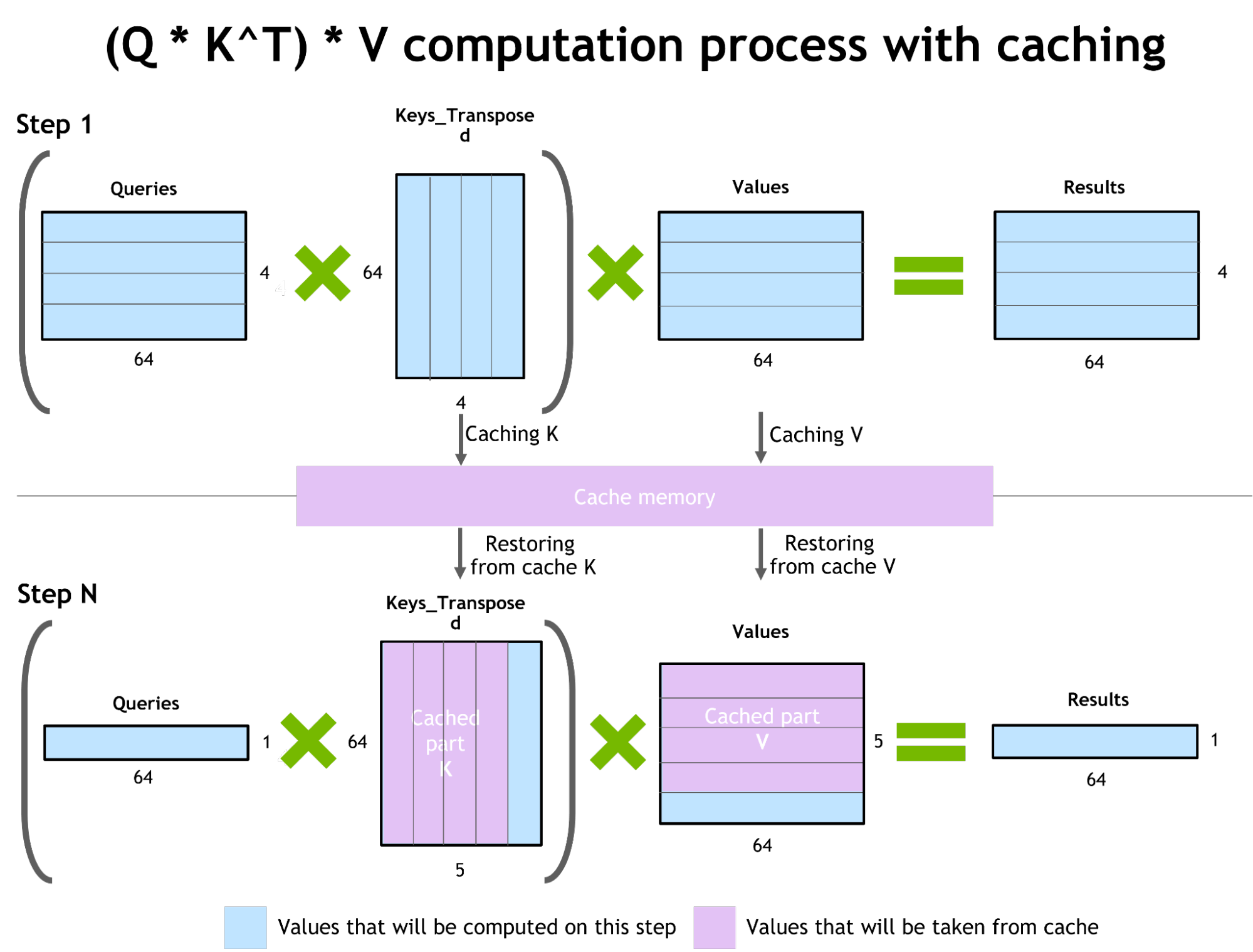
Inference optimization for autoregressive models / activations caching
To prevent recomputing the previous keys and values for each new token generator by transformer, FT allocates a buffer to store them at each step.
Although it takes some additional memory usage, FT can save the cost of recomputing, allocating a buffer at each step, and the cost of concatenation. The scheme of the process is presented in Figure 2. The same caching mechanism is used in multiple parts of the NN.
Memory optimization
Different from traditional models like BERT, large transformer models have up to trillions of parameters taking hundreds of GB of storage. GPT-3 175b takes 350 GB even if we store the model in half-precision. It’s therefore necessary to reduce memory usage for other parts.
For example, in FasterTransformer, we reuse the memory buffer of activations/outputs in different decoder layers. Since the number of layers in GPT-3 is 96, we only need 1/96 of the amount of memory for activations.
Usage of MPI and NCCL to enable inter/intra-node communication and support model parallelism
In the GPT model, FasterTransormer provides both tensor parallelism and pipeline parallelism. For tensor parallelism, FasterTransformer follows the idea of Megatron. For both the self-attention block and feed-forward network block, FT split the weights of the first matrix by row and split the weights of the second matrix by column. By optimization, FT can reduce the reduction operation to two times for each transformer block.
For pipeline parallelism, FasterTransformer splits the whole batch of requests into multiple micro-batches, hiding the bubble of communication. FasterTransformer will adjust the micro-batch size automatically for different cases.
MatMul kernel autotuning (GEMM autotuning)
Matrix multiplication is the main and the heaviest operation in transformer-based neural networks. FT uses functionalities from CuBLAS and CuTLASS libraries to execute these types of operations. It is important to know that MatMul operation can be executed in tens of different ways using different low-level algorithms at the “hardware” level.
GemmBatchedEx function implements MatMul operation and has “cublasGemmAlgo_t” as an input parameter. Using this parameter, you can choose different low-level algorithms for operation.
The FasterTransformer library uses this parameter to do a real-time benchmark of all low-level algorithms and to choose the best one for the parameters of the model (size of the attention layers, number of attention heads, size of the hidden layer) and for your input data. Additionally, FT uses hardware-accelerated low-level functions for some parts of the network such as __expf, __shfl_xor_sync.
Inference with lower precisions
FT has kernels that support inference using low-precision input data in fp16 and int8. Both these regimes allow acceleration due to a lower amount of data transfer and required memory. At the same time, int8 and fp16 computations can be executed on special hardware, such as the tensor cores (for all GPU architectures starting from Volta), and the transformers engine in the upcoming Hopper GPUs.
More
- Rapidly fast C++ BeamSearch implementation
- Optimized all-reduce for the TensorParallelism 8 mode When the weights parts of the model are split between eight GPUs
Today, GPT-J, GPT-Megatron, and T5 models are supported in Triton with FasterTransformer backend.
For a guide that demonstrates the process of running T5-3B and GPT-J 6B models in optimized inference using NVIDIA Triton with the FasterTransformer, see Deploying GPT-J and T5 with NVIDIA Triton Inference Server.
