大型语言模型 (LLM) 的出现革新了人工智能领域,为与数字世界的交互提供了全新的方式。尽管 LLM 通常能够提供良好的通用解决方案,但为了更好地支持特定领域和任务,它们往往需要进行调整。
AI 编码助手(或代码 LLM)已成为帮助实现这一目标的一个领域。到 2025 年,80% 的产品开发生命周期将使用 生成式 AI 进行代码生成,开发者将充当后端和前端组件及集成的验证者和编排者。您可以调整用于代码任务的 LLM,简化开发者的工作流程,并降低新手编程人员的门槛。Code LLM 不仅可以生成代码,还可以填充缺失的代码、添加文档,并提供解决难题的提示。
本文将介绍如何部署端到端代码 LLM,包括具体的提示指南、优化技术和客户端 – 服务器部署。我们使用NVIDIA Triton 推理服务器并使用NVIDIA TensorRT-LLM,这是一个用于编译和优化用于推理的 LLM 的综合库。TensorRT-LLM 包含许多高级优化,同时提供直观的 Python API 来定义和构建新模型。
我们TensorRT-LLM 开源库加速 NVIDIA GPU 上最新 LLM 的推理性能。它用作 NVIDIA GPU 中 LLM 推理的优化主干NVIDIA NeMo,这是一种端到端框架,用于构建、自定义生成式 AI 应用并将其部署到生产环境中。NeMo 框架为生成式 AI 部署提供完整的容器,包括 TensorRT-LLM 和 NVIDIA Triton 推理服务器。它还包含在NVIDIA AI Enterprise中,这是一个生产级、安全且受支持的软件平台,可简化采用流程。
什么是 AI 辅助编码
程序员需要花费大量时间来寻找解决方法来解决常见问题,或浏览在线论坛,以更快地编写代码。AI 代码助手背后的关键理念是将程序员所需的信息放在他们正在编写的代码旁边。该工具会跟踪程序员正在处理的文件中的代码和评论,以及它链接到或在同一项目中已编辑的其他文件。它会将所有这些文本作为提示发送到 LLM。然后,它会预测程序员正在尝试执行的操作,并建议代码来完成此操作。
部署自己的 AI 编码助手
要部署自己的 AI 编码助手,您需要深度学习推理和 LLM 的基本知识,以及:
- 拥抱 Face 注册用户访问权限并基本熟悉 Transformer 库
- Python
- NVIDIA TensorRT-LLM 优化库
- 搭载 TensorRT-LLM 后端的 NVIDIA Triton
本教程使用 StarCoder,这是一个 155 亿个参数 LLM,使用 The Stack (v1。2)中的 80 多种编程语言进行训练。StarCoder 的基础模型使用来自 80 多种编程语言、GitHub 问题、Git Commits 和 Jupyter Notebooks 的 1 万亿个令牌进行训练。StarCoder 在其之上使用另外 350 亿个 Python 令牌进行了微调,最终形成了 StarCoder 模型。
针对用于解决特定问题的代码请求,StarCoder 可以从头开始生成代码。它还支持中间填充 (FIM) 或填充,这使得模型能够根据插入点周围的前缀和后缀代码生成代码(例如,单行填充、返回类型预测和文档字符串生成)。
代码 LLM 提示
本节介绍优化过程。StarCoder 在公共领域的代码库上进行了训练,因此可以生成多种语言的代码片段。LLM 的基于代码的提示是要求 LLM 以特定语言生成代码的提示。理想的提示应该具体清晰,为 LLM 提供足够的信息以生成正确答案。
例如,您可以发出以下通用提示:
Write a function that computes the square root。
# Use Newton's method,# where x_(n+1) = 1/2 * (x_n + (y/x_n))# y = number to find square root of# x_0 = first guess# epsilon = how close is close enough?# Implement this in a function called newton_sqrt that has three parameters# and returns one value. |
指定编程语言和输出将产生更好的结果。例如:
Write Python code to compute the square root and print the result。
# To find the square root of a number in Python, you can use the math library and its sqrt function:from math import sqrtnumber = float(input('Enter a number: '))square_root = sqrt(number)print(f'The square root of {number} is approximately {square_root:.2f}.') |
代码 LLM 的提示工程
提示工程包括提供代码块、单行代码或开发者评论,以改进特定用例的编码建议。在针对代码 LLM 的特定提示工程方面,有一些指南需要记住,包括代码片段和示例输出。
片段
通常,LLM 的上下文窗口大小有限。这对于代码 LLM 尤其重要,因为源代码通常由多个文件和长文本组成,通常不适合 LLM 上下文窗口。因此,代码 LLM 的提示工程需要在提示之前为源代码做额外的准备。这可以包括将文件拆分为较小的代码片段、选择最具代表性的代码示例,以及使用提示优化技术进一步减少输入令牌的数量。
添加示例输出
包含示例输出和导入指令的提示将产生最佳结果。
您将通过以下提示获得平均结果:
Write a function for calculating average water use per household。
添加示例将产生更好的结果:
Write a function for calculating average water use per household。Example output ["Smith", 20, "Lincoln", 30, "Simpson", 1500]
通过添加示例并指定导入说明,您的结果将更加出色:
Write a function for calculating average water use per household。Example input [['Last Name', 'Dishwasher', 'Shower', 'Yard'], ['Smith', 39, 52, 5], ['Lincoln', 25, 77, 8], ['Simpson', 28, 20, 0]]Example output ["Smith", 20, "Lincoln", 30, "Simpson", 1500]
实验
使用不同的提示,并在每个步骤中使用更精细的细节进行更新,以提高输出。例如:
Write a function for calculating average water use per household。Write a function for calculating average water use per household. Add penalties for dishwasher time。Write a Python function for calculating average water use per household. Add penalties for dishwasher time. Input is family name, address, and number of gallons per specific use。
流程概述
要使用 TensorRT-LLM 优化 LLM,您需要了解其架构,并确定它与哪个通用基础架构最相似。StarCoder 使用 GPT 架构,因此本教程基于 NVIDIA/TensorRT-LLM GPT 示例。
使用此目录中的转换器和构建脚本编译 StarCoder 并为硬件加速做好准备。请注意,分词器并非由 TensorRT-LLM 直接处理。但是,必须能够在定义的分词器系列中对其进行分类,以用于运行时以及在 Triton 中设置预处理和后处理步骤。
设置和构建 TensorRT-LLM
首先,克隆和构建 TensorRT-LLM 库。构建 TensorRT – LLM 并检索其所有依赖项的最简单方法是使用随附的 Dockerfile。这些命令拉取基础容器,并在容器内安装 TensorRT – LLM 所需的所有依赖项。然后,它会在容器内构建并安装 TensorRT – LLM 本身。
git lfs installgit clone -b release/0.7.1 https://github.com/NVIDIA/TensorRT-LLM.gitcd TensorRT-LLMgit submodule update --init --recursivemake -C docker release_build |
检索模型权重
从 Hugging Face 下载 StarCoder 模型,并将其放置在/examples目录。
cd examplesgit clone https://huggingface.co/bigcode/starcoder |
转换模型权重格式
在编译之前,需要将模型权重格式从 Hugging Face Transformer 转换为 FasterTransformer。
# Launch the Tensorrt-LLM containermake -C docker release_run LOCAL_USER=1cd examples/gptpython3 hf_gpt_convert.py -p 8 --model starcoder -i ../starcoder -o ./c-model/starcoder --tensor-parallelism 1 --storage-type float16 |
编译模型
下一步是使用上一步中转换的权重将模型编译为 TensorRT 引擎。编译有许多选项,例如精度和选择要启用的优化功能(例如动态批处理和 KV 缓存)。
python3 examples/gpt/build.py \ --model_dir examples/gpt/c-model/starcoder/1-gpu \ --dtype float16 \ --use_gpt_attention_plugin float16 \ --use_gemm_plugin float16 \ --remove_input_padding \ --use_inflight_batching \ --paged_kv_cache \ --output_dir examples/gpt/out |
运行模型
TensorRT-LLM 包含高度优化的 C++运行时,用于执行构建的 LLM 引擎和管理流程,例如从模型输出中采样令牌、管理 KV 缓存以及同时处理批处理请求。您可以直接使用该运行时在本地执行模型。
python3 examples/gpt/run.py --engine_dir=examples/gpt/out --max_output_len 100 --tokenizer examples/starcoder/starcoder --input_text "Write a function that computes the square root." |
您可以使用更复杂的提示进行实验,包括函数名称、参数和输出的定义。
python3 examples/gpt/run.py --engine_dir=examples/gpt/out --max_output_len 100 --tokenizer examples/starcoder/starcoder --input_text "X_train, y_train, X_test, y_test = train_test_split(X, y, test_size=0.1)# Train a logistic regression model, predict the labels on the test set and compute the accuracy score" |
在 NVIDIA Triton 上部署模型
我们建议使用 NVIDIA Triton 推理服务器,这是一个开源平台,可简化和加速 AI 推理工作负载的部署,以创建 LLM 的生产就绪型部署。这将有助于缩短设置和部署时间。适用于 TensorRT-LLM 的 Triton 推理服务器后端利用 TensorRT-LLM C++运行时实现快速推理执行,并包含 动态批处理 和 分页 KV 缓存。您可以通过 NVIDIA NGC 目录中访问 TensorRT-LLM 后端用作预构建容器的 Triton 推理服务器 。
首先,创建一个模型库,以便Triton可以读取模型和任何相关元数据。tensorrtllm_backend 存储库包含 all_models/inflight_batcher_llm/ 下适当模型存储库的骨架。该目录中有以下子文件夹,其中包含模型执行过程不同部分的构件:
/preprocessing和/postprocessing:包含适用于 Python 的 Triton 后端,用于在字符串和模型运行所用的标记 ID 之间进行转换,实现文本输入的标记化和模型输出的去标记化。/tensorrt_llm:用于存储您之前编译的模型引擎的子文件夹。/ensemble:定义模型集成,它将前三个组件连接在一起,并告诉 Triton 如何通过它们流动数据。
# After exiting the TensorRT-LLM docker containercd ..git clone -b release/0.7.1 \https://github.com/triton-inference-server/tensorrtllm_backend.gitcd tensorrtllm_backendcp ../TensorRT-LLM/examples/gpt/out/* all_models/inflight_batcher_llm/tensorrt_llm/1/ |
密切关注参数 kv_cache_free_gpu_mem_fraction,该参数用于在推理期间为 KV 缓存分配显存。此参数设置的数字介于 0 和 1 之间,并相应地分配 GPU 显存。将其设置为 1 将使 GPU 显存容量达到最大值。
在部署大型 LLM 或在单个 GPU 上运行多个 TensorRT-LLM 实例时,设置此参数尤为重要。请注意,默认值为 0.85.对于本教程中的 StarCoder,我们使用了 0。2 的值以避免 GPU 显存填充。
借助 KV 缓存,中间数据会被缓存和重复使用,从而避免重新计算。中间特征图被缓存并在下一次迭代中重复使用,而不是在每次迭代中重新计算完整的键值矩阵。这降低了解码机制的计算复杂性。KV 缓存的内存消耗可以轻松填充 TB 级数据,以用于生产级 LLM。
python3 tools/fill_template.py --in_place \ all_models/inflight_batcher_llm/tensorrt_llm/config.pbtxt \ decoupled_mode:true,engine_dir:/all_models/inflight_batcher_llm/tensorrt_llm/1,\max_tokens_in_paged_kv_cache:,batch_scheduler_policy:guaranteed_completion,kv_cache_free_gpu_mem_fraction:0.2,\max_num_sequences:4 |
另一个需要注意的重要参数是分词器。您需要指定合适的分词器及其最适合的类别类型,以定义 Triton 所需的预处理和后处理步骤。StarCoder 使用代码作为输入,而非句子,因此它具有唯一的分词和分隔符。
因此,有必要在配置文件中通过设置 StarCoder 分词器tokenizer_type 为自动和tokenizer_dir为/all_models/startcoder 。您可以通过调用fill_template.py或编辑config.pbtxt文件。
python tools/fill_template.py --in_place \ all_models/inflight_batcher_llm/preprocessing/config.pbtxt \ tokenizer_type:auto,tokenizer_dir:/all_models/startcoder python tools/fill_template.py --in_place \ all_models/inflight_batcher_llm/postprocessing/config.pbtxt \ tokenizer_type:auto,tokenizer_dir:/all_models/startcoder |
启动 Triton
如要启动 Triton,请先启动 Docker 容器,然后通过设置world_size参数。
docker run -it --rm --gpus all --network host --shm-size=1g \-v $(pwd)/all_models:/all_models \-v $(pwd)/scripts:/opt/scripts \nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3 # Log in to huggingface-cli to get tokenizerhuggingface-cli login --token ***** # Install python dependenciespip install sentencepiece protobuf # Launch Serverpython /opt/scripts/launch_triton_server.py --model_repo /all_models/inflight_batcher_llm --world_size 1 |
发送请求
要向正在运行的服务器发送请求并与之交互,您可以使用 Triton 客户端库 或将 HTTP 请求发送到 生成的端点。
要开始处理简单请求,请使用以下 curl 命令将 HTTP 请求发送到生成的端点:
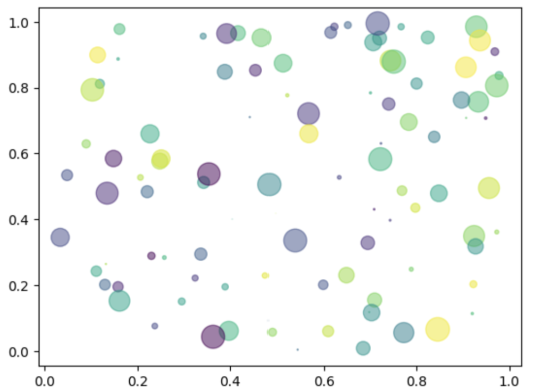
curl -X POST localhost:8000/v2/models/ensemble/generate -d \'{"text_input": "write in python code that plots in a image circles with different radiuses","parameters": {"max_tokens": 100,"bad_words":[""],"stop_words":[""]}}' |
您还可以使用功能齐全的客户端脚本与正在运行的服务器进行交互。
运行上述命令将生成以下代码。生成的图形如图 1 所示。
import numpy as npimport matplotlib.pyplot as plt# Fixing random state for reproducibilitynp.random.seed(19680801)N = 100r0 = 0.6x = np.random.rand(N)y = np.random.rand(N)area = np.pi * (10 * np.random.rand(N))**2 # 0 to 10 point radiusesc = np.random.rand(N)plt.scatter(x, y, s=area, c=c, alpha=0.5)plt.show() |
开始使用
NVIDIA TensorRT-LLM 和 NVIDIA Triton 为众多流行的 LLM 架构提供了基准支持,使得部署、优化和运行各种代码 LLM 变得轻松。要开始使用,请下载并设置 NVIDIA/TensorRT-LLM GitHub 上的开源库,并尝试使用不同的 LLM 示例。此外,您还可以下载 StarCoder 模型,并按照此博文中的步骤进行动手实践。



