
이 포스팅은 NVIDIA의 인기 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델인 CUDA에 대한 아주 간략한 소개입니다. 2013년에 CUDA에 대한 쉬운 소개라는 이전 포스팅이 작성되어 많은 사랑을 받았으나 CUDA 프로그래밍이 더 쉬워지고 GPU가 훨씬 빨라졌기 때문에 업데이트된 (그리고 더 쉬운) 소개를 공유합니다.
CUDA C++는 CUDA로 대규모 병렬 애플리케이션을 만들 수 있는 방법 중 하나입니다. 강력한 C++ 프로그래밍 언어를 사용하여 GPU에서 실행되는 수천 개의 병렬 스레드로 가속화된 고성능 알고리즘을 개발할 수 있습니다. 많은 개발자가 이러한 방식으로 연산 및 대역폭을 많이 사용하는 애플리케이션을 가속화했으며, 여기에는 딥 러닝으로 알려진 인공 지능의 지속적인 혁명을 뒷받침하는 라이브러리와 프레임워크가 포함됩니다.
앞서 CUDA에 대한 소개를 들어보셨는데요. 이제 여러분의 애플리케이션에서 사용하는 방법을 알려드립니다. C 또는 C++ 프로그래머라면 이 블로그 포스팅이 좋은 시작이 될 것입니다. 이 과정을 따라하려면 CUDA 지원 GPU가 탑재된 컴퓨터(Windows, Mac 또는 Linux, NVIDIA GPU는 모두 가능) 또는 GPU가 탑재된 클라우드 인스턴스(AWS, Azure, IBM SoftLayer 및 기타 클라우드 서비스 제공업체에서 제공)가 필요합니다. 또한 무료로 제공되는 CUDA 툴킷이 설치되어 있어야 합니다. 클라우드의 GPU에서 실행되는 Jupyter 노트북으로 따라할 수도 있습니다.
시작해 봅시다!

간단하게 시작하기
각각 백만 개의 요소가 있는 두 배열의 요소를 추가하는 간단한 C++ 프로그램으로 시작하겠습니다.
#include <iostream>
#include <math.h>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20; // 1M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the CPU
add(N, x, y);
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}먼저 이 C++ 프로그램을 컴파일하고 실행합니다. 위의 코드를 파일에 넣고 add.cpp라는 이름으로 저장한 다음 C++ 컴파일러를 사용하여 컴파일합니다. 저는 Mac을 사용하고 있어서 clang++을 사용하고 있지만 Linux에서는 g++을, Windows에서는 MSVC를 사용할 수 있습니다.
> clang++ add.cpp -o add그런 다음 실행합니다:
> ./add
Max error: 0.000000(Windows에서는 실행 파일 이름을 add.exe로 지정하고 .\add로 실행할 수 있습니다.)
예상대로 합산에 오류가 없다고 출력한 다음 종료됩니다. 이제 이 계산을 GPU의 여러 코어에서 (병렬로) 실행합니다. 사실 첫 번째 단계를 수행하는 것은 꽤 쉽습니다.
먼저 add 함수를 GPU가 실행할 수 있는 함수, 즉 CUDA의 커널로 바꾸기만 하면 됩니다. 이렇게 하려면 함수에 __global__이라는 지정자를 추가하기만 하면 되는데, 이는 CUDA C++ 컴파일러에 이 함수가 GPU에서 실행되는 함수이며 CPU 코드에서 호출할 수 있음을 알려줍니다.
// CUDA Kernel function to add the elements of two arrays on the GPU
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}이러한 __global__ 함수를 커널이라고 하며, GPU에서 실행되는 코드는 흔히 디바이스 코드라고 하고 CPU에서 실행되는 코드는 호스트 코드라고 합니다.
CUDA의 메모리 할당
GPU에서 계산하려면 GPU에서 액세스할 수 있는 메모리를 할당해야 합니다. CUDA의 통합 메모리는 시스템의 모든 GPU와 CPU가 액세스할 수 있는 단일 메모리 공간을 제공하여 이를 쉽게 만듭니다. 통합 메모리에 데이터를 할당하려면 호스트(CPU) 코드 또는 디바이스(GPU) 코드에서 액세스할 수 있는 포인터를 반환하는 cudaMallocManaged()를 호출하면 됩니다. 데이터를 해제하려면 포인터를 cudaFree()로 전달하면 됩니다.
위 코드에서 new에 대한 호출을 cudaMallocManaged() 호출로 바꾸고 delete [] 에 대한 호출을 cudaFree에 대한 호출로 바꾸기만 하면 됩니다.
// Allocate Unified Memory -- accessible from CPU or GPU float *x, *y; cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); ... // Free memory cudaFree(x); cudaFree(y);
마지막으로 GPU에서 이를 호출하는 add() 커널을 실행해야 합니다. CUDA 커널 실행은 삼중 꺾쇠 괄호 구문 <<< >>>를 사용하여 지정합니다. 매개변수 목록 앞에 추가할 호출에 add를 실행하기만 하면 됩니다.
add<<<1, 1>>>(N, x, y);간단합니다! 괄호 안에 무엇이 들어가는지는 곧 자세히 설명해드리겠지만, 지금은 이 줄이 add()를 실행하기 위해 하나의 GPU 스레드를 시작한다는 것만 알면 됩니다.
한 가지 더: CPU가 커널이 완료될 때까지 기다렸다가 결과에 액세스해야 합니다(CUDA 커널 실행은 호출하는 CPU 스레드를 차단하지 않으므로). 이를 위해 CPU에서 최종 오류 검사를 수행하기 전에 cudaDeviceSynchronize()를 호출하면 됩니다.
전체 코드는 다음과 같습니다:
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}CUDA 파일의 파일 확장자는 .cu입니다. 따라서 이 코드를 add.cu라는 파일에 저장하고 CUDA C++ 컴파일러인 nvcc로 컴파일합니다.
> nvcc add.cu -o add_cuda
> ./add_cuda
Max error: 0.000000이 커널을 실행하는 모든 스레드가 전체 배열에 대한 추가를 수행하기 때문에 이 커널은 단일 스레드에서만 정확하기 때문에 이것은 첫 번째 단계일 뿐입니다. 또한 여러 개의 병렬 스레드가 같은 위치를 읽고 쓰기 때문에 경쟁 조건이 존재합니다.
참고: Windows의 경우 Microsoft Visual Studio에서 프로젝트의 구성 속성에서 플랫폼을 x64로 설정했는지 확인해야 합니다.
프로파일링하기!
커널을 실행하는 데 걸리는 시간을 확인하는 가장 간단한 방법은 CUDA 툴킷과 함께 제공되는 명령줄 GPU 프로파일러인 nvprof로 커널을 실행하는 것입니다. 명령줄에 nvprof ./add_cuda를 입력하기만 하면 됩니다:
$ nvprof ./add_cuda
==3355== NVPROF is profiling process 3355, command: ./add_cuda
Max error: 0
==3355== Profiling application: ./add_cuda
==3355== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 463.25ms 1 463.25ms 463.25ms 463.25ms add(int, float*, float*)
...위는 nvprof의 잘린 출력으로, add할 단일 호출을 보여줍니다. NVIDIA Tesla K80 가속기에서는 약 0.5초가 걸리고, 3년된 제 Macbook Pro의 NVIDIA GeForce GT 740M에서는 거의 같은 시간이 걸립니다.
병렬 처리로 더 빠르게 만들어 봅시다.
스레드 선택하기
이제 연산을 수행하는 하나의 스레드로 커널을 실행했으니 어떻게 병렬로 만들 수 있을까요? 핵심은 CUDA의 <<<1, 1>>> 구문에 있습니다. 이를 실행 구성이라고 하며, CUDA 런타임에 GPU에서 실행할 때 사용할 병렬 스레드 수를 알려줍니다. 여기에는 두 가지 매개변수가 있는데, 먼저 두 번째 매개변수인 스레드 블록의 스레드 수를 변경하는 것부터 시작해 보겠습니다. CUDA GPU는 32의 배수 크기인 스레드 블록을 사용하여 커널을 실행하므로 256개의 스레드를 선택하는 것이 적당합니다.
add<<<1, 256>>>(N, x, y);이 변경 사항만 적용한 코드를 실행하면 병렬 스레드에 걸쳐 계산을 분산하는 대신 스레드당 한 번만 계산을 수행합니다. 이를 제대로 수행하려면 커널을 수정해야 합니다. CUDA C++는 커널이 실행 중인 스레드의 인덱스를 가져올 수 있는 키워드를 제공합니다. 구체적으로 threadIdx.x는 해당 블록 내 현재 스레드의 인덱스를 포함하고, blockDim.x는 블록 내 스레드 수를 포함합니다. 병렬 스레드로 배열을 순회하도록 루프를 수정하겠습니다.
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}add 기능은 크게 변경되지 않았습니다. 실제로 index 를 0으로 설정하고 스트라이드(stride)는 1로 설정하면 첫 번째 버전과 의미적으로 동일합니다.
파일을 add_block.cu로 저장하고 nvprof에서 다시 컴파일하고 실행합니다. 이 글의 나머지 부분에서는 출력의 관련 줄만 보여드리겠습니다.
Time(%) Time Calls Avg Min Max Name
100.00% 2.7107ms 1 2.7107ms 2.7107ms 2.7107ms add(int, float*, float*)이는 큰 속도 향상(463ms에서 2.7ms로 단축)이지만, 1 스레드에서 256 스레드로 전환했기 때문에 놀라운 것은 아닙니다. K80은 제 작은 맥북 프로 GPU(3.2ms)보다 더 빠릅니다. 더 나은 성능을 위해 계속 테스트해 보겠습니다.
블록 밖으로
CUDA GPU에는 스트리밍 멀티프로세서 또는 SM으로 그룹화된 많은 병렬 프로세서가 있습니다. 각 SM은 여러 개의 동시 스레드 블록을 실행할 수 있습니다. 예를 들어, 파스칼 GPU 아키텍처 기반의 Tesla P100 GPU에는 56개의 SM이 있으며, 각 SM은 최대 2048개의 활성 스레드를 지원할 수 있습니다. 이 모든 스레드를 최대한 활용하려면 여러 스레드 블록으로 커널을 실행해야 합니다.
이제 실행 구성의 첫 번째 매개변수가 스레드 블록의 수를 지정한다는 것을 짐작하셨을 것입니다. 병렬 스레드 블록은 함께 그리드라고 알려진 것을 구성합니다. 처리해야 할 요소가 N개이고 블록당 스레드가 256개이므로 최소 N개의 스레드를 얻기 위해 블록 수를 계산하면 됩니다. N을 블록 크기로 나누기만 하면 됩니다(N이 blockSize의 배수가 아닌 경우 반올림에 주의하세요).
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);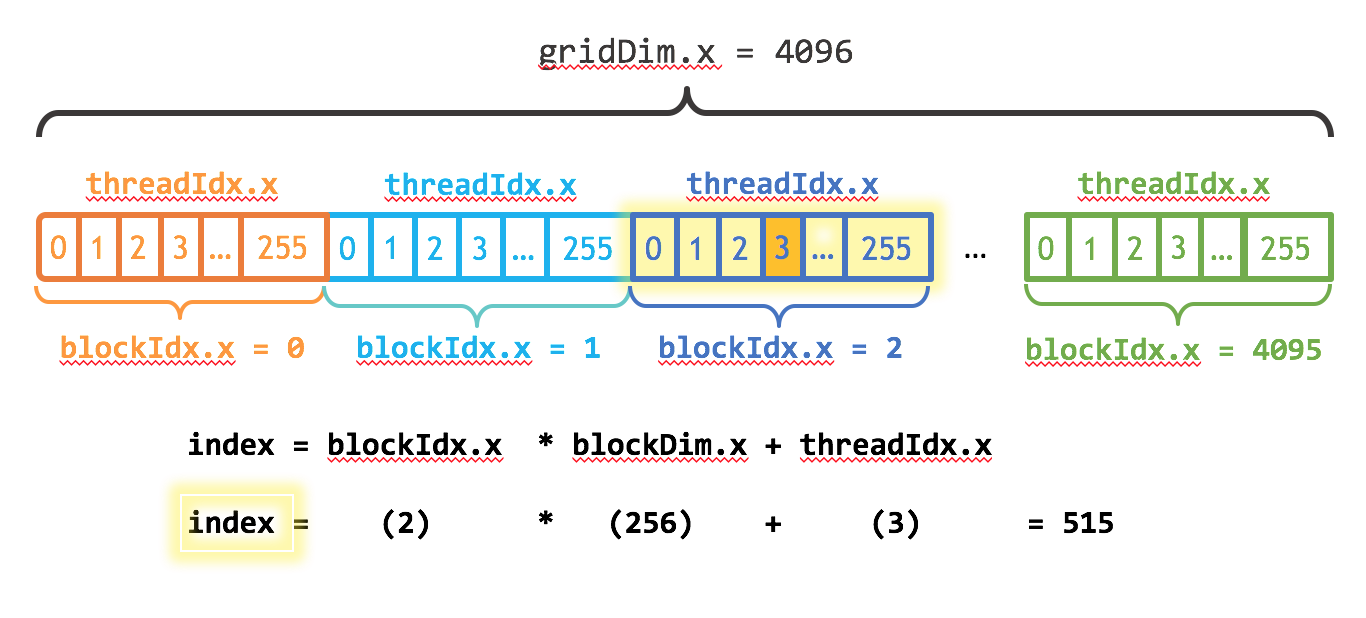
또한 스레드 블록의 전체 그리드를 고려하도록 커널 코드를 업데이트해야 합니다. CUDA는 그리드 내 블록 수를 포함하는 gridDim.x와 그리드 내 현재 스레드 블록의 인덱스를 포함하는 blockIdx.x를 제공합니다. 그림 1은 blockDim.x, gridDim.x 및 threadIdx.x를 사용하여 CUDA에서 배열(1차원)로 인덱싱하는 방법을 보여줍니다. 각 스레드는 블록의 시작 부분에 대한 오프셋(블록 인덱스에 블록 크기: blockIdx.x * blockDim.x)을 계산하고 블록 내에서 스레드의 인덱스를 더하여(threadIdx.x) 자신의 색인을 얻는다는 개념이 있습니다. blockIdx.x * blockDim.x + threadIdx.x 코드는 CUDA 관용구입니다.
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}업데이트된 커널은 또한 stride을 그리드의 총 스레드 수(blockDim.x * gridDim.x)로 설정합니다. CUDA 커널에서 이러한 유형의 루프를 grid-stride loop라고 부르기도 합니다.
파일을 add_grid.cu로 저장하고 nvprof에서 다시 컴파일하고 실행합니다.
Time(%) Time Calls Avg Min Max Name
100.00% 94.015us 1 94.015us 94.015us 94.015us add(int, float*, float*)K80의 모든 SM에서 여러 블록을 실행하면 속도가 28배 빨라집니다! 저희는 K80에서 2개의 GPU 중 하나만 사용하고 있지만, 각 GPU에는 13개의 SM이 있습니다. 제 노트북의 GeForce에는 2개의 (더 약한) SM이 있으며 커널을 실행하는 데 680us가 소요된다는 점에 유의하세요.
요약
다음은 Tesla K80 및 GeForce GT 750M에서 세 가지 버전의 add() 커널의 성능을 요약한 것입니다.
| 노트북 (GeForce GT 750M) | 서버 (Tesla K80) | |||
| 버전 | 시간 | 대역폭 | 시간 | 대역폭 |
| 1 CUDA 스레드 | 411ms | 30.6 MB/s | 463ms | 27.2 MB/s |
| 1 CUDA 블록 | 3.2ms | 3.9 GB/s | 463ms | 4.7 GB/s |
| 다수의 CUDA 블록 | 3.2ms | 18.5 GB/s | 0.094ms | 134 GB/s |
보시다시피, GPU에서 매우 높은 대역폭을 달성할 수 있습니다. 이 글의 계산은 대역폭을 많이 사용하지만 GPU는 고밀도 행렬 선형 대수, 딥 러닝, 이미지 및 신호 처리, 물리 시뮬레이션 등과 같이 연산량이 많은 계산에도 탁월합니다.
연습 예제
계속 학습할 수 있도록 직접 해볼 수 있는 몇 가지 연습 예제를 소개합니다. 아래 댓글 섹션에 여러분의 경험을 올려주세요.
- CUDA 툴킷 설명서를 살펴보세요. 아직 CUDA를 설치하지 않았다면 빠른 시작 가이드와 설치 가이드를 확인하세요. 그런 다음 프로그래밍 가이드와 모범 사례 가이드를 살펴보세요. 다양한 아키텍처에 대한 튜닝 가이드도 있습니다.
- 커널 내에서
printf()로 실험해 보세요. 일부 또는 모든 스레드에 대해threadIdx.x와blockIdx.x의 값을 출력해 보세요. 순차적인 순서로 출력되나요? 왜 또는 왜 안 되나요? - 커널에서
threadIdx.y또는threadIdx.z(또는blockIdx.y)의 값을 출력해 보세요. (blockDim및gridDim도 마찬가지입니다). 왜 이런 것들이 존재할까요? 0이 아닌 다른 값을 사용하려면 어떻게 해야 할까요(dim의 경우 1)? - 파스칼 기반 GPU에 액세스할 수 있는 경우
add_grid.cu를 실행해 보세요. K80 결과보다 성능이 더 좋나요, 나쁘나요? 그 이유는 무엇인가요? (힌트: 파스칼의 페이지 마이그레이션 엔진과 CUDA 8 통합 메모리 API에 대해 읽어보세요.) 이 질문에 대한 자세한 답변은 CUDA 초보자를 위한 통합 메모리 게시물을 참조하세요.
다음 단계
이 포스팅이 CUDA에 대한 흥미를 불러일으키고, 더 많은 것을 배우고 자신의 계산에 CUDA C++를 적용하는 데 관심이 있으시길 바랍니다. 질문이나 의견이 있으시면 아래 댓글 섹션을 통해 주저하지 마시고 문의해 주세요.
이 포스팅의 후속으로 CUDA 프로그래밍 관련 자료를 추가할 계획이지만, 당분간은 이전 입문 포스팅 시리즈를 참고하시면 됩니다(향후 필요에 따라 업데이트/교체할 계획입니다):
- CUDA C++에서 성능 메트릭을 구현하는 방법
- CUDA C++에서 디바이스 속성을 쿼리하고 오류를 처리하는 방법
- CUDA C++에서 데이터 전송을 최적화하는 방법
- CUDA C++에서 데이터 전송을 중첩하는 방법
- CUDA C++에서 글로벌 메모리에 효율적으로 액세스하는 방법
- CUDA C++에서 공유 메모리 사용하기
- CUDA C++의 효율적인 행렬 조옮기기
- CUDA C++의 유한 차분법, 1부
- CUDA C++의 유한 차분 방법, 2부
- CUDA로 주말에 배우는 가속화된 레이 트레이싱
또한, 위의 내용을 반영한 CUDA Fortran 포스팅 시리즈인 CUDA Fortran의 쉬운 입문부터 시작하세요.
Udacity와 NVIDIA에서 제공하는 CUDA 프로그래밍에 관한 온라인 강좌에 등록하는 것도 좋습니다.
NVIDIA 개발자 블로그에는 CUDA C++ 및 기타 GPU 컴퓨팅 주제에 대한 다양한 콘텐츠가 있으니 둘러보시기 바랍니다!
이 강의가 재미있었고 더 많은 것을 배우고 싶으시다면 NVIDIA DLI에서 여러 가지 심층적인 CUDA 프로그래밍 강좌를 제공합니다.
- 이제 막 시작하는 분들을 위해 전용 GPU 리소스, 보다 정교한 프로그래밍 환경, NVIDIA Nsight 시스템 비주얼 프로파일러 사용, 수십 개의 대화형 연습, 상세한 프레젠테이션, 8시간 이상의 자료, DLI 자격증 취득 기회를 제공하는 CUDA C/C++를 사용한 가속 컴퓨팅의 기초를 살펴보세요.
- 파이썬 프로그래머의 경우 CUDA 파이썬을 사용한 가속 컴퓨팅의 기초를 참조하세요.
- 더 많은 중급 및 고급 CUDA 프로그래밍 자료는 NVIDIA DLI 자기 주도형 카탈로그의 가속 컴퓨팅 섹션을 참조하세요.
관련 리소스
- DLI 과정: 더 쉬운 CUDA 입문
- DLI 과정: CUDA C/C++를 사용한 가속 컴퓨팅의 기초
- GTC 세션: CUDA 프로그램 작성 방법: 닌자 에디션
- GTC 세션: CUDA C++ 마스터하기: CUDA C++ 코어 라이브러리를 사용한 최신 모범 사례
- GTC 세션: CUDA 프로그래밍 및 성능 최적화 소개
- NGC 컨테이너: CUDA