NVIDIA DGX SuperPOD trains BERT-Large in just 47 minutes, and trains GPT-2 8B, the largest Transformer Network Ever with 8.3Bn parameters
Conversational AI is an essential building block of human interactions with intelligent machines and applications – from robots and cars, to home assistants and mobile apps. Getting computers to understand human languages, with all their nuances, and respond appropriately has long been a “holy grail” of AI researchers. But building systems with true natural language processing (NLP) capabilities was impossible before the arrival of modern AI techniques powered by accelerated computing.
We, humans, have language superpowers, imparting both nuance and broader meaning as we communicate. While there have been many natural language processing approaches, human-like language ability has remained an elusive goal for AI. With the arrival of massive Transformer-based language models like BERT (Bidirectional Encoder Representations from Transformer), and 1 billion-plus parameter GPT-2 (Generative Pretrained Transformer 2) models, we are seeing rapid progress on difficult language understanding tasks.
In this blog, we’ll cover the latest advances at NVIDIA on two state-of-the-art NLP networks: BERT, and an 8.3 billion parameter version of a GPT-2 model known as GPT-2 8B, the largest Transformer-based network ever trained. We’ll also cover recent GPU performance records that show why GPUs excel as an infrastructure platform for these state-of-the-art models.
BERT Sparks New Wave of Accurate Language Models
BERT can be fine-tuned for many NLP tasks. It’s ideal for language understanding tasks like translation, Q&A, sentiment analysis, and sentence classification. BERT and models based on the Transformer architecture, like XLNet and RoBERTa, have matched or even exceeded the performance of humans on popular benchmark tests like SQuAD (for question-and-answer evaluation) and GLUE (for general language understanding across a diverse set of tasks).
A key advantage of BERT is that it doesn’t need to be pre-trained with labeled data, so it can learn using any plain text. This advantage opens the door to massive datasets, which in turn further improves the state-of-the-art accuracy. For example, BERT is generally pre-trained on a concatenation of BooksCorpus (800 million words) and the English Wikipedia (2.5 billion words), to form a total dataset of 3.3 billion words.
Model complexity is another attribute of Transformer-based networks that drives the accuracy of NLP. Comparing two different versions of BERT reveals a correlation between model size and performance: BERTBASE was created with 110 million parameters while BERT-Large, achieved an average of 3% improvement in GLUE scores with 340 million parameters. These models are expected to continue to grow to improve language accuracy.
NVIDIA Tensor Core GPUs Train BERT in Less Than An Hour
The NVIDIA DGX SuperPOD with 92 DGX-2H nodes set a new record by training BERT-Large in just 47 minutes. This record was set using 1,472 V100 SXM3-32GB 450W GPUs and 8 Mellanox Infiniband compute adapters per node, running PyTorch with Automatic Mixed Precision to accelerate throughput, using the training recipe in this paper. For researchers with access to just a single node, a DGX-2 server with 16 V100s trained BERT-Large in under 3 days. The table below demonstrates the time to train BERT-Large for various numbers of GPUs and shows efficient scaling as the number of nodes increases:
BERT-Large Training Times on GPUs
| Time | System | Number of Nodes | Number of V100 GPUs |
| 47 min | DGX SuperPOD | 92 x DGX-2H | 1,472 |
| 67 min | DGX SuperPOD | 64 x DGX-2H | 1,024 |
| 236 min | DGX SuperPOD | 16 x DGX-2H | 256 |
Running on a DGX SuperPOD, 64 nodes achieves 88% scaling efficiency versus 16 nodes on training BERT-Large. GPU performance continues to scale well to further achieve the 92-node, 47 minute record.
A single DGX-2H node features 2 petaFLOPs of AI computing capability to process complex models. The large model size of BERT requires a massive amount of memory, and each DGX-2H node provides 0.5TB of high bandwidth GPU memory for a total of 46TB for the entire DGX SuperPOD cluster for this run. NVIDIA interconnect technologies like NVLink, NVSwitch and Mellanox Infiniband allow high-bandwidth communication for efficient scaling. The combination of GPUs with plenty of computing power and high-bandwidth access to lots of DRAM, and fast interconnect technologies, makes the NVIDIA data center platform optimal for dramatically accelerating complex networks like BERT.
GPT-2 8B: The Largest Transformer Based Language Model Ever
Another category of Transformer-based language models is used for generative language modeling. These models are designed to predict and generate text (e.g.- write the next sentence in a document given the initial paragraph). Recently, the 1.5 billion parameter GPT-2 model showed that scaling to larger generative sizes, with unlabeled datasets even larger than those used by BERT, results in state-of-the-art models that generate coherent, and meaningful text.
Exploding Model Complexity – Number of Parameters by Network
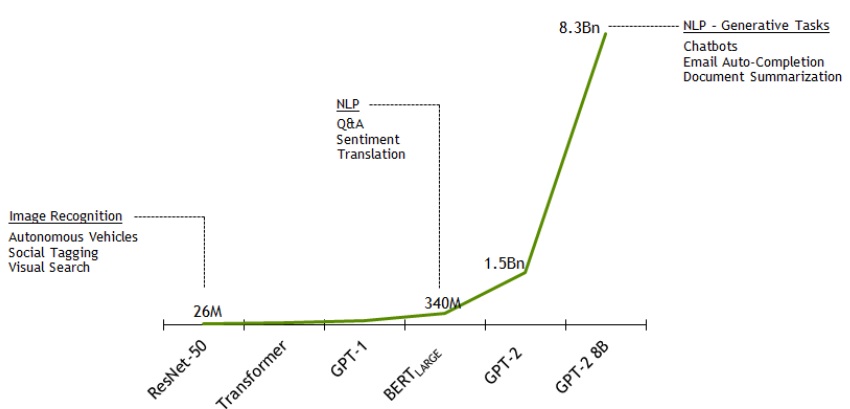
To investigate these enormous billion-plus Transformer-based networks, NVIDIA Research launched Project Megatron. This is an effort to create the largest Transformer models for state-of-the-art NLP. The 1.5 billion parameter GPT-2 model was scaled to an even larger 8.3 billion parameter transformer language model: GPT-2 8B. The model was trained using native PyTorch with 8-way model parallelism and 64-way data parallelism on 512 GPUs. GPT-2 8B is the largest Transformer-based language model ever trained, at 24x the size of BERT and 5.6x the size of GPT-2.
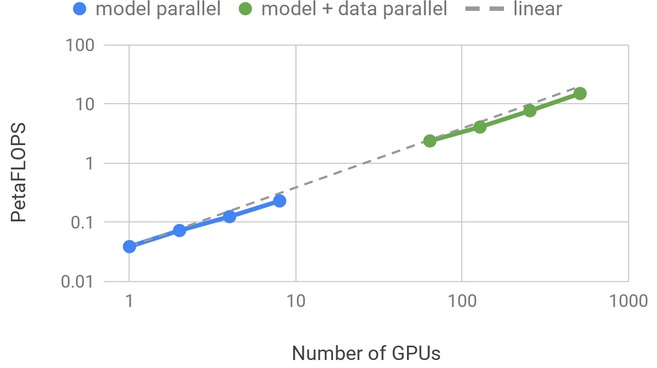
The experiments were conducted on NVIDIA’s DGX SuperPOD, with a baseline model of 1.2 billion parameters, which fits on a single V100 GPU. Running this baseline model’s end-to-end training pipeline on a single GPU achieves 39 TeraFLOPS, which is 30% of the theoretical peak FLOPS for this GPU. Scaling the model to 8.3 billion parameters on 512 GPUs with 8-way model parallelism, the NVIDIA team achieved up to 15.1 PetaFLOPS sustained performance over the entire application and reached 76% scaling efficiency compared to baseline.
Model parallelism inherently carries some overhead, which impacted the scaling efficiency slightly when compared to BERT which can run on a single GPU and does not need any model parallelism. The figure below shows scaling results and more information about the technical details can be found on a separate blog post.
Compute Performance and Scaling Efficiency
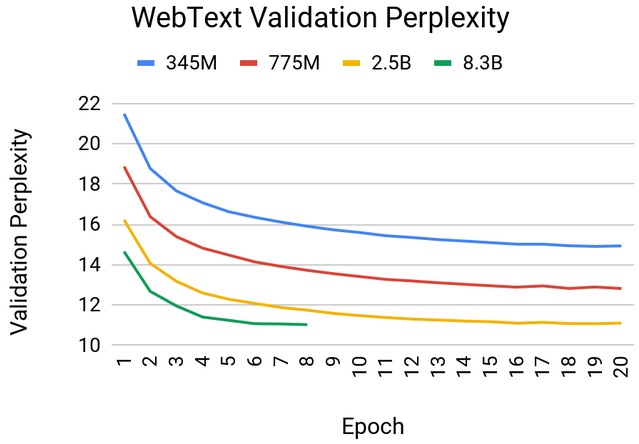
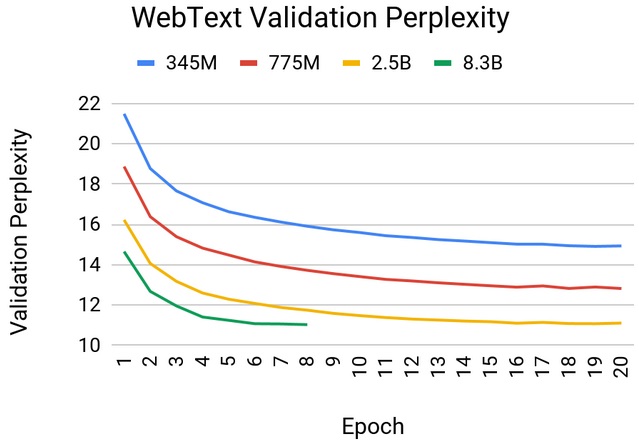
 The GPT-2 models were trained on a 37GB WebText dataset downloaded from outbound Reddit links. The figure below shows WebText validation perplexity as a function of the number of epochs for different model sizes. We find empirically that larger models train faster and lead to better results (lower validation perplexities).
The GPT-2 models were trained on a 37GB WebText dataset downloaded from outbound Reddit links. The figure below shows WebText validation perplexity as a function of the number of epochs for different model sizes. We find empirically that larger models train faster and lead to better results (lower validation perplexities).
Similar behavior is observed when the models are evaluated on the wikitext-103 dataset. The increase to 8.3 billion parameters resulted in a noticeable improvement in accuracy compared to smaller models and achieved a wikitext perplexity of 17.41. This surpasses previous results on the wikitext test data set by Transformer-xl. However, the largest 8.3 billion parameter model begins to overfit after about six epochs of training, which can be mitigated by moving to even larger scale problems and datasets, similar to those used in recent papers like XLNet and RoBERTa.
Webtext Validation Perplexity vs Epochs for Various GPT-2 Model Sizes
The Future of Conversational AI on the NVIDIA Platform
What drives the massive performance requirements of Transformer-based language networks like BERT and GPT-2 8B is their sheer complexity as well as pre-training on enormous datasets. The combination needs a robust computing platform to handle all the necessary computations to drive both fast execution and accuracy. The fact that these models can work on massive unlabeled datasets have made them a hub of innovation for modern NLP and by extension a strong choice for the coming wave of intelligent assistants with conversational AI applications across many use cases.
The NVIDIA platform with its Tensor Core architecture provides the programmability to accelerate the full diversity of modern AI including Transformer based models. In addition data center scale design and optimizations of DGX SuperPOD combined with software libraries and direct support for leading AI frameworks provides a seamless end-to-end platform for developers to take on the most daunting NLP tasks.
Continuous optimizations to accelerate training of BERT and Transformer for GPUs on multiple frameworks are freely available on NGC, NVIDIA’s hub for accelerated software.
NVIDIA TensorRT includes optimizations for running real-time inference on BERT and large Transformer based models. To learn more, check out our “Real Time BERT Inference for Conversational AI” blog. NVIDIA’s BERT GitHub repository has code today to reproduce the single-node training performance quoted in this blog, and in the near future the repository will be updated with the scripts necessary to reproduce the large-scale training performance numbers. For the NVIDIA Research team’s NLP code on Project Megatron, head over to the Megatron Language Model GitHub repository.