
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing their own computing infrastructure by tapping into remote, on-demand resources deftly managed by cloud service providers. Yet, there exists a palpable apprehension about sharing sensitive information with the cloud.
While traditional cryptographic methods such as AES can help preserve data privacy, they stifle the cloud’s capacity to undertake meaningful operations on the data. In an encryption system, a message, also referred to as plaintext, is transformed using a key into a scrambled version known as ciphertext. The encryption methods in place assure that malicious entities can’t decrypt the message without the correct key and can’t gain access to its contents. Without decryption, a ciphertext is essentially nonsensical.
Fortunately, there is a solution: fully homomorphic encryption (FHE), a sophisticated and potent encryption technique. It serves as a comprehensive shield for data, whether in transit, at rest, or in use. Homomorphic encryption is a unique design that enables operations to be performed on the ciphertext while still preserving its security. This type of operation modifies a ciphertext in such a way that, after decryption, the result is the same as if the operation was carried out on the plaintext itself.
Frequently referred to as the ultimate goal of cryptography, FHE can carry out any computational function on the ciphertext. This remarkable technology has the capability to run thousands of algorithms directly on encrypted data, all without compromising the underlying plaintext. It confronts the pivotal privacy issues linked with cloud computing head-on, while simultaneously enabling intricate outsourced computations.
However, operations performed with FHE encryption tend to be slower than those conducted over standard unencrypted data. Also, the current applications of this technology can be somewhat challenging for non-specialists to set up and manage effectively.
ArctyrEX: Accelerated encrypted execution
A recent effort by NVIDIA Research aims to address the efficiency problems associated with encrypted computing. The proposed solution, ArctyrEX, is an end-to-end framework that enables you to specify algorithms in C++ using standard data types and automatically convert this algorithm into an FHE representation that can be launched on arbitrary numbers of GPUs for efficient evaluation.
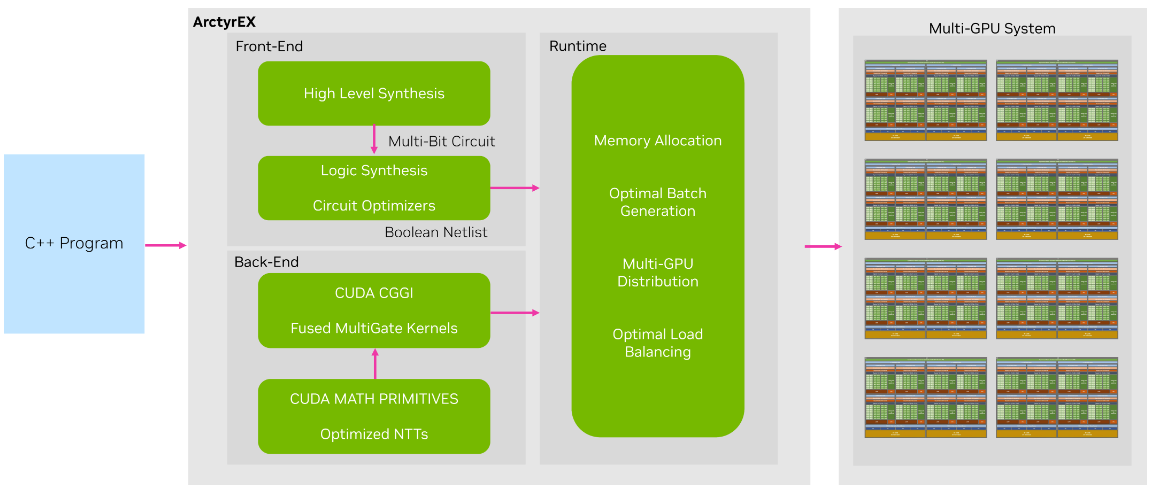
ArctyrEX is composed of three parts:
- A frontend responsible for converting input programs to the encrypted domain
- A runtime library that sends encrypted workloads to GPU workers
- A backend that consists of an implementation of the state-of-the-art CGGI cryptosystem.
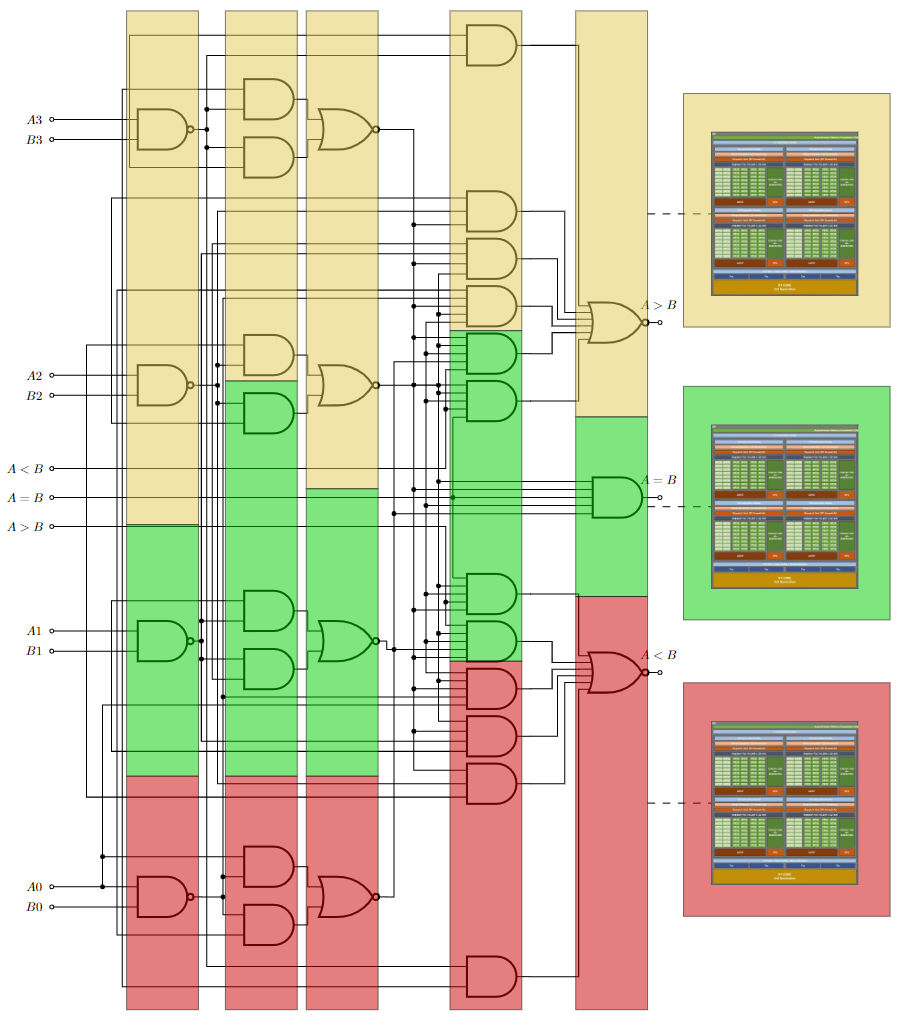
The CGGI cryptosystem encrypts single bits of plaintext and enables encrypted Boolean operations between ciphertexts. Therefore, the programming model for CGGI is akin to constructing Boolean circuits composed of logic gates. For more information, see TFHE: Fast Fully Homomorphic Encryption over the Torus and TFHE.
The frontend takes advantage of decades of hardware development research to convert C++ programs to equivalent Verilog files, which provide a description of a circuit at a high level of abstraction. Then it converts the files to optimal Boolean circuits. This process uses well-established techniques in the form of high-level synthesis (HLS) and register-transfer level (RTL) or logic synthesis.
The ArctyrEX runtime library takes the generated Boolean circuit, divides it into distinct levels, and creates batches of approximately identical size to distribute to GPU workers. In some cases, the ciphertexts corresponding to an output wire of a gate at an intermediate level may have to serve as input to a workload assigned to a different GPU during the next level. ArctyrEX is capable of seamlessly coordinating these transfers efficiently.
Lastly, the ArctyrEX backend consists of an optimized CUDA kernel capable of executing batches of gates concurrently while minimizing CPU-GPU synchronizations. The output is composed of a set of ciphertexts that represent the output wires of the gates in the assigned batch.
Run programs with ArctyrEX up to 40x faster
ArctyrEX shows great scalability with the use of more GPUs for two key reasons:
- Abundant primitive-level parallelism that is a natural trait of most FHE operations.
- Circuit-level parallelism, which is a characteristic commonly displayed in Boolean circuits.
To attain speedy evaluation with Boolean FHE, the circuit must have wide levels, meaning that there should be many gates that can operate simultaneously, and it should have a minimal critical path. To show this, compare an encrypted dot product operation between two vectors with an encrypted vector addition operation.
To actualize these programs in ArctyrEX, you can write C++ code at a high level in an intuitive manner. Here, the pragma is necessary to unroll the loop before the HLS pass. You can employ HLS tools like Google XLS, which are designed to make digital design more approachable and efficient. XLS provides the means to specify digital logic at a higher level like C++ than traditional hardware description languages (like Verilog or VHDL), making the entire process simpler and more efficient.
As an example, observe the differences between an encrypted dot product between two vectors and an encrypted vector addition. To implement these programs in ArctyrEX, you can intuitively write high-level C++ code in the following way, where the pragma is required to unroll the loop before the HLS pass handled by Google XLS:
void vector_addition(int x[500], int y[500], int z[500]) {
#pragma hls_unroll yes
for (int i =0; i < 500; i++)
z[i] = x[i] + y[i];
}
short dot_product(short x[500], short y[500]) {
short product = 0;
#pragma hls_unroll yes
for (int i = 0; i < 500; i++)
Product = product + x[i] * y[i];
return product;
}
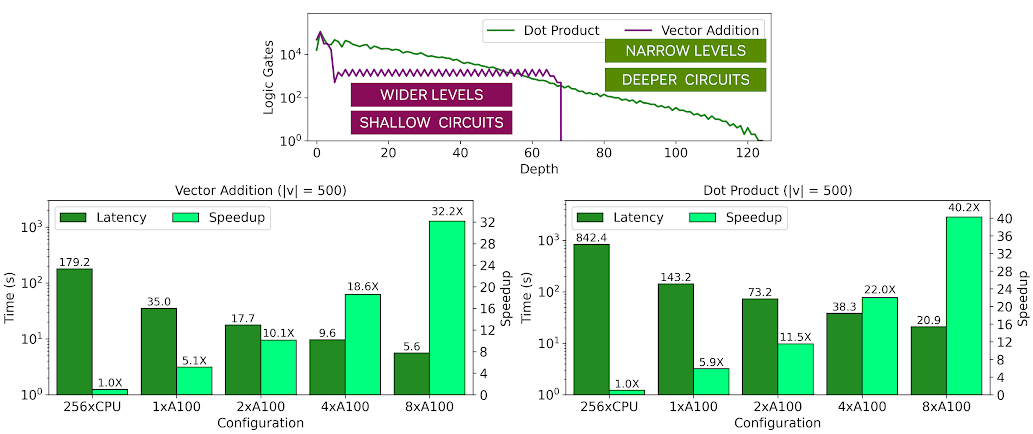
Figure 3 shows the characteristics of both circuits, specifically the number of logic gates at each level of the circuit. In the chart, |v| indicates the vector length and M refers to the dimensions of the matrices. You can see that a dot product of two vectors has a higher critical path with a depth of approximately 120 levels and the width of subsequent levels decreases gradually, limiting the parallelism possible to exploit in the later stages of the circuit.
On the other hand, vector addition has a critical path that is approximately 2x shorter than the dot product, and the width of each level remains relatively constant. As a result, the vector addition runs approximately 4x faster than the dot product, although both exhibit high speedups over a parallel CPU baseline with multiple GPUs. These interesting performance trends are shown in the topology graphs earlier. The light green bars show the speedup relative to a 256-threaded CPU baseline while the dark green bars show the execution time of the homomorphic application.
Summary
In summary, ArctyrEX represents a comprehensive solution for encrypted computation across various applications, harnessing the power of GPU acceleration and implementing innovative techniques for efficient FHE algorithm execution. Tasks like neural network inference demonstrate linear acceleration with the augmentation of GPUs, attributed to the inherent circuit-level parallelism, the newly introduced dispatch paradigm, and the extensive primitive-level parallelism harnessed by the CUDA-accelerated CGGI backend.
For more information, see the Accelerated Encrypted Execution of General-Purpose Applications paper and the live NVIDIA GTC 2023 presentation, ArctyrEX: Accelerated Encrypted Execution of General-Purpose Applications on GPUs.
Acknowledgments
We thank all authors of ArctyrEX for their contributions, especially Charles Gouert (Ph.D. candidate) and Prof. Nektarios Georgios Tsoutsos from the University of Delaware. We’d also like to thank members of Zama, CryptoLab, Google, and Duality Tech for their insightful discussions, particularly Ilaria Chillotti, Jung Hee Cheon, Ahmad Al Badawi, Yuri Polyakov, David Cousins, Shruti Gorantala, and Eric Astor.
