
Simulation is an essential tool for robots learning new skills. These skills include perception (understanding the world from camera images), planning (formulating a sequence of actions to solve a problem), and control (generating motor commands to change a robot’s position and orientation).
Robotic assembly is ubiquitous in the automotive, aerospace, electronics, and medical device industries. Setting up robots to perform an assembly task is a time-consuming and expensive process, requiring a team to engineer the robot’s trajectories and constrain its surroundings carefully.
In other areas of robotics, simulation has become an indispensable tool, especially for the development of AI. However, robotic assembly involves high-precision contact between geometrically complex, tight-tolerance parts. Simulating these contact-rich interactions has long been viewed as computationally intractable.
With recent developments from NVIDIA advancing robotic assembly, faster-than-realtime simulation is possible. These high-speed simulations enable the use of powerful, state-of-the-art techniques in reinforcement learning (RL). With RL, virtual robots explore simulated environments, gain years of experience, and learn useful skills through intelligent trial-and-error. Using RL for robotic assembly minimizes the need for human expertise, increases robustness to variation, and reduces hardware wear and tear. The term sim-to-real refers to the transfer of skills from simulation to the real world.
One of the biggest challenges in using RL for robotic assembly is that skills learned by robots in simulation do not typically transfer well to real-world robots. Subtle discrepancies in physics, motor signals, and sensor signals between the simulator and the real world cause this issue. Moreover, a real-world robot might encounter scenarios never seen in the simulator. These issues are collectively known as the reality gap.
What is IndustReal?
To use RL for challenging assembly tasks and address the reality gap, we developed IndustReal. IndustReal is a set of algorithms, systems, and tools for robots to solve assembly tasks in simulation and transfer these capabilities to the real world.
IndustReal’s primary contributions include the following:
- A set of algorithms for simulated robots to solve complex assembly tasks with RL.
- A method that addresses the reality gap and stabilizes the learned skills when deployed in the real world.
- A real-world robotic system that performs sim-to-real transfer of simulation-trained assembly skills from end-to-end.
- A hardware and software toolkit for researchers and engineers to reproduce the system.
- IndustRealKit is a set of 3D-printable CAD models of assets inspired by NIST Task Board 1, the established benchmark for robotic assembly.
- IndustRealLib is a lightweight Python library that deploys skills learned in the NVIDIA Isaac Gym simulator onto a real-world Franka Emika Panda robot arm.

Training algorithms and deployment method
In this work, we propose three algorithms to help learn assembly skills using RL in simulation. We also propose a deployment method for executing the skills on a real-world robot.
Simulation-aware policy update
Robotics simulators like NVIDIA Isaac Gym and NVIDIA Isaac Sim simulate real-world physics while simultaneously satisfying many physical constraints–most importantly, that objects cannot overlap with one another, or, interpenetrate. In most simulators, small interpenetrations between objects are unavoidable, especially when executing in real time.
We introduce the simulation-aware policy update (SAPU) that provides the simulated robot with knowledge of when simulation predictions are reliable or unreliable. Specifically, in SAPU, we implement a GPU-based module in NVIDIA Warp that checks for interpenetrations as the robot is learning how to assemble parts using RL.
We weight the robot’s simulated experience more when interpenetrations are small, and less when interpenetrations are large. This strategy prevents a simulated robot from exploiting inaccurate physics to solve tasks, which would cause it to learn skills that are unlikely to transfer to the real world.
Signed distance field reward
To solve tasks with RL, a reward signal (such as measuring how much progress the robot has made on solving the task) must be defined. However, it is challenging to define a reward signal for the alignment of geometrically complex parts during an assembly process.
We introduce a signed distance field (SDF) reward to measure how closely simulated parts are aligned during the assembly process. An SDF is a mathematical function that can take points on one object and compute the shortest distances to the surface of another object. It provides a natural and general way to describe alignment between parts, even when they are highly symmetric or asymmetric.
In the SDF reward, we define our reward signal as the SDF distance between the current position and the target position of a part during the assembly process.
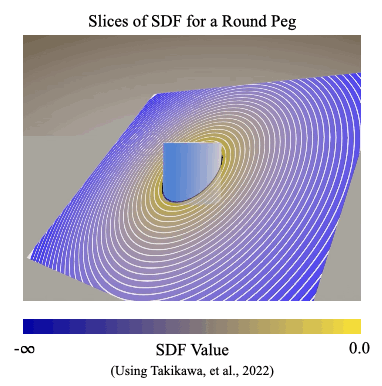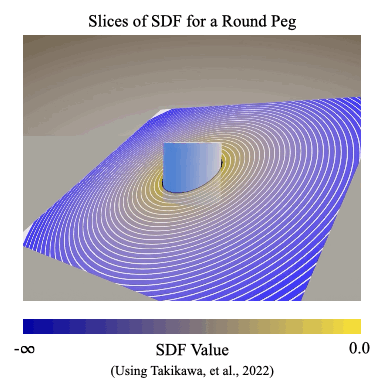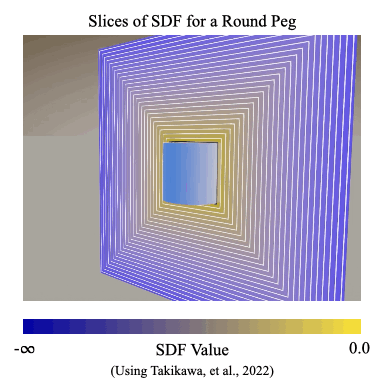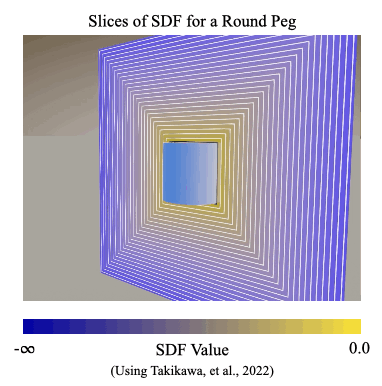
In Figure 2, the color represents the shortest distance from the given point to the surface of the peg.
Sampling-based curriculum
Curriculum learning is an established approach in RL for solving problems that involve many individual steps or motions; as the robot learns, the difficulty of the task is gradually increased.
In our assembly tasks, the robot begins by solving simple assembly problems (that is, where the parts are partially assembled), before progressing to harder problems (that is, where the parts are disassembled).
As the initial engagement between parts is gradually reduced, there comes a point where the parts no longer begin in contact. This sudden increase in difficulty can lead to a performance collapse as the robot’s knowledge has become too specialized towards the partially assembled configurations.
We introduce a sampling-based curriculum (SBC) for a simulated robot to learn a complex assembly task gradually. We ask the robot to solve assembly problems sampled across the entire difficulty range during all stages of the curriculum. However, we gradually remove the easiest problems from the problem distribution. At the final stage of the curriculum, the parts never begin in contact. See the following visualization.

Policy-level action integrator
In the most common applications of RL to robotics, the robot generates actions that are incremental adjustments to its pose (that is, its position and orientation). These increments are applied to the robot’s current pose to produce an instantaneous target pose. With real-world robots, this strategy can lead to discrepancies between the robot’s final pose and its final target pose due to the complexities of the physical robot.
We also propose a policy-level action integrator (PLAI), a simple algorithm that reduces steady-state (that is, long-term) errors when deploying a learned skill on a real-world robot. We apply the incremental adjustments to the previous instantaneous target pose to produce the new instantaneous target pose.
Mathematically (akin to the integral term of a classical PID controller), this strategy generates an instantaneous target pose that is the sum of the initial pose and the actions generated by the robot over time. This technique can minimize errors between the robot’s final pose and its final target pose, even in the presence of physical complexities.
We compare the performance of a standard (nominal) strategy, our PLAI algorithm, and a classical PID controller on a reach task, where the robot is trying to move to a target position. See the following visualization.
Systems and tools
The setup used for the real-world experiments conducted in IndustReal includes a Franka Emika Panda robot arm with an Intel RealSense D435 camera mounted on its hand and an assembly platform with parts.

IndustReal provides hardware (IndustRealKit) and software (IndustRealLib) for reproducing the system presented in the paper.
IndustRealKit contains 3D-printable 20-part CAD models for all parts used in this work. The models come with six peg holders, six peg sockets, three gears, one gear base (with three gear shafts), and four NEMA connectors and receptacle holders, which are standard plugs and power outlets used in the United States.
The purchasing list includes 17 parts: six metal pegs (from the NIST benchmark), four NEMA connectors and receptacles, one optical platform, and fasteners.

IndustRealLib is a lightweight library containing code for deploying skills learned in simulation through RL onto a real-world robot arm. Specifically, we provide scripts for users to deploy control policies (that is, neural networks that map sensor signals to robot actions) trained in the NVIDIA Isaac Gym simulator onto a Franka Emika Panda robot quickly.
Future direction
IndustReal shows a path toward leveraging the full potential of simulation in robotic assembly tasks. As simulation becomes more accurate and efficient, and additional sim-to-real transfer techniques are developed, we foresee numerous possibilities of expanding this work to other tasks in manufacturing (such as screw fastening, cable routing, and welding). It is reasonable to believe that one day every advanced industrial manufacturing robot will be trained in simulation using such techniques, for seamless and scalable transfer to the real world.
Our next steps are to expand the system to include more objects, assembly tasks, and complex environments. We also aim to develop additional sim-to-real techniques for the smooth transfer of learned skills at lower cost, higher reliability, and guaranteed safety.
Get started with IndustReal
- Visit the IndustReal project page, for links to the paper and summary videos. Stay tuned for the upcoming availability of IndustRealKit and IndustRealLib.
- Download the standalone NVIDIA Isaac Gym Preview Release and NVIDIA Isaac Gym Environments. This includes the NVIDIA Omniverse factory environments that were the basis for training the assembly skills in IndustReal.
- Download the next-generation NVIDIA Isaac Sim powered by Omniverse.
Paper authors Bingjie Tang, Michael A. Lin, Iretiayo Akinola, Ankur Handa, Gaurav S. Sukhatme, Fabio Ramos, Dieter Fox, and Yashraj Narang will present their research “IndustReal: Transferring Industrial Assembly Tasks from Simulation to Reality” at the Robotics: Science and Systems (RSS) conference in July 2023.
