
NVIDIA just released a SIGGRAPH Asia 2023 research paper, SLANG.D: Fast, Modular and Differentiable Shader Programming. The paper shows how a single language can serve as a unified platform for real-time, inverse, and differentiable rendering. The work is a collaboration between MIT, UCSD, UW, and NVIDIA researchers.
This is part of a series on Differentiable Slang. For more information about practical examples of Slang with various machine learning (ML) rendering applications, see Differentiable Slang: Example Applications.
Slang is an open-source language for real-time graphics programming that brings new capabilities for writing and maintaining large-scale, high-performance, cross-platform graphics codebases. Slang adapts modern language constructs to the high-performance demands of real-time graphics, and generates code for Direct 3D 12, Vulkan, OptiX, CUDA, and the CPU.
While Slang began as a research project, it has grown into a practical solution used in the NVIDIA Omniverse and NVIDIA RTX Remix renderers, and the NVIDIA Game Works Falcor research infrastructure.
The new research pioneers a co-design approach. This approach shows that the complexities of automatic differentiation can be handled elegantly if differentiation is incorporated as a first-class citizen in the entire system:
- Language
- Type system
- Intermediate representation (IR)
- Optimization passes
- Auto-completion engine
Slang’s automatic differentiation integrates seamlessly with Slang’s modular programming model, GPU graphics pipelines, Python, and PyTorch. Slang supports differentiating arbitrary control flow, user-defined types, dynamic dispatch, generics, and global memory accesses. With Slang, existing real-time renderers can be made differentiable and learnable without major source code changes.
Bridging computer graphics and machine learning
Data-driven rendering algorithms are changing computer graphics, enabling powerful new representations for shape, textures, volumetrics, materials, and post-processing algorithms that increase performance and image quality. In parallel, computer vision and ML researchers are increasingly leveraging computer graphics, for example, to improve 3D reconstruction through inverse rendering.
Bridging real-time graphics, ML, and computer vision development environments is challenging because of different tools, libraries, programming languages, and programming models. With the latest research, Slang enables you to easily take on the following tasks:
- Bring learning to rendering. Slang enables graphics developers to use gradient-based optimization and solve traditional graphics problems in a data-driven manner, for example, learning mipmap hierarchies using appearance-based optimization.
- Build differentiable renderers from existing graphics code. With Slang, we transformed a preexisting, real-time path tracer into a differentiable path tracer, reusing 90% of the Slang code.
- Bring graphics to ML training frameworks. Slang generates custom PyTorch plugins from graphics shader code. In this post, we demonstrate using Slang in Nvdiffrec to generate auto-differentiated CUDA kernels.
- Bring ML training inside the renderer. Slang facilitates training small neural networks inside a real-time renderer, such as the model used in neural radiance caching.
Differentiable programming and machine learning need gradients



Figure 1 shows the Stanford Bunny placed inside the Cornell box scene. The left column shows the rendered scene. The middle column shows a reference derivative with respect to the bunny’s translation in the y-axis. The right column shows the same derivative computed by the Slang’s autodiff feature, which appears identical to the reference image.
A key pillar of ML methods is gradient-based optimization. Specifically, most ML algorithms are powered by reverse-mode automatic differentiation, an efficient way to propagate derivatives through a series of computations. This applies not only to large neural networks but also to many simpler data-driven algorithms that require the use of gradients and gradient descent.
Frameworks like PyTorch expose high-level operations on tensors (multi-dimensional matrices) that come with hand-coded reverse-mode kernels. As you compose tensor operations to create your neural network, PyTorch composes derivative computations automatically by chaining those kernels. The result is an easy-to-use system where you do not have to write gradient flow manually, which is one of the reasons behind ML research’s accelerated pace.
Unfortunately, some computations aren’t easily captured by those high-level operations on arrays, creating difficulties in expressing them efficiently. This is the case with graphics components such as a rasterizer or ray tracer, where diverging control flow and complex access patterns require a lot of inefficient active-mask tracking and other workarounds. Those workarounds are not only difficult to write and read but also have a significant performance and memory usage overhead.
As a result, most high-performance differentiable graphics pipelines, such as nvdiffrec, InstantNGP, and Gaussian splatting, are not written in pure Python. Instead, researchers write high-performance kernels in languages operating closer to the underlying hardware, such as CUDA, HLSL, or GLSL.
Because these languages do not provide automatic differentiation, these applications use hand-derived gradients. Hand-differentiation is tedious and error-prone, making it difficult for others to use or modify those algorithms. This is where Slang comes in, as it can automatically generate differentiated shader code for multiple backends.
Designing Slang’s automatic differentiation
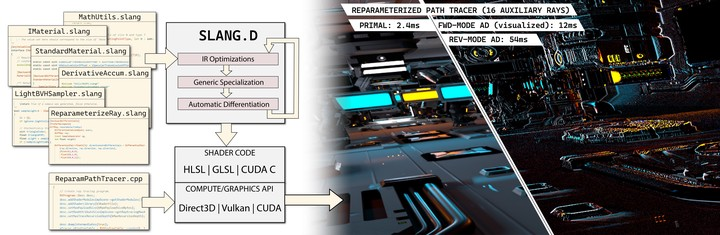
Figure 2 shows propagated derivatives on the Zero Day scene computed by a differentiable path tracer written in the Falcor framework. The differentiable path tracer was built by reusing over 5K lines of preexisting shader code.
Slang’s roots can be traced to the Spark programming language presented at SIGGRAPH 2011 and, in its current form, to SIGGRAPH 2018. Adding automatic differentiation to Slang required years of research and many iterations of language design. Every part of the language and the compiler—including the parser, type system, standard library, IR, optimization passes, and the Intellisense engine—needed to be revised to support auto-diff as a first-class member of the language.
Slang’s type system has been extended to treat differentiability as a first-class property of functions and types. The type system enables compile-time checks to guard against common mistakes when working in differentiable programming frameworks, such as dropping derivatives unintentionally through calls to non-differentiable functions. We describe those and many more challenges and solutions in our technical paper, SLANG.D: Fast, Modular and Differentiable Shader Programming.
In Slang, automatic differentiation is represented as a composable operator on functions. Applying automatic differentiation on a function yields another function that can be used just as any other function. This functional design enables higher-order differentiation, which is absent in many other frameworks. The ability to differentiate a function multiple times in any combination of forward and reverse modes significantly eases the implementation of advanced rendering algorithms, such as warped-area sampling and Hessian-Hamiltonian MLT.
Slang’s standard library has also been extended to support differentiable computations, and most existing HLSL intrinsic functions are treated as differentiable functions, allowing existing code that uses these intrinsics to be automatically differentiated without modifications.
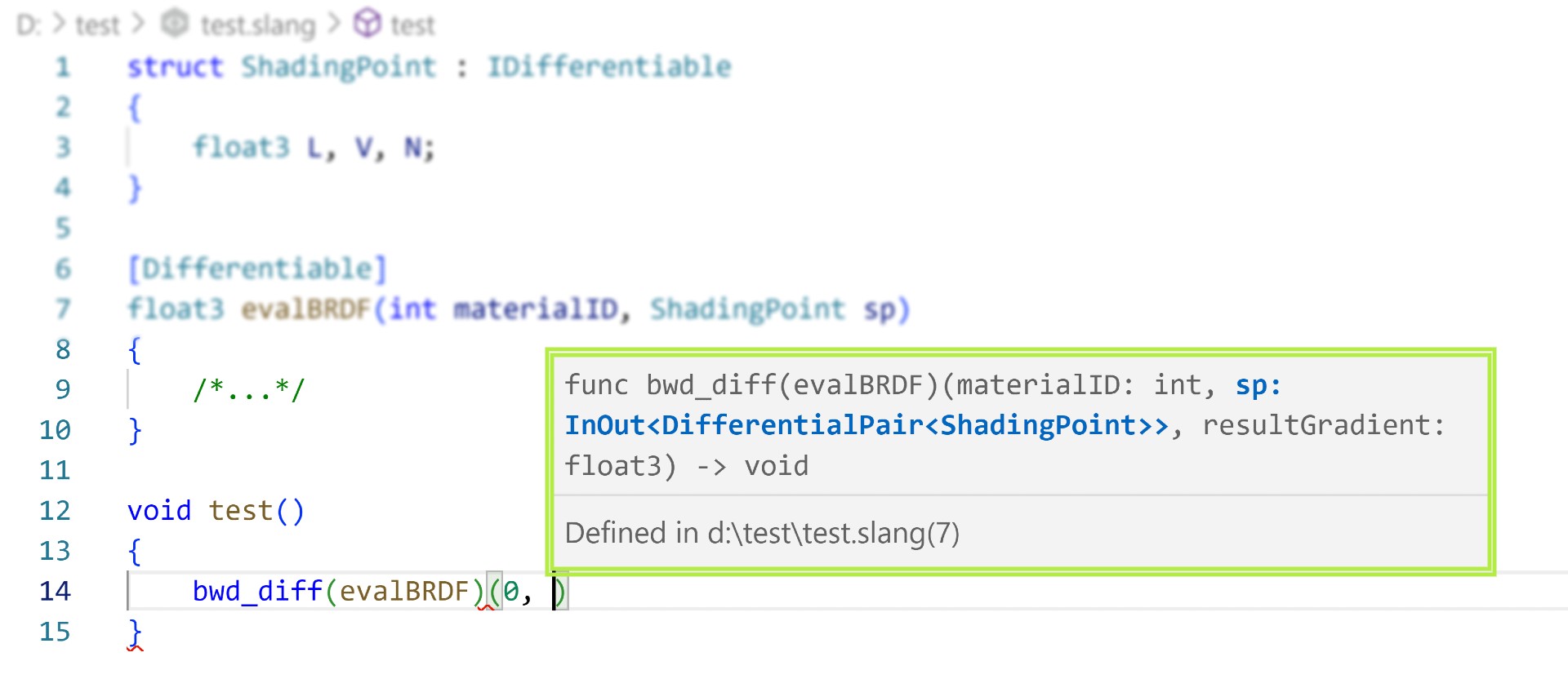
Slang offers a complete developer toolset, including a Visual Studio Code extension with comprehensive hinting and auto-completion support for differentiable entities, which improves productivity in our internal projects.
Real-time graphics in the differentiable programming ecosystem
The Slang compiler can emit derivative function code in the following languages:
- HLSL: For use with Direct3D pipelines.
- GLSL or SPIR-V: For use with OpenGL and Vulkan.
- CUDA or OptiX: For use in standalone applications, in Python, or with tensor frameworks such as PyTorch.
- Scalar C++: For debugging.
You can emit the same code to multiple targets. For instance, you could train efficient models with PyTorch optimizers and then deploy them in a video game or other interactive experience running on Vulkan or Direct3D without writing new or different code. A single representation written in one language is highly beneficial for long-term code maintenance and avoiding bugs arising if two versions are subtly different.
Similarly to the NVIDIA WARP framework for differentiable simulation, Slang contributes to the growing ecosystem of differentiable programming. Slang allows the generation of derivatives automatically and the use of them together with both lower and higher-level programming environments. It is possible to use Slang together with handwritten, heavily optimized CUDA kernels and libraries.
If you prefer a higher-level approach and use Python interactive notebooks for research and experimentation, you can use Slang through the slangpy package (pip install slangpy) from environments like Jupyter notebooks. Slang can be a part of a rich notebook, Python, PyTorch, and NumPy ecosystem to interface with data stored in various formats, interact with it using widgets, and visualize with plotting and data analysis libraries while offering an additional programming model, more suited for certain applications.
Tensors vs. shading languages
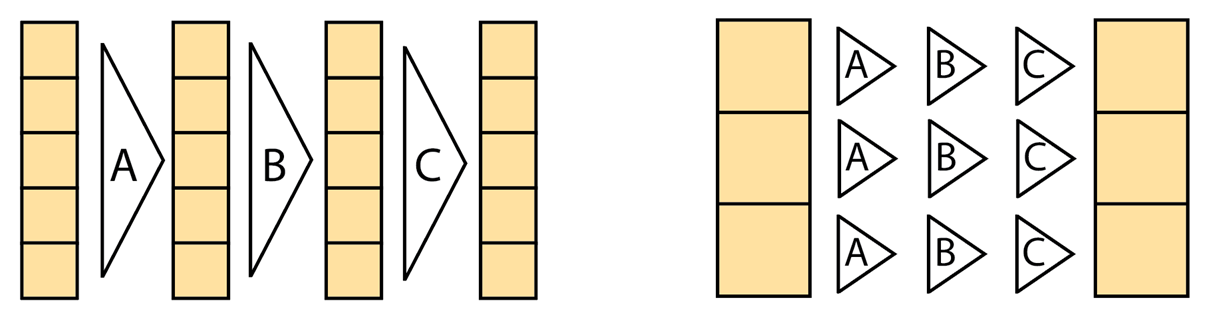
PyTorch and other tensor-based libraries, such as NumPy, TensorFlow, and Jax, offer fundamentally different programming models from Slang and, in general, shading languages. PyTorch is designed primarily for feed-forward neural networks where operations on each element are relatively uniform without diverging control flow. The NumPy and PyTorch n-dimensional array (ndarray) model operates on whole tensors, making it trivial to specify horizontal reductions like summing over axes and large matrix multiplications.
By contrast, shading languages occupy the other end of the spectrum and expose the single-instruction-multiple-threads (SIMT) model to enable you to specify programs operating on a single element or a small block of elements. This makes it easy to express intricate control flow where each set of elements executes a vastly different series of operations, such as when the rays of a path tracer strike different surfaces and execute different logic for their next bounce.
Both models co-exist and should be treated as complementary, as they fulfill different goals: A reduce-sum operation on a tensor would take one line of ndarray code, but hundreds of lines of code and multiple kernel launches to express efficiently in the SIMT style.
Conversely, a variable-step ray marcher can be written elegantly in the SIMT style using dynamic loops and stopping conditions, but the same ray marcher would devolve into complex and unmaintainable active-mask-tracking ndarray code. Such code is not only difficult to write and read but can perform worse as every branch gets executed for each element instead of only one or the other, depending on the active state.
Performance benefits
PyTorch and other ML frameworks are built for the training and inference of large neural networks. They use heavily optimized platform libraries to perform large matrix-multiply and convolution operations.
While each individual operation is extremely efficient, the intermediate data between them is serialized to the main memory and checkpointed. During training, the forward and backpropagation passes are computed serially and separately. This makes the overhead of PyTorch significant for tiny neural networks and other differentiable programming uses in real-time graphics.
Slang’s automatic differentiation feature gives you control over how gradient values are stored, accumulated, and computed, which enables significant performance and memory optimizations. By avoiding multiple kernel launches, excessive global memory accesses, and unnecessary synchronizations, it enables fusing forward and backward passes and up to 10x training speedups compared to the same small-network and graphics workloads written with standard PyTorch operations.
This speedup not only accelerates the training of ML models but also enables many novel applications that use smaller inline neural networks inside graphics workloads. Inline neural networks open up a whole new area of computer graphics research, such as neural radiance caching, neural texture compression, and neural appearance models.
Show me the code!
For more information about Slang’s open-source repository and the slangpy Python package, see the /shader-slang GitHub repo and Using Slang to Write PyTorch Kernels. The automatic differentiation language feature is documented in the Slang User Guide. We also include several differentiable Slang tutorials that walk through the code for common graphics components in Slang while introducing Slang’s object-oriented differentiable programming model.
For more Slang and PyTorch tutorials using slangpy, see the following resources:
- 1-Triangle Rasterizer (Non-Differentiable)
- 1-Triangle Differentiable ‘Soft’ Rasterizer
- 1-Triangle Differentiable Rasterizer using Monte Carlo Edge Sampling
- Image Fitting using Tiny Inline MLPs (using CUDA’s WMMA API)
For more examples, see Differentiable Slang: Example Applications.
Conclusion
Differentiable rendering is a powerful tool for computer graphics, computer vision, and image synthesis. While researchers have advanced its capabilities, built systems, and explored applications for years, the resulting systems were difficult to combine with existing large codebases. Now, with Slang, existing real-time renderers can be made differentiable.
Slang greatly simplifies adding shader code to ML pipelines, and the reverse, adding learned components to rendering pipelines.
Real-time rendering experts can now explore building ML rendering components without rewriting the rendering code in ML frameworks. Slang facilitates data-driven asset optimization and improvement and aids the research of novel neural components in traditional rendering.
On the other end of the spectrum, ML researchers can now leverage existing renderers and assets with complex shaders and incorporate expressive state-of-the-art shading models in new architectures.
We are looking forward to seeing how bridging real-time graphics and machine learning contributes to new photorealistic neural and data-driven techniques. For more information about Slang’s automatic differentiation feature, see the SLANG.D: Fast, Modular and Differentiable Shader Programming paper.
