
If you work in data analytics, you know that data ingest is often the bottleneck of data preprocessing workflows. Getting data from storage and decoding it can often be one of the most time-consuming steps in the workflow because of the data volume and the complexity of commonly used formats. Optimizing data ingest can greatly reduce this bottleneck for data scientists working on large data sets.
RAPIDS cuDF greatly speeds up data decode by implementing CUDA-accelerated readers for prevalent formats in data science.
In addition, Magnum IO GPUDirect Storage (GDS) enables cuDF to speed up I/O by loading the data directly from storage into the device (GPU) memory. By providing a direct data path across the PCIe bus between the GPU and compatible storage (for example, Non-Volatile Memory Express (NVMe) drive), GDS can enable up to 3–4x higher cuDF read throughput, with an average of 30–50% higher throughput across a variety of data profiles.
In this post, we provide an overview of GPUDirect Storage and how it’s integrated into cuDF. We introduce the suite of benchmarks that we used to evaluate I/O performance. Then, we walk through the techniques that cuDF implements to optimize GDS reads. We conclude with the benchmark results and identify cases where use of GDS is the most beneficial for cuDF.
What is GPUDirect Storage?
GPUDirect Storage is a new technology that enables direct data transfer between local or remote storage (as a block device or through file systems interface) and GPU memory.
In other words, a direct memory access (DMA) engine can now quickly move data on a direct path from the storage to GPU memory, without increasing latency and burdening the CPU with extra copying through a bounce buffer.
Figure 1 shows the data flow patterns without and with GDS. When using the system memory bounce buffer, throughput is bottlenecked by the bandwidth from system memory to GPUs. On systems with multiple GPUs and NVMe drives, this bottleneck is even more pronounced.
However, with the ability to directly interface GPUs with storage devices, the intermediary CPU is taken out of the data path, and all CPU resources can be used for feature engineering or other preprocessing tasks.
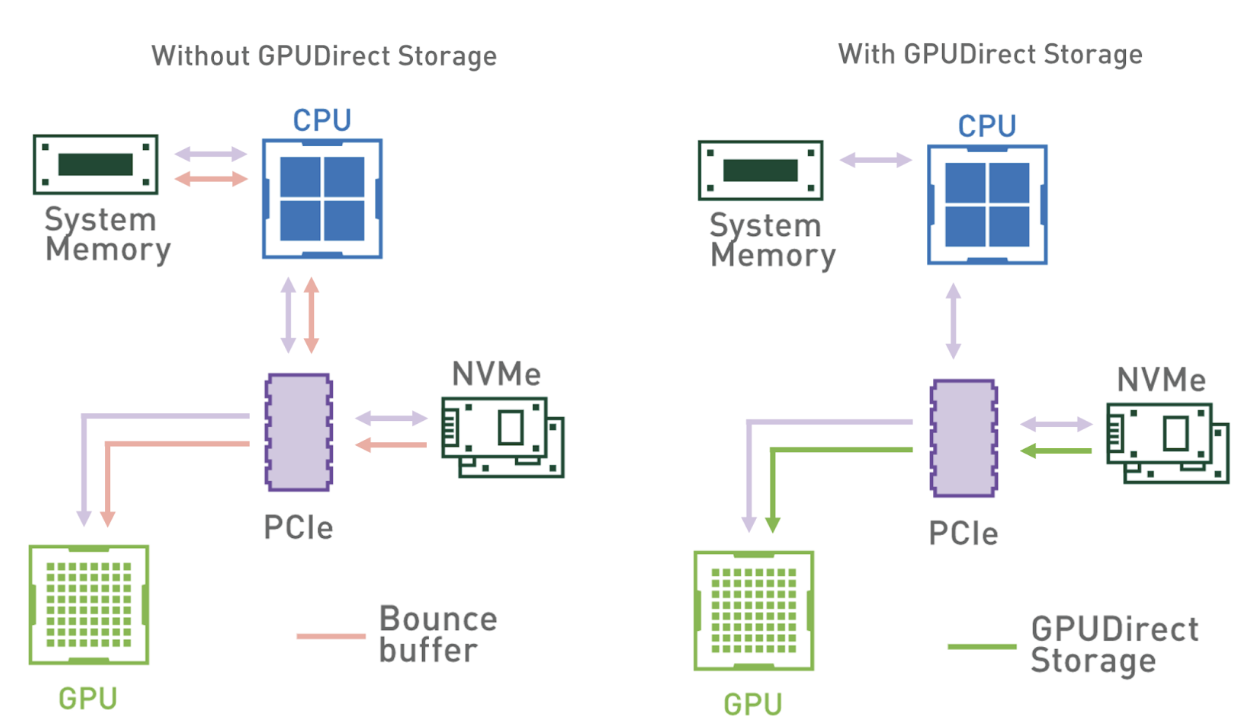
The GDS cuFile library enables applications and frameworks to leverage GDS technology to increase bandwidth and achieve lower latency. cuFile is available as part of CUDA Toolkit since version 11.4.
How does RAPIDS cuDF use GPUDirect Storage?
To increase the end-to-end read throughput, cuDF uses the cuFile APIs in its data ingest interfaces, like read_parquet and read_orc. As cuDF performs nearly all parsing on the GPU, most of the data is not needed in system memory and can be directly transferred to GPU memory.
As a result, only the metadata portion of input files is accessed by the CPU, and the metadata constitutes only a small part of the total file size. This permits the cuDF data ingest API to make efficient use of GDS technology.
Since cuDF 22.02, we have enabled the use of GDS by default. If you have cuFile installed and request to read data from a supported storage location, cuDF automatically performs direct reads through the cuFile API. If GDS is not applicable to the input file, or if the user disables GDS, data follows the bounce buffer path and is copied through a paged system memory buffer.
Benchmarking data ingest in cuDF
In response to the diversity of data science datasets, we assembled a benchmark suite that targets key data and file properties. Previous examples of I/O benchmarking used data samples such as the New York Taxi trip record, the Yelp reviews dataset, or Zillow housing data to represent general use cases. However, we discovered that benchmarking specific combinations of data and file properties have been crucial for performance analysis and troubleshooting.
Covered combinations of data and file properties
Table 1 shows the parameters that we varied in our benchmarks for binary formats. We generated pseudo-random data across the range of supported data types and collected benchmarks for each group of related types. We also independently varied the run-length and cardinality of the data to exercise run-length encoding and dictionary encoding of the target formats.
Finally, we varied the compression type in the generated files, for all values of the properties preceding. We currently support two options: Use Snappy or keep the data uncompressed.
| Data Property | Description |
| File format | Parquet, ORC |
| Data type | Integer (signed and unsigned) Float (32-, 64-bit) String (90% ASCII, 10% Unicode) Timestamp (day, s, ms, us, ns) Decimal (32-, 64-, 128-bit) List (nesting depth 2, int32 elements) |
| Run-length | Average data value repetition (1x or 32x) |
| Cardinality | Unique data values (unlimited or 1000) |
| Compression | Lossless compression type (Snappy or none) |
With all of the properties that change independently, we have a large number of varied cases: 48 cases for each file format (ORC and Parquet). To ensure fair comparison between cases, we targeted a fixed in-memory dataframe size and column count, with a default size of 512 MiB. For the purpose of this post, we introduced an additional parameter to control the target in-memory dataframe size from 64 to 4,096 MiB.
The full cuDF benchmark suite is available in the open-source cuDF repository. To focus on the impact of I/O, this post only includes the inputs benchmarks in cuDF rather than reader options or row/column selection benchmarks.
Optimizing cuDF+GDS file read throughput
Data in formats like ORC and Parquet are stored in independent chunks, which we read in separate operations. We found that the read bandwidth is not saturated when these operations are performed in a single thread, leading to suboptimal performance regardless of GDS use.
Issuing multiple GDS read calls in parallel enables overlapping of multiple storage-to-GPU copies, raising the throughput and potentially saturating the read bandwidth. As of version 1.2.1.4, cuFile calls are synchronous, so parallelism requires multithreading from downstream users.
Controlling the level of parallelism
As we did not control the file layout and number of data chunks, creating a separate thread for each read operation could have generated an excessive number of threads, leading to a performance overhead. On the other hand, if we only had a few large read calls, we might not have had enough threads to effectively saturate the read bandwidth of the storage hardware.
To control the level of parallelism, we used a thread pool and sliced larger read calls into smaller reads that could be performed in parallel.
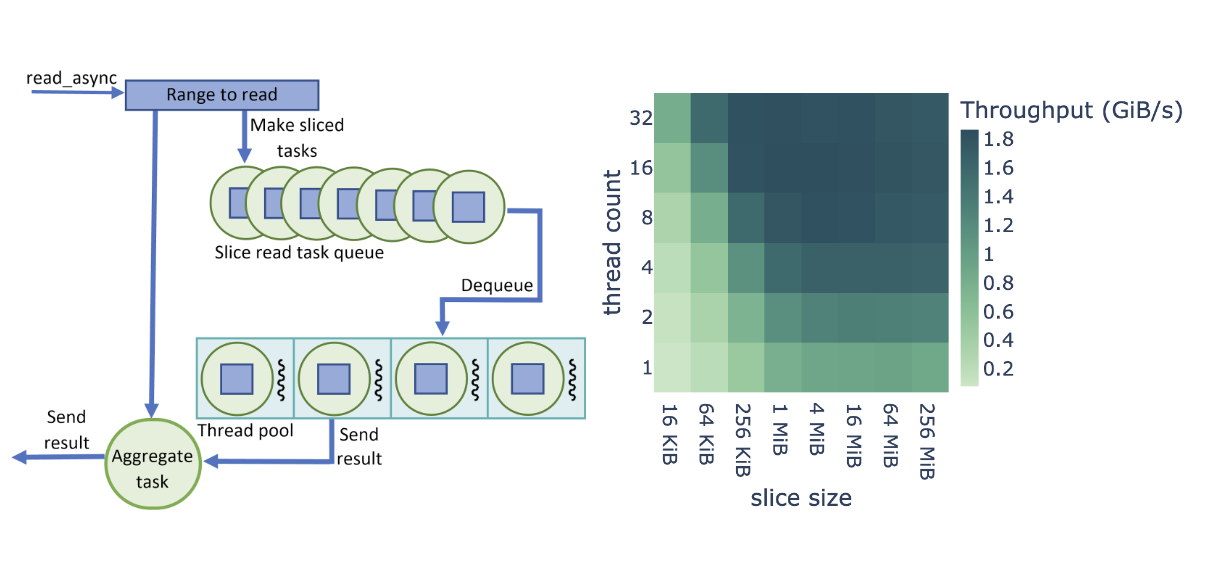
When we begin reading a file using GDS, we create a data ingest pipeline based on the thread-pool work of Barak Shoshany from Brock University. As Figure 2 shows, we split each file read operation (read_async call) in the cuDF reader into cuFile calls of fixed size, except for, in most cases, the last slice.
Instead of directly calling cuFile to read the data, a task is created for each slice and placed in a queue. The read_async call returns a task that waits for all of the sliced tasks to be completed. Callers can perform other work and wait on the aggregate task after the requested data is required to continue. When available, threads from the pool dequeue the tasks and make the synchronous cuFile calls.
Upon completion, a thread sets the task as completed and becomes available to execute the next task in the queue. As most tasks read the same amount of data, cuFile reads are effectively load-balanced between the threads. After all tasks from a given read_async call are completed, the aggregate task is complete and the caller code can continue, as the requested data range has been uploaded to the GPU memory.
Optimal level of parallelism
The size of the thread pool and the read slices greatly impacts the number of GDS read calls executed at the same time. To maximize throughput, we experimented with a range of different values for these parameters and identified the configuration that gives the highest throughput.
Figure 2 shows a performance optimization study on cuDF+GDS data ingest with tunable parameters of thread count and slice size. For this study, we defined the end-to-end read throughput as the binary format file size divided by the total ingest time (I/O plus parsing and decode).
The throughput shown in Figure 2 is averaged over the entire benchmark suite and based on a dataframe size of 512 MiB. We found that Parquet and ORC binary formats share the same optimization behavior across the parameter range, also shown in Figure 2. Small slice sizes cause higher overhead due to the large number of read tasks, and large slice sizes lead to poor utilization of the thread pool.
In addition, lower thread counts do not provide enough parallelism to saturate the NVMe read bandwidth, and higher thread counts lead to thread overhead. We discovered that the highest end-to-end read throughput was for 8-32 threads and 1-16 MiB slice size.
Depending on the use case, you may find optimal performance with different values. This is why, as of 22.04, the default thread pool size of 16 and slice size of 4 MiB are configurable through environment variables, as described in GPUDirect Storage Integration.
Impact of GDS on cuDF data ingest
We evaluated the effect that GDS use had on the performance of a few cuDF data ingest APIs using the benchmark suite described earlier. To isolate the impact of GDS, we ran the same set of benchmarks with default configuration (uses GDS) and with GDS manually disabled through an environment variable.
For accurate I/O benchmarking with cuDF benchmarks, file system caches must be cleared before each new read operation. Benchmarks measure the total time to execute a read_orc or read_parquet call (read time) and these are the values we used for comparison. GDS speedup was computed for each benchmark case file as the read time through the bounce buffer divided by the total ingest time through the direct data path.
For the GDS performance comparison, we used a NVIDIA DGX-2 with V100 GPUs and NVMe SSDs connected in a RAID 0 configuration. All benchmarks use a single GPU and read from a single RAID 0 of two 3.84-TB NVMe SSDs.
Larger files, higher speedups
Figure 3 shows the GDS speedup for a variety of files with in-memory dataframe size of 4,096 MiB. We observed that the performance improvement varies widely, between modest 10% and impressive 270% increase over the host path.
Some of the variance is due to differences in the data decode. For example, list types show smaller speedups due to the higher parsing complexity, and decimal types in ORC show smaller speedups due to overhead in fixed point decoding compared to Parquet.
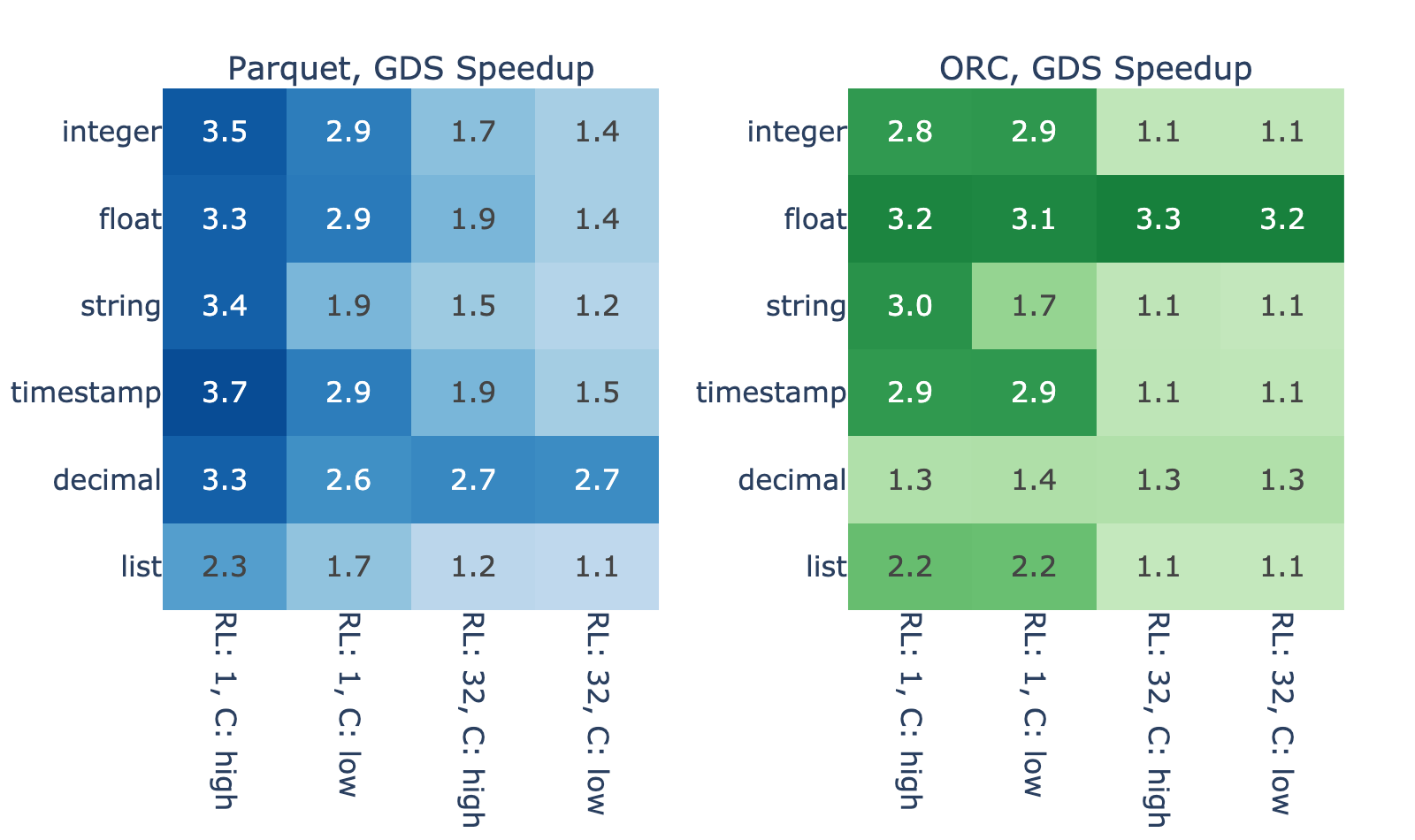
However, the decode process cannot account for the majority of variance in the results. With high correlation between the result for ORC and Parquet, you can reasonably suspect that properties like run-length and cardinality play a major role. Both properties affect how well data can be compressed/encoded, so here’s how the file size relates to these properties and, by proxy, to the GDS speedup.
Figure 4 shows the extent in which intrinsic properties of the data impact the binary file size needed to store a fixed in-memory data size. For 4,096 MiB of in-memory data, file sizes range from 0.1 to 5.8 GB across the benchmarks cases without Snappy compression. As expected, the largest file sizes generally correspond to shorter run-length and higher cardinality because data with this profile is difficult to efficiently encode.
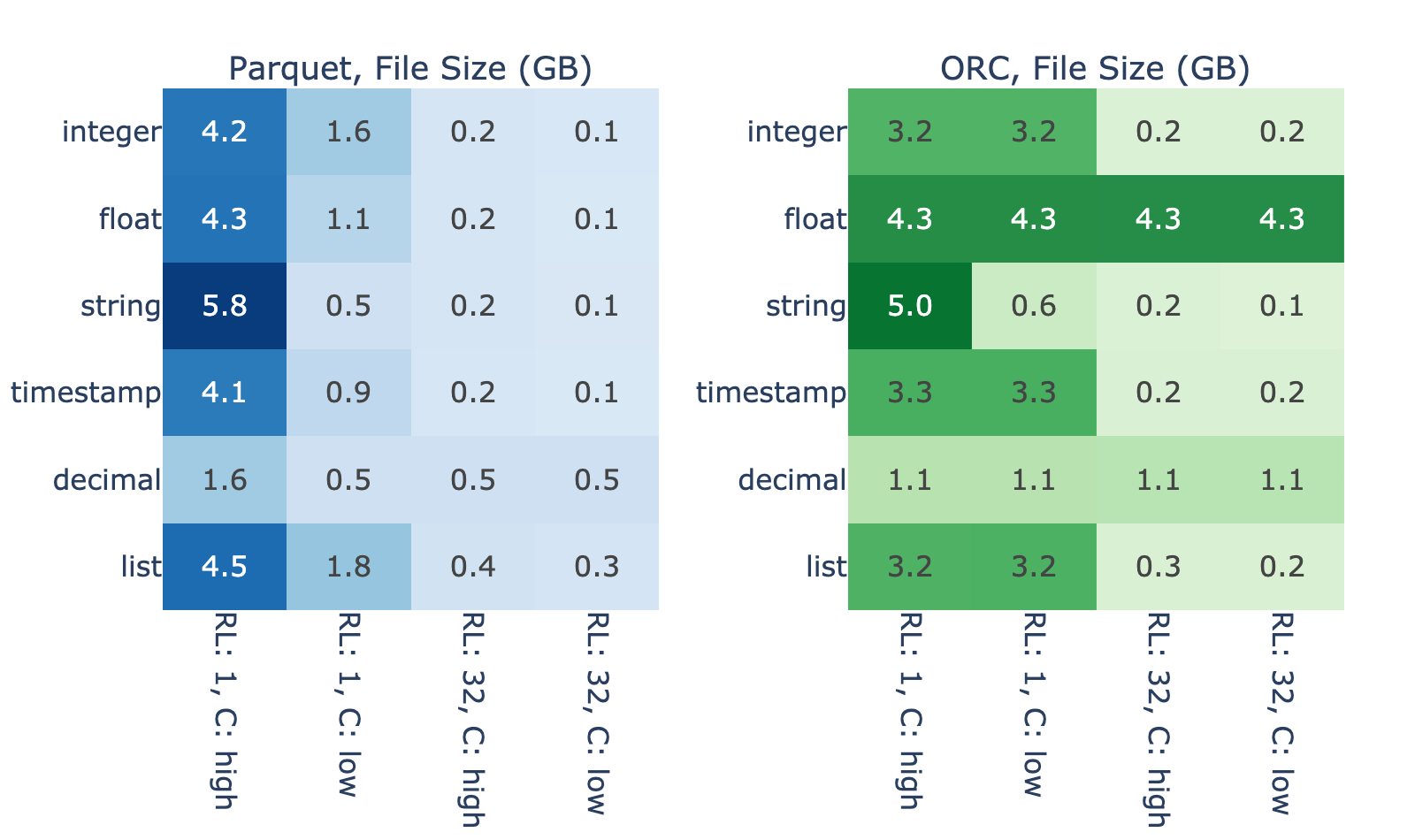
Figures 3 and 4 show strong correlation between file size and the magnitude of GDS performance benefit. We hypothesize that this is because, when reading an efficiently encoded file, I/O takes less time compared to decode so there’s little room for improvement from GDS. On the other hand, the results show that reading of files that encode poorly is bottlenecked on the I/O.
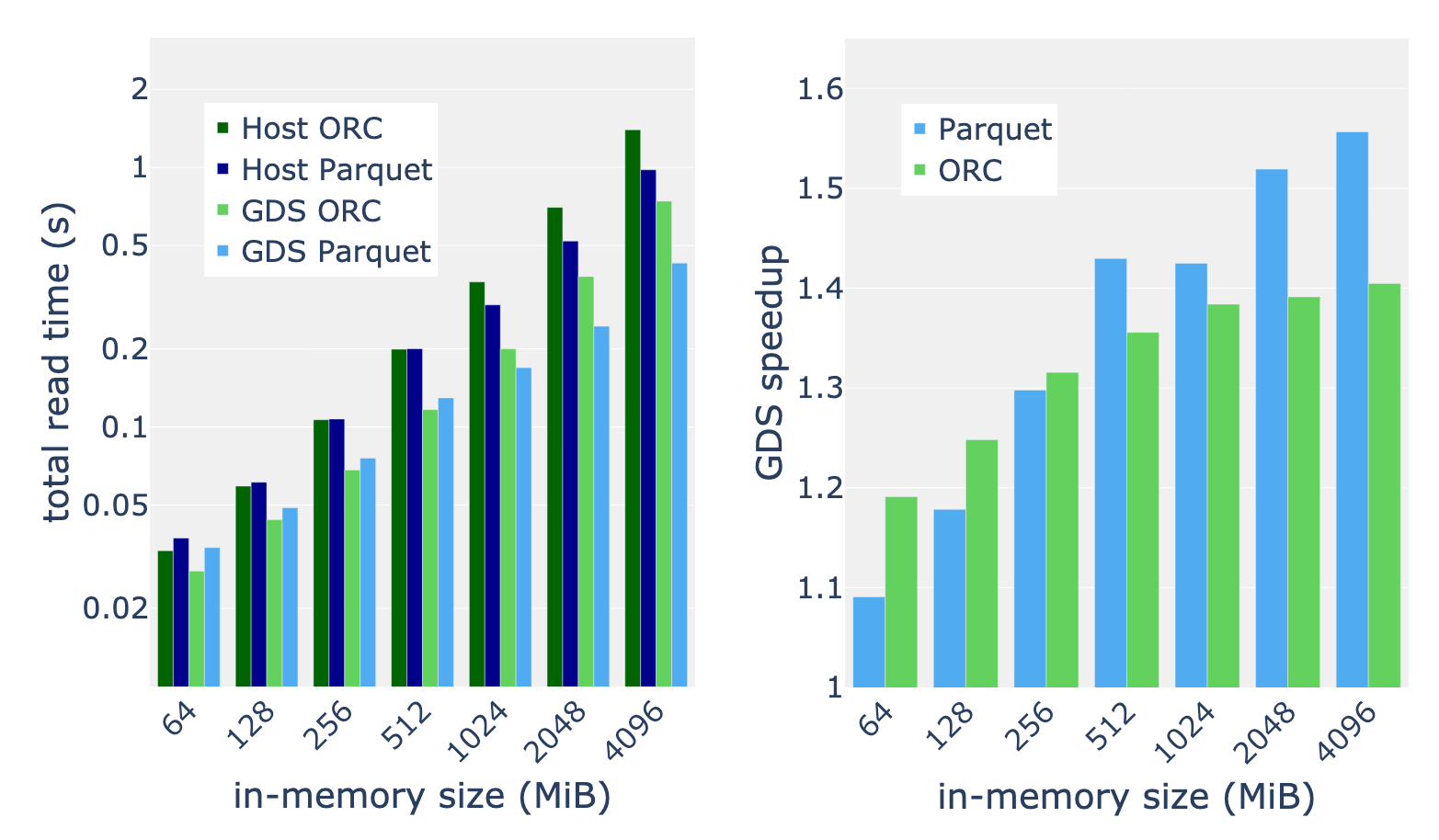
Larger data, higher speedups
We applied the full benchmark suite described in Table 1 to inputs with in-memory sizes in the range of 64 to 4,096 MiB. Taking the mean speedup over the benchmark suite, we discovered that speedup from GDS generally increases with the data size. We measure consistent 30-50% speedup for 512 MiB and greater in-memory data sizes. For the largest datasets, we found that the Parquet reader benefits more from GDS than the ORC reader.
Summary
GPUDirect Storage provides a direct data path to the GPU, reducing latency and increasing throughput for I/O operations. RAPIDS cuDF leverages GDS in its data ingest APIs to unlock the full read bandwidth of your storage hardware.
GDS enables you to speed up cuDF data ingest workloads up to 3x, significantly improving the end-to-end performance of your workflows.
Apply your knowledge
If you have not tried out cuDF for your data processing workloads, we encourage you to test our latest 22.04 release. We provide Docker containers for our releases as well as our nightly builds. Conda packages are also available to make testing and deployment easier. If you want to get started with RAPIDS cuDF, you can do so.
If you are already using cuDF, we encourage you to give GPUDirect Storage a try. It is easier than ever to take advantage of high capacity and high-performance NVMe drives. If you already have the hardware, you are a few configuration steps away from unlocking peak performance in data ingest. Stay tuned for upcoming releases of cuDF.
For more information about storage I/O acceleration, see the following resources: