
Efficient pipeline design is crucial for data scientists. When composing complex end-to-end workflows, you may choose from a wide variety of building blocks, each of them specialized for a dedicated task. Unfortunately, repeatedly converting between data formats is an error-prone and performance-degrading endeavor. Let’s change that!
In this post series, we discuss different aspects of efficient framework interoperability:
- In the first post, discusses the pros and cons of distinct memory layouts as well as memory pools for asynchronous memory allocation to enable zero-copy functionality.
- In this post, we highlight bottlenecks occurring during data loading/transfers and how to mitigate them using Remote Direct Memory Access (RDMA) technology.
- In the third post, we dive into the implementation of an end-to-end pipeline demonstrating the discussed techniques for optimal data transfer across data science frameworks.
To learn more on framework interoperability, check out our presentation at the NVIDIA GTC 2021 Conference.
Data loading and data transfer bottlenecks
Data loading bottleneck
Thus far, we have worked on the assumption that the data is already loaded in memory and that a single GPU is used. This section highlights a few bottlenecks that might occur when loading your dataset from storage to device memory or when transferring data between two GPUs using either a single node or multiple nodes setting. We then discuss how to overcome them.
In a traditional workflow (Figure 1), when a dataset is loaded from storage to GPU memory, the data will be copied from the disk to the GPU memory using the CPU and the PCIe bus. Loading the data requires at least two copies of the data. The first one happens when transferring the data from the storage to the host memory (CPU RAM). The second copy of the data occurs when transferring the data from the host memory to the device memory (GPU VRAM).
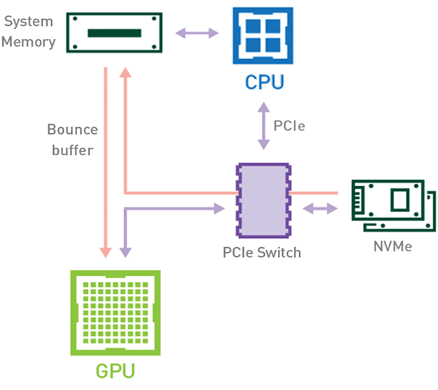
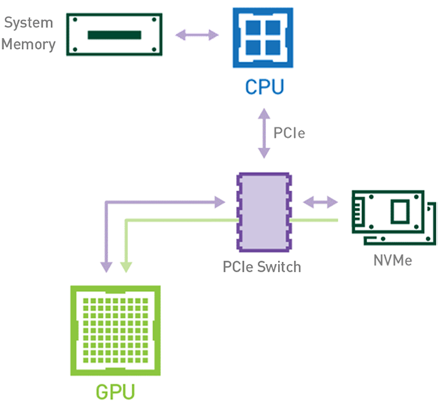
Alternatively, using a GPU-based workflow that leverages NVIDIA Magnum IO GPUDirect Storage technology (see Figure 2), the data can directly flow from the storage to the GPU memory using the PCIe bus, without making use of neither the CPU nor the host memory. Since the data is copied only once, the overall execution time decreases. Not involving the CPU and the host memory for this task also makes those resources available for other CPU-based jobs in your pipeline.
Intra-node data transfer bottleneck
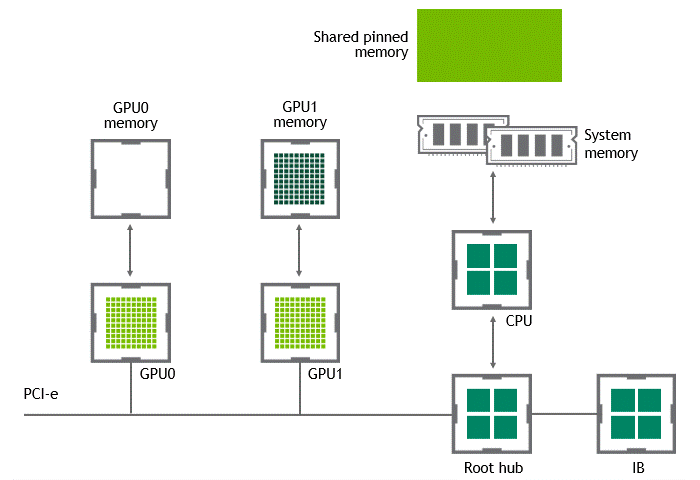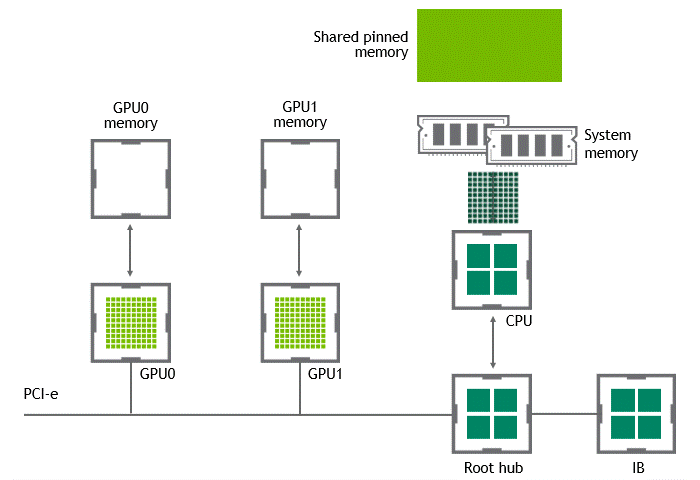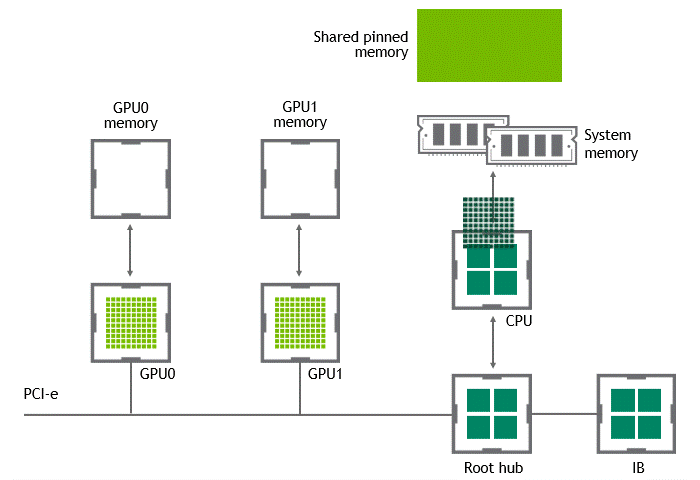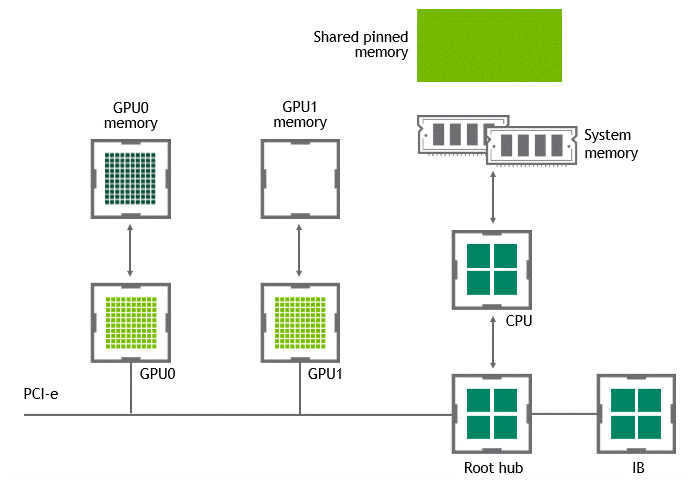
Some workloads require data exchange between two or more GPUs located in the same node (server). In a scenario where NVIDIA GPUDirect Peer to Peer technology is unavailable, the data from the source GPU will be copied first to host-pinned shared memory through the CPU and the PCIe bus. Then, the data will be copied from the host-pinned shared memory to the target GPU through the CPU and the PCIe bus. Note that the data is copied twice before reaching its destination, not to mention the CPU and host memory are involved in this process. Figure 3 depicts the data movement described before.
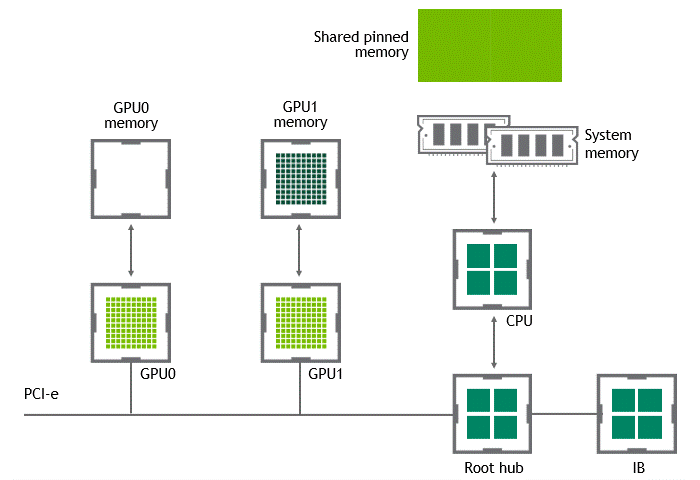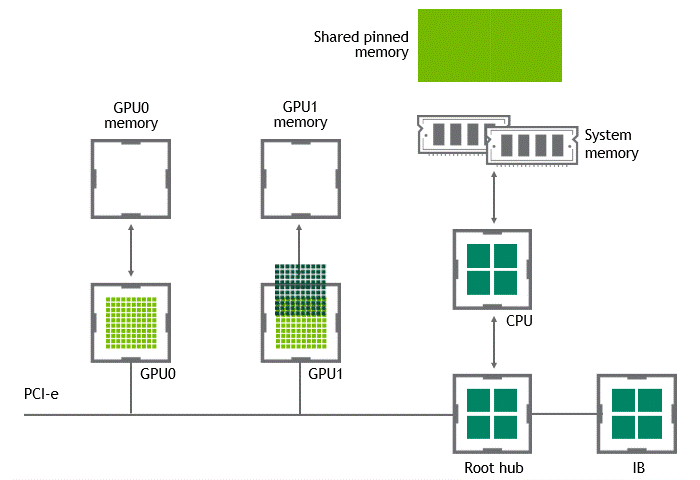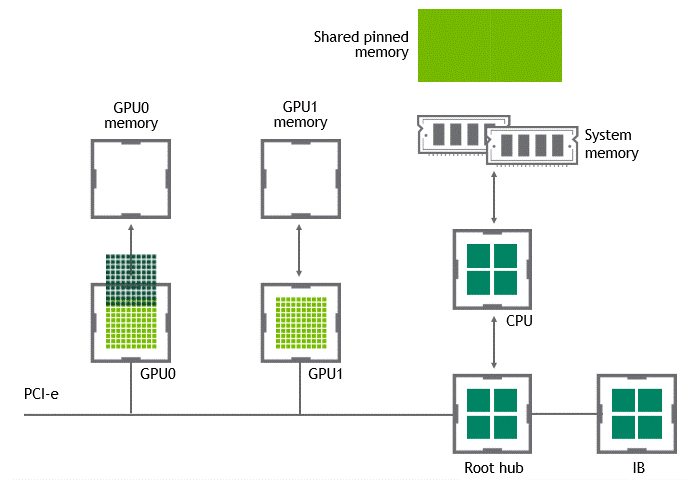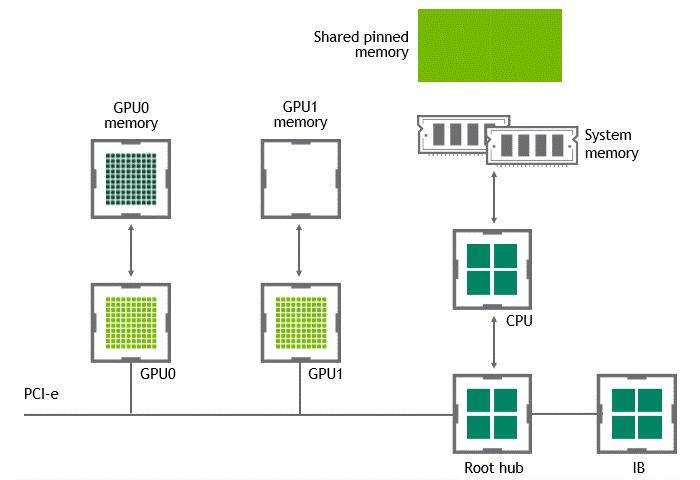
When GPUDirect Peer to Peer technology is available, copying data from a source GPU to another GPU in the same node does not require the temporary staging of the data into the host memory anymore. If both GPUs are attached to the same PCIe bus, GPUDirect P2P allows for accessing their corresponding memory without involving the CPU. The former halves the number of copy operations needed to perform the same task. Figure 4 depicts the behavior just described.
Inter-node data transfer bottleneck
In a multi-node environment where NVIDIA GPUDirect Remote Direct Memory Access technology is unavailable, transferring data between two GPUs in different nodes requires five copy operations:
- The first copy occurs when transferring the data from the source GPU to a buffer of host-pinned memory in the source node.
- Then, that data is copied to the NIC’s driver buffer of the source node.
- In a third step, the data is transferred through the network to NIC’s driver buffer of the target node.
- A fourth copy happens when copying the data from the target’s node NIC’s driver buffer to a buffer of host-pinned memory in the target node.
- The last step requires copying the data to the target GPU using the PCIe bus.
That makes a total of five copy operations. What a journey, isn’t it? Figure 5 depicts the process described before.
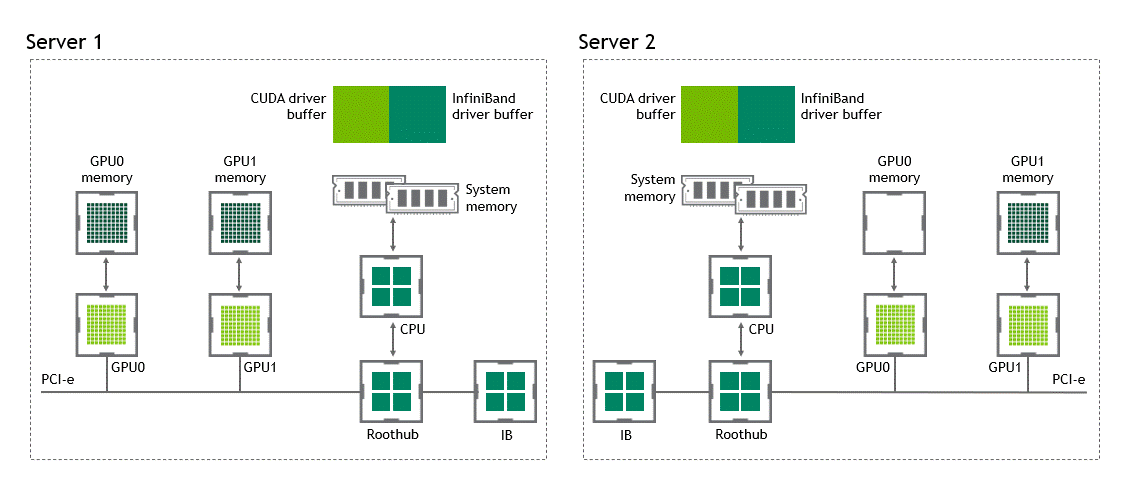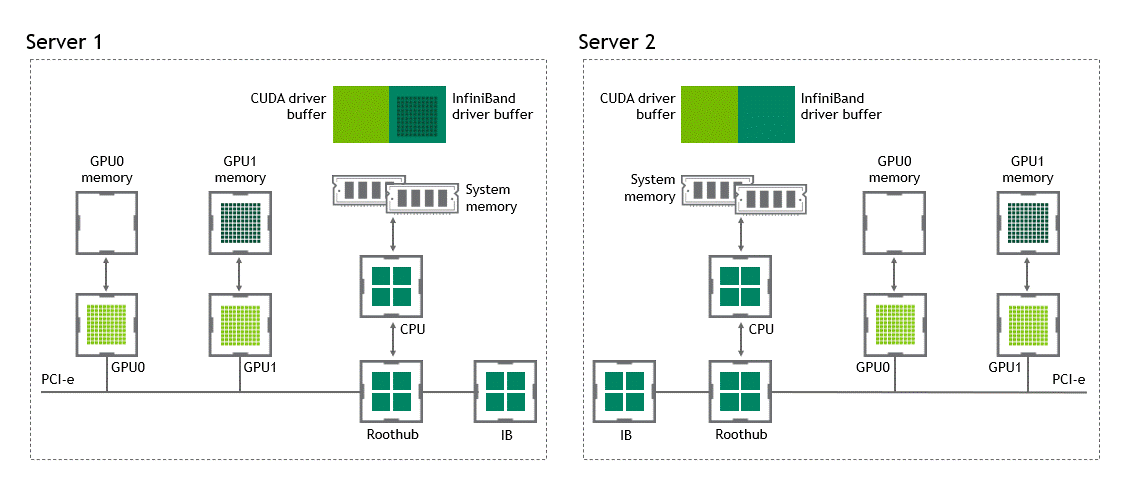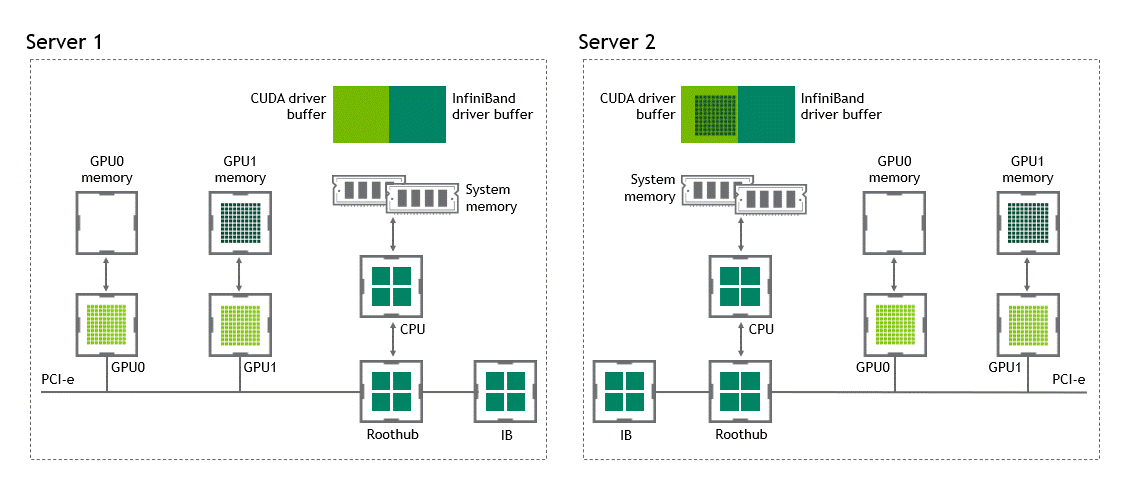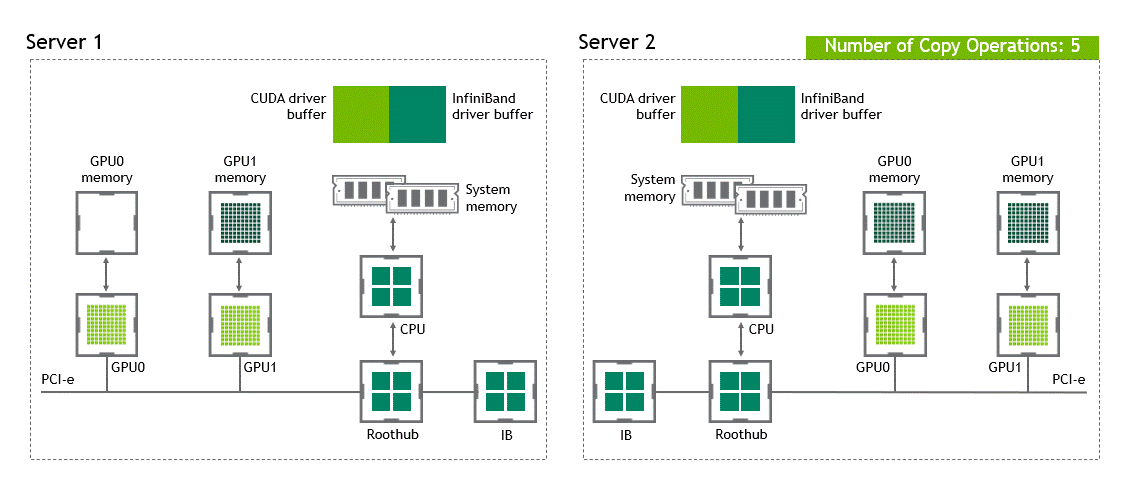
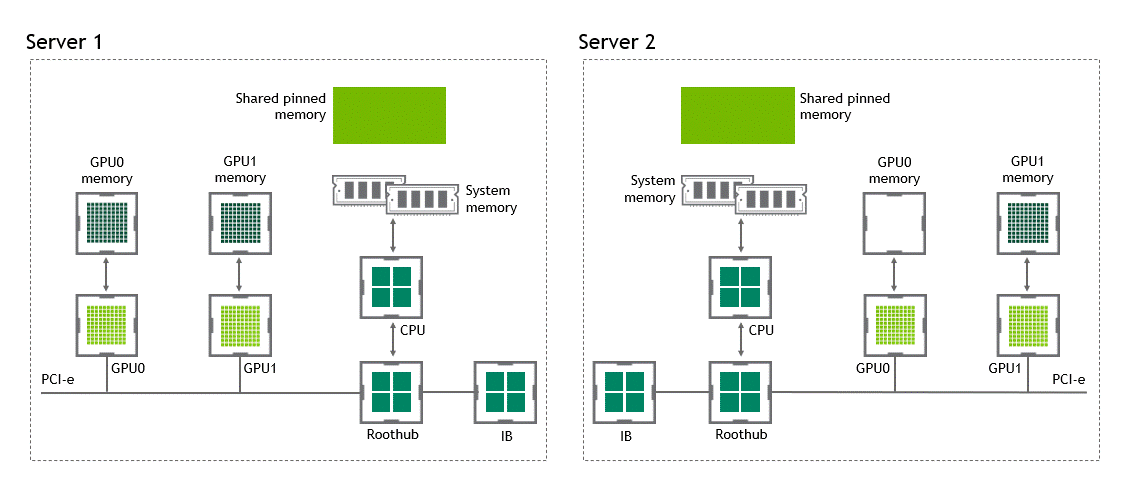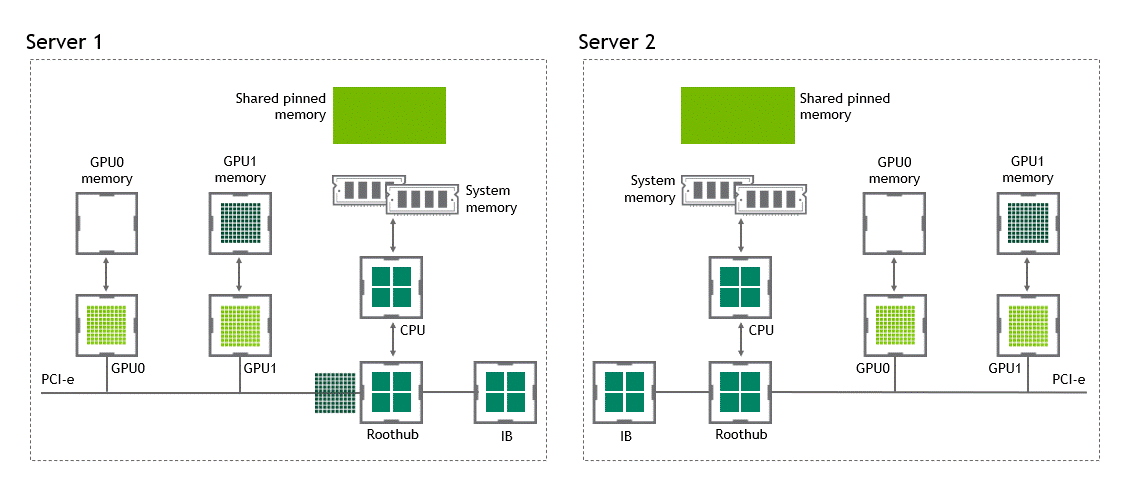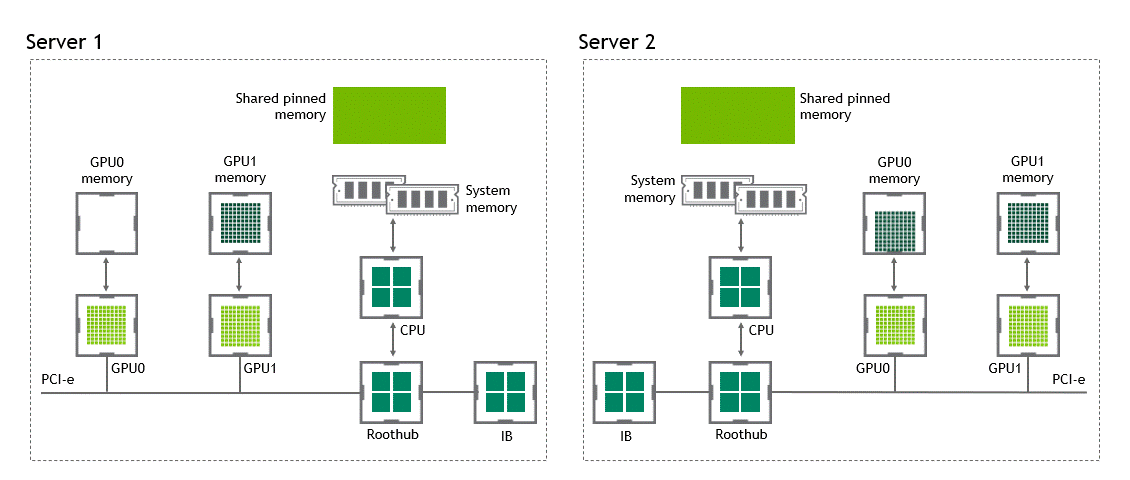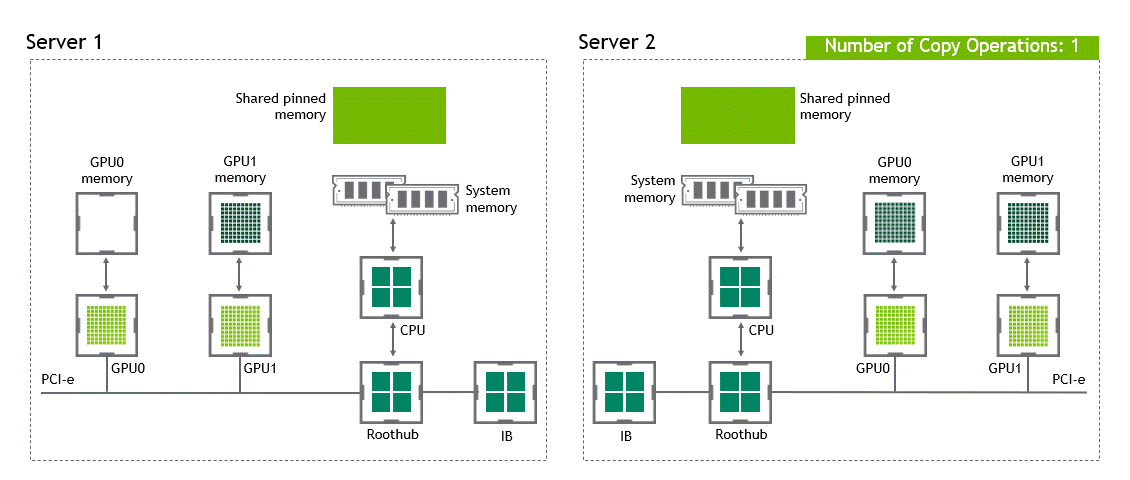
With GPUDirect RDMA enabled, the number of data copies gets reduced to just one. No more intermediate data copies in shared pinned memory. We can directly copy the data from the source GPU to the target GPU in a single run. That saves us four unnecessary copy operations, compared to a traditional setting. Figure 6 depicts this scenario.
Conclusion
In our second post, you have learned how to exploit NVIDIA GPUDirect functionality to further accelerate the data loading and data distribution stages of your pipeline.
In the third part of our trilogy, we will dive into the implementation details of a medical data science pipeline for the outlier detection of heartbeats in a continuously measured electrocardiogram (ECG) stream.
