Transformers are one of the most influential AI model architectures today and are shaping the direction of future AI R&D. First invented as a tool for natural language processing (NLP), transformers are now used in almost every AI task, including computer vision, automatic speech recognition, molecular structure classification, and financial data processing.
In Korea, Kakao Brain has developed a highly accurate large language model (LLM), KoGPT, which is based on the transformer architecture. It trained on a large Korean dataset and successfully optimized it using NVIDIA FasterTransformer.
In this post, we cover how NVIDIA and Kakao Brain have optimized KoGPT with FasterTransformer.
Introduction to FasterTransformer
The transformer layer is currently the most widely used deep learning architecture in the field of deep learning. It originated in NLP and is now expanding its applications beyond language to vision, speech, and generative AI.
One of the most popular AI models in NLP is the family of GPT models. GPTs are LLMs developed by OpenAI that stack multiple layers of so-called decoder blocks from the transformer model architecture. For example, GPT-3 is an LLM with hundreds of billions of parameters that can agglomerate a huge amount of information like a giant encyclopedia.
However, training these LLMs poses several challenges:
- These LLMs occupy a significant amount of memory, which may exceed the capacity of a single GPU.
- Training and inference can take a considerable amount of time due to the massive computational effort required. Therefore, you must optimize every level of the stack: algorithm, software, and hardware.
The NVIDIA NeMo framework and FasterTransformer enable faster training and inference for LLMs with hundreds of billions of parameters.
Optimizations in FasterTransformer
FasterTransformer is a library that implements an inference acceleration engine for large transformer models using the model parallelization (tensor parallelism and pipeline parallelism) methods described earlier. FasterTransformer was developed to minimize latency and maximize throughput compared to previously available deep learning frameworks.
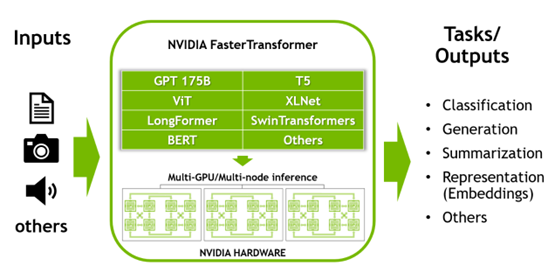
FasterTransformer provides the optimized decoder and encoder blocks of the transformer model. It is written in C++/CUDA and has APIs for the TensorFlow, PyTorch, and Triton Backend frameworks. It comes with sample code to demonstrate its main features.
FasterTransformer is open source. It already supports many models, such as GPT-3, GPT-J, GPT-NeoX, BERT, ViT, Swin Transformer, Longformer, T5, XLNet, and BLOOM. Support for new models is constantly being added. It also supports prompt learning techniques. For more information, see the latest support matrix.
As previously stated, FasterTransformer enables a faster inference pipeline with lower latency and higher output than other deep learning frameworks. Here are some of the optimization techniques used in FasterTransformer:
- Layer fusion: This technique combines multiple layers into a single layer that accelerates inference computation by reducing data transmission and increasing computational intensity. Examples of such acceleration are bias plus layer normalization, bias plus activation, bias plus softmax, and fusion of the three transpose matrices of the attention layer.
- Multi-head attention acceleration: The multi-head attention computes the relationship between tokens in a sequence, requiring a large number of computations and memory copies. FasterTransformer maintains a data cache (K/V cache) to reduce computations and minimizes the size of memory transfers using a fused kernel.
- GEMM kernel autotuning: Matrix multiplication is the most common and heavy operation in transformer-based models. FasterTransformer uses the functionality provided by the cuBLAS and CUTLASS libraries to execute this operation. The matrix multiplication operation can have different low-level implementations at the hardware level. FasterTransformer performs real-time benchmarks on the parameters of the model (attachment layer, size, number of attachment heads, hidden layer size, and so on) and input data. It selects the most appropriate functions and parameters.
- Lower precision: FasterTransformer supports lower-precision data types, such as FP16, BF16, and INT8. Operations on these data types can be accelerated by Tensor Cores on the recent NVIDIA GPUs (after the NVIDIA Volta architecture). In particular, the NVIDIA Hopper GPUs can run specialized hardware, such as the transformer engine.
Introduction to KoGPT

Kakao Brain’s KoGPT lexically and contextually understands the Korean language and generates sentences based on user intent. With KoGPT, users can perform various tasks related to the Korean language, such as determining the sentiment of a given sentence, predicting a summary or conclusion, answering a question, or generating the next sentence. It can also handle high-level language tasks such as machine reading, machine translation, writing, and sentiment analysis in various fields.
Performance of KoGPT with FasterTransformer
Kakao Brain wanted to run KoGPT, a GPT-3-based language model serving implemented using HuggingFace. Speed was not an issue when training, as performance was more important. But when it came to serving, speed became a major issue. The slower the inference speed, the more servers that had to be dedicated to the service. It increased exponentially, which lead to higher operational costs.
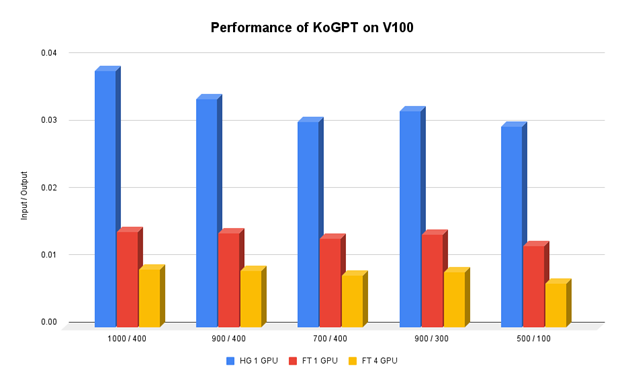
The team at Kakao Brain tried to find and apply various methods to optimize the inference speed of GPT-3 but could not make much improvement. It was only after adopting NVIDIA FasterTransformer that the team found a significant improvement in the inference speed. The inference speed varies depending on the number of input and output tokens but on average, the team improved the speed of inference up to 400% over the existing speed on one NVIDIA V100 GPU.
FasterTransformer also supports tensor and pipeline parallelism. When using four V100 GPUs, the team made an inference speedup of over 1100% over the baseline.
Summary
NVIDIA FasterTransformer made it easy for KoGPT to overcome the technical challenges the team had to face before launching as a service. The Kakao Brain ML Optimization team improved the total cost of ownership (TCO) by more than 15% by serving more requests on the same hardware.
For more information about Kakao Brain’s Korean LLM, KoGPT, and Korean AI chatbot KoChat GPT, see the Kakao website.
