本周,我们发布了模型功能 DBRX,这是由 Databricks 开发的最先进的大型语言模型(LLM)。DBRX 在编程和编码任务方面展示出了强大的实力,擅长使用 Python 等语言处理专门的主题和编写特定的算法。此外,它还可以应用于文本完成任务和少回合交互。DBRX 的长上下文能力可用于 RAG 系统,以提高准确性和保真度。
模型对细粒度的使用 混合专家(MoE) 体系结构是它区别于其他模型的一个关键特性。该 MoE 架构通过利用一组专门的“专家”网络,擅长处理复杂任务。在推理过程中,MoE 使用学习的门控机制,基于输入数据动态选择并组合这些专家网络的输出,以实现更好的性能。
这种门控机制将输入数据的不同部分路由到最相关的专家网络,使教育部能够有效地利用其集体专业知识并产生卓越的预测或输出。通过自适应地协调其组成网络的贡献,MoE 在有效利用计算资源的同时,在不同任务上实现了卓越的性能。
DBRX 细粒度 MoE 方法使用了更多更小的专家,从而提高了性能和效率。该体系结构共涉及 1320 亿个参数,在任何给定时间都有 360 亿个活动参数,通过使用 16 名专家进行管理,其中四名专家为每个处理的代币激活。
DBRX 针对延迟和吞吐量进行了优化,使用 NVIDIA TensorRT LLM。现在,它已经加入了二十多个流行的人工智能模型,这些模型由 NVIDIA NIM 微服务提供,旨在简化性能优化的部署。NIM 支持 NVIDIA AI Foundation 模型 和自定义模型的部署,使得 10 到 100 倍的企业应用程序开发人员能够为人工智能转型做出贡献。
NVIDIA 正与领先的模型构建商合作,在完全加速的堆栈上支持他们的模型。其中包括流行的型号,如 Llama3-70B、Llama3-8B、Gemma2B、Mixtral 8X22B 等。您可以访问 ai.nvidia.com,在企业应用程序中体验、定制和部署这些模型。
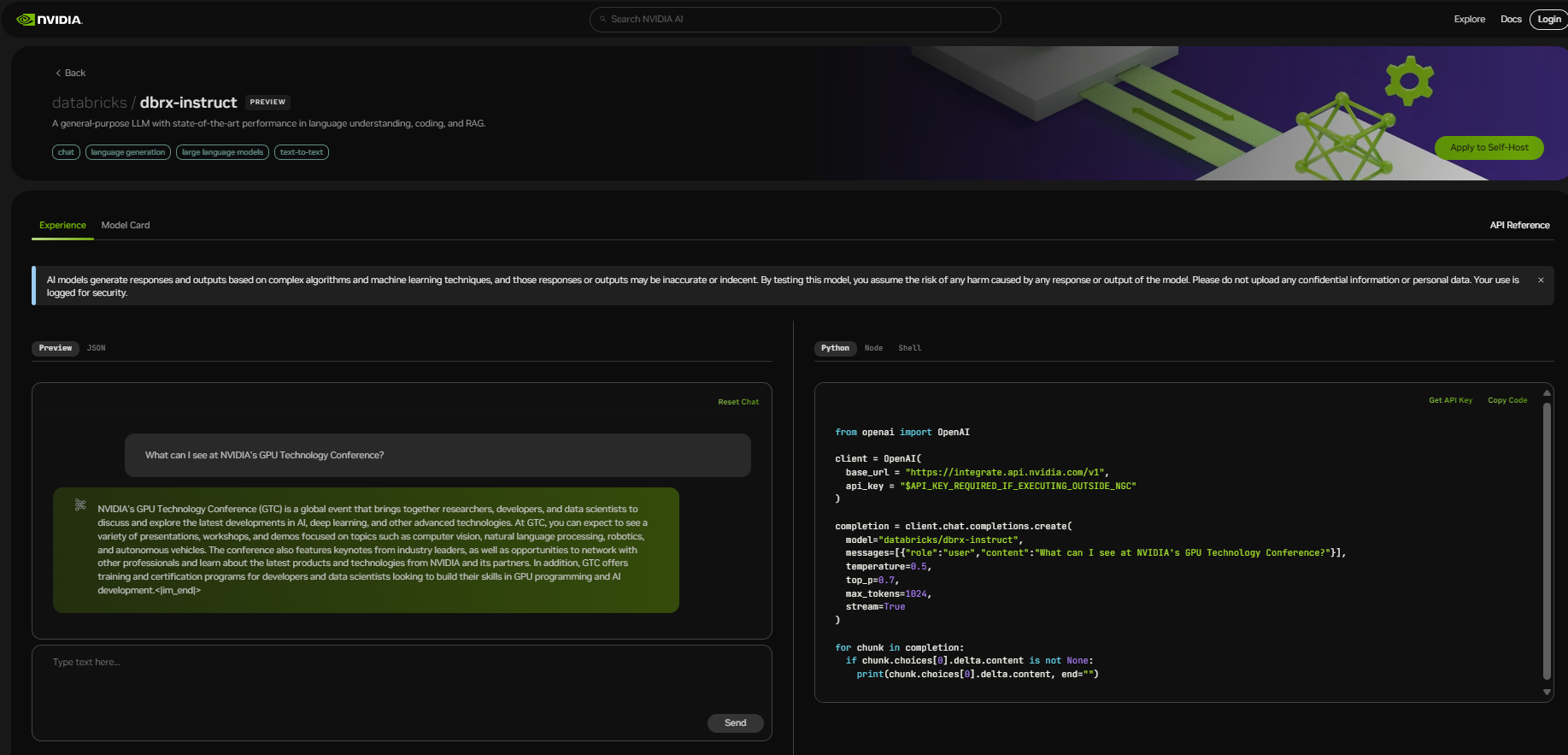
开始使用 DBRX
开始体验 DBRX,请访问 build.nvidia.com。使用免费的 NVIDIA 云积分,您可以开始大规模测试模型,并通过将应用程序连接到运行在完全加速堆栈上的 NVIDIA 托管 API 端点上来构建概念验证(POC)。