
We are excited to introduce the DeepSpeed- and Megatron-powered Megatron-Turing Natural Language Generation model (MT-NLG), the largest and the most powerful monolithic transformer language model trained to date, with 530 billion parameters. It is the result of a joint effort between Microsoft and NVIDIA to advance the state of the art in AI for natural language generation.
As the successor to Turing NLG 17B and Megatron-LM, MT-NLG has 3x the number of parameters compared to the existing largest model of this type and demonstrates unmatched accuracy in a broad set of natural language tasks such as:
- Completion prediction
- Reading comprehension
- Commonsense reasoning
- Natural language inferences
- Word sense disambiguation
The 105-layer, transformer-based MT-NLG improved upon the prior state-of-the-art models in zero-, one-, and few-shot settings and set the new standard for large-scale language models in both model scale and quality.
Large-scale language models
Transformer-based language models in natural language processing (NLP) have driven rapid progress in recent years fueled by computation at scale, large datasets, and advanced algorithms and software to train these models.
Language models with large numbers of parameters, more data, and more training time acquire a richer, more nuanced understanding of language. As a result, they generalize well as effective zero– or few-shot learners, with high accuracy on many NLP tasks and datasets. Exciting downstream applications include summarization, automatic dialogue generation, translation, semantic search, and code autocompletion. It’s no surprise that the number of parameters in state-of-the-art NLP models have grown at an exponential rate (Figure 1).
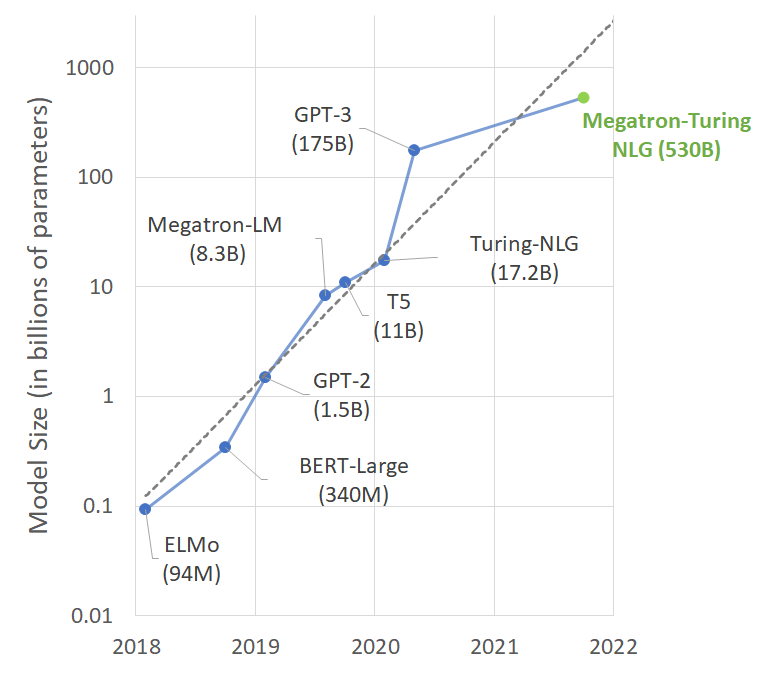
Training such models, however, is challenging for two main reasons:
- It is no longer possible to fit the parameters of these models in the memory of even the largest GPU.
- The large number of compute operations required can result in unrealistically long training times, if special attention is not paid to optimizing the algorithms, software, and hardware stack all together.
Training MT-NLG was made feasible by numerous innovations and breakthroughs along all AI axes. For example, working closely together, NVIDIA and Microsoft achieved an unprecedented training efficiency by converging a state-of-the-art GPU-accelerated training infrastructure with a cutting-edge distributed learning software stack. We built high-quality, natural language training corpora with hundreds of billions of tokens, and co-developed training recipes to improve optimization efficiency and stability.
In this post, we elaborate on each aspect of the training and describe our methods as well as results.
Large-scale training infrastructure
Powered by NVIDIA A100 Tensor Core GPUs and HDR InfiniBand networking, state-of-the-art supercomputing clusters such as the NVIDIA Selene and Microsoft Azure NDv4 have enough compute power to train models with trillions of parameters within a reasonable timeframe. However, achieving the full potential of these supercomputers requires parallelism across thousands of GPUs, efficient and scalable on both memory and compute.
In isolation, existing parallelism strategies such as data, pipeline, or tensor-slicing have trade-offs in memory and compute efficiency and cannot be used to train models at this scale.
- Data parallelism achieves good compute efficiency, but it replicates model states and cannot leverage aggregate distributed memory.
- Tensor-slicing requires significant communication between GPUs that limits compute efficiency beyond a single node where high-bandwidth NVLink is not available.
- Pipeline parallelism can scale efficiently across nodes. However, to be compute –efficient, it requires large batch sizes, coarse grain parallelism, and perfect load balancing, which is not possible at scale.
Software design
Through a collaboration between NVIDIA Megatron-LM and Microsoft DeepSpeed, we created an efficient and scalable 3D parallel system capable of combining data, pipeline, and tensor-slicing based parallelism together to address these challenges.
By combining tensor-slicing and pipeline parallelism, we can operate them within the regime where they are most effective. More specifically, the system uses tensor-slicing from Megatron-LM to scale the model within a node and uses pipeline parallelism from DeepSpeed to scale the model across nodes.
For example, for the 530 billion model, each model replica spans 280 NVIDIA A100 GPUs, with 8-way tensor-slicing within a node and 35-way pipeline parallelism across nodes. We then use data parallelism from DeepSpeed to scale out further to thousands of GPUs.
Hardware system
Model training is done with mixed precision on the NVIDIA DGX SuperPOD-based Selene supercomputer powered by 560 DGX A100 servers networked with HDR InfiniBand in a full fat tree configuration. Each DGX A100 has eight NVIDIA A100 80GB Tensor Core GPUs, fully connected to each other by NVLink and NVSwitch. A similar reference architecture is used by Microsoft for Azure NDv4 cloud supercomputers.
System throughput
We considered the end-to-end throughput of our system for the 530 billion parameters model with batch size 1920 on 280, 350, and 420 DGX A100 servers on Selene. We observed iteration time of 60.1, 50.2, and 44.4 seconds, respectively. These correspond to 126, 121, and 113 teraFLOP/s per GPU, respectively.
Training dataset and model configuration
We used the architecture of the transformer decoder, which is a left-to-right generative transformer-based language model consisting of 530 billion parameters. The number of layers, hidden dimensions, and attention heads are 105, 20480, and 128, respectively.
We used an 8-way tensor and 35-way pipeline parallelism. The sequence length is 2048 and the global batch size is 1920. Over the first 12 billion training tokens, we gradually increased the batch size by 32, starting at 32, until we reach the final batch size of 1920. We used one billion tokens for the learning rate warmup in our training.
We largely built our training dataset based on prior work, The Pile. First, we selected the subset of datasets (the top 11 rows in Figure 2) from The Pile that we found to be of the highest relative quality. Then, following a similar approach as that used to generate Pile-CC, we downloaded and filtered two recent Common Crawl (CC) snapshots.
The steps we took for the CC data included text extraction from raw HTML files, scoring extracted documents using a classifier trained on high-quality data, and filtering documents according to their scores. To diversify the training, we also collected the RealNews and CC-Stories datasets.
Document deduplication is necessary in building training datasets because the same content can be present in multiple documents of different datasets. We used a fuzzy deduplication process at the document level using min-hash LSH to compute a sparse document graph and the connected components in it to identify duplicate documents.
We then used a priority order based on the quality of the datasets when selecting a representative document from the duplicate documents in each connected component. Finally, we used n-gram based filtering to remove downstream task data from the training datasets to avoid contamination.
We ended with a set of 15 datasets consisting of a total of 339 billion tokens. During training, we opted to blend the datasets into heterogeneous batches according to variable sampling weights given in Figure 2, with an emphasis on higher-quality datasets. We trained the model on 270 billion tokens.
| Dataset | Tokens (billions) | Weights (%) | Epochs |
| Books3 | 25.7 | 14.3 | 1.5 |
| OpenWebText2 | 14.8 | 19.3 | 3.6 |
| Stack Exchange | 11.6 | 5.7 | 1.4 |
| PubMed Abstracts | 4.4 | 2.9 | 1.8 |
| Wikipedia | 4.2 | 4.8 | 3.2 |
| Gutenberg (PG-19) | 2.7 | 0.9 | 0.9 |
| BookCorpus2 | 1.5 | 1.0 | 1.8 |
| NIH ExPorter | 0.3 | 0.2 | 1.8 |
| Pile-CC | 49.8 | 9.4 | 0.5 |
| ArXiv | 20.8 | 1.4 | 0.2 |
| GitHub | 24.3 | 1.6 | 0.2 |
| CC-2020-50 | 68.7 | 13.0 | 0.5 |
| CC-2021-04 | 82.6 | 15.7 | 0.5 |
| RealNews | 21.9 | 9.0 | 1.1 |
| CC-Stories | 5.3 | 0.9 | 0.5 |
Results and achievements
Recent work in language models (LM) has demonstrated that a strong pretrained model can often perform competitively in a wide range of NLP tasks without finetuning.
To understand how scaling up LMs strengthens their zero-shot or few-shot learning capabilities, we evaluated MT-NLG and demonstrate that it establishes new top results across several categories of NLP tasks. To ensure the evaluation was comprehensive, we selected eight tasks spanning five different areas:
- In the text prediction task LAMBADA, the model predicts the last word of a given paragraph.
- In the reading comprehension tasks RACE-h and BoolQ, the model generates answers to questions based on a given paragraph.
- In the commonsense reasoning tasks PiQA, HellaSwag, and Winogrande, each required some level of commonsense knowledge beyond statistical patterns of language to solve.
- For natural language inference, two hard benchmarks, ANLI-R2 and HANS target the typical failure cases of past models.
- The word sense disambiguation task WiC evaluates polysemy understanding from context.
To encourage reproducibility, we based our evaluation setting on the open-source project lm-evaluation-harness and made task-specific changes as appropriate to align our setting more closely with prior work. We evaluated MT-NLG in zero-, one-, and few-shot settings without performing search for the optimal number of shots.
Table 2 shows the results for the accuracy metric. We ran the evaluation on the test set if it was publicly available; otherwise, we reported numbers on the dev set. This led to reporting LAMBADA, RACE-h, and ANLI-R2 on test sets and other tasks on dev sets.
| Tasks | Zero-shot | One-shot | Few-shot |
| Lambada | 0.766* | 0.731* | 0.872* |
| BoolQ | 0.782 | 0.825 | 0.848 |
| RACE-h | 0.479 | 0.484 | 0.479 |
| PiQA | 0.820* | 0.810* | 0.832* |
| HellaSwag | 0.802 | 0.802 | 0.824 |
| WinoGrande | 0.730 | 0.737 | 0.789 |
| ANLI-R2 | 0.366 | 0.397 | 0.396 |
| HANS | 0.607 | 0.649 | 0.702 |
| WiC | 0.486 | 0.513 | 0.585 |
Take few-shot performance as an example. We observed encouraging improvements compared to prior published work. This was especially true for tasks involving comparison or finding relations between two sentences (for example, WiC and ANLI), a task category that was challenging for prior models. We observed similar improvements for most tasks in zero-shot and one-shot evaluation as well. We should also note that this model is trained on fewer tokens than previous models, showing the ability of larger models to learn even faster.
For the HANS dataset, we did not find any baseline that reports dataset-wide metrics. According to the analysis by the HANS paper, BERT baselines trained on MNLI performs near-perfect on half of its subcategories while near-zero on the other half. That indicates that they are strongly dependent on the spurious syntactic heuristics identified by the paper.
While our model still struggles, it predicts more than half the cases correct in zero-shot and improves even further when we present as few as one- and four-shots. Finally, in zero-, one-, and few-shot settings, our model established top results on the PiQA dev set and LAMBADA test set.
In addition to reporting aggregate metrics on benchmark tasks, we also qualitatively analyzed model outputs and have intriguing findings (Figure 4). We observed that the model can infer basic mathematical operations from context (sample 1), even when the symbols are badly obfuscated (sample 2). While far from claiming numeracy, the model seems to go beyond only memorization for arithmetic.
We also show samples (the last row in Figure 4) from the HANS task where we posed the task containing simple syntactic structures as a question and prompted the model for an answer. Despite the structures being simple, existing natural language inference (NLI) models often have a hard time with such inputs. Fine-tuned models often pick up spurious associations between certain syntactic structures and entailment relations from systemic biases in NLI datasets. MT-NLG performs competitively in such cases without finetuning.
| Tasks | Sample 1 | Sample 2 |
| Inferring mathematical operations | Prompt: Q: 11 # 2 = ? A: 5.5 Q: 18 # 9 = ? A: 2 Q: 35 # 4 = ? A: 8.75 Q: 27 # 9 = ? A: 3 Q: 75 # 6 = ? A: MT-NLG: 12.5 Q: 45 # 5 = ? A: 9 Q: 18 # 6 = ? A: 3 | Prompt: Q: 11 $^% 2 = ? A: 22 Q: 3 $^% 9 = ? A: 27 Q: 12 $^% 4 = ? A: 48 Q: 7 $^% 7 = ? A: 49 Q: 8 $^% 5 = ? A: MT-NLG: 40 Q: 9 $^% 6 = ? A: 54 Q: 10 $^% 5 = ? A: 50 |
| Natural language inference on different syntactic structures | Prompt: The banker forgot that the judge advised the professors. Question: The judge advised the professors. True or False? Answer: MT-NLG: True. The banker forgot that the judge advised the professors. | Prompt: Famous professors supported the secretary. Question: Professors supported the secretary. True or False? Answer: MT-NLG: True. The secretary was supported by famous professors. |
Bias in language models
While giant language models are advancing the state of the art on language generation, they also suffer from issues such as bias and toxicity. Understanding and removing these problems in language models is under active research by the AI community, including at Microsoft and NVIDIA.
Our observations with MT-NLG are that the model picks up stereotypes and biases from the data on which it is trained. Microsoft and NVIDIA are committed to working on addressing this problem. We encourage continued research to help in quantifying the bias of the model.
In addition, any use of MT-NLG in production scenarios must ensure that proper measures are put in place to mitigate and minimize potential harm to users. All work should follow such principles as those found in the Microsoft Responsible AI Principles. Those principles emphasize that fairness, reliability and safety, privacy and security, inclusiveness, transparency, and accountability are considered to be the key cornerstones of a responsible and trustworthy approach to development and use of AI.
Conclusion
We live in a time where AI advancements are far outpacing Moore’s law. We continue to see more computation power being made available with newer generations of GPUs, interconnected at lightning speeds. At the same time, we continue to see hyperscaling of AI models leading to better performance, with seemingly no end in sight.
Marrying these two trends together are software innovations that push the boundaries of optimization and efficiency. MT-NLG is an example of what is possible when supercomputers like NVIDIA Selene or Microsoft Azure NDv4 are used with software breakthroughs of Megatron-LM and DeepSpeed to train large language AI models.
The quality and results that we have obtained today are a big step forward in the journey towards unlocking the full promise of AI in natural language. The innovations of DeepSpeed and Megatron-LM will benefit existing and future AI model development and make large AI models cheaper and faster to train.
We look forward to how MT-NLG will shape tomorrow’s products and motivate the community to push the boundaries of NLP even further. The journey is long and far from complete, but we are excited by what is possible and what lies ahead.
Contributors
This project was made possible by the contributions of the following people:
NVIDIA: Mostofa Patwary, Mohammad Shoeybi, Patrick LeGresley, Shrimai Prabhumoye, Jared Casper, Vijay Korthikanti, Vartika Singh, Julie Bernauer, Michael Houston, and Bryan Catanzaro.
Microsoft: Shaden Smith, Brandon Norick, Samyam Rajbhandari, Zhun Liu, George Zerveas, Elton Zhang, Reza Yazdani Aminabadi, Xia Song, Yuxiong He, Jeffrey Zhu, Jennifer Cruzan, Umesh Madan, Luis Vargas, and Saurabh Tiwary.
