

Today, NVIDIA announced the NVIDIA Jetson Xavier NX Developer Kit , which is based on the Jetson Xavier NX module. Delivering up to 21 TOPS of compute in a compact form factor with under 15W of power, Jetson Xavier NX brings server-level performance and cloud-native workflows to edge AI devices and autonomous machines.
With the Jetson Xavier NX Developer Kit, you can create amazing AI-powered applications and quickly deploy deep neural network (DNN) models and popular machine learning frameworks into the field. Initial software support from NVIDIA JetPack 4.4 Developer Preview includes CUDA Toolkit 10.2 and preview releases of cuDNN 8.0, TensorRT 7.1, and DeepStream 5.0, along with new Docker containers for machine learning and pretrained DNN models.
Jetson Xavier NX is based on NVIDIA’s groundbreaking Xavier SoC that can run multiple complex models and multiple high-definition sensor streams in parallel. It includes the following features:
- An integrated NVIDIA Volta 384-core Volta GPU with 48 Tensor Cores
- Two NVIDIA Deep Learning Accelerator engines
- Seven-way VLIW Vision Accelerator
- Six-core NVIDIA Carmel 64-bit ARMv8.2 CPU
- 8-GB 128-bit LPDDR4x
To further streamline the deployment of edge AI applications in production environments, NVIDIA has brought cloud-native technologies to Jetson, including Docker-based containerization with hardware passthrough and orchestration services like Kubernetes, along with pretrained models and container images available from the NVIDIA NGC registry.
Jetson Xavier NX Developer Kit
The Jetson Xavier NX Developer Kit bundles an open-source reference carrier board and pre-assembled heatsink/fan as shown in Figure 2, including a 19V power supply and M.2-based 802.11 WLAN+BT module. In addition to the bootable microSD card slot, an M.2 Key-M NVMe socket is provided on the underside of the carrier for expanded high-speed storage.
Because the Xavier NX module is backwards-compatible with Jetson Nano (B01), their carrier boards share some commonality— also included are dual MIPI CSI camera connectors, along with four USB 3.1 ports, HDMI, DisplayPort, Gigabit Ethernet, and a 40-pin GPIO header.
The key features and interfaces of the kit’s carrier board are shown below in Table 1. For more information about the core processing capabilities and specifications of the Jetson Xavier NX compute module, see the Introducing Jetson Xavier NX, the World’s Smallest AI Supercomputer post and the Jetson Xavier NX Module Data Sheet.

| NVIDIA Jetson Xavier NX Developer Kit | |
| Compute | 260-pin SO-DIMM connector to Jetson Xavier NX module |
| USB | (4x) USB 3.1 Type A | USB 2.0 Micro B (device mode + recovery) |
| Camera† | (2x) MIPI CSI x2 (15-pin flex connectors) |
| Display | HDMI 2.0 | DisplayPort 1.4 |
| Storage | microSD card slot | M.2 Key-M 2280 NVMe (PCIe x4) |
| Networking | Gigabit Ethernet (RJ45) |
| Wireless†† | M.2 Key-E (2×2 802.11 WLAN + BT 5.0 module provided) |
| 40-Pin Header | (2x) I2C, (2x) SPI, UART, I2S, Audio Clock, GPIOs, PWMs |
| Button Header | Power, Reset, Recovery, Disable Auto Power-On |
| Power Supply | 9-20V (19.5V supply provided) | 10/15W power modes |
† Supported MIPI CSI sensors include IMX219 (see additional Jetson Partner Supported Cameras)
†† The included M.2 Key-E wireless module is an AzureWave AW-CB375NF using the Realtek RTL8211 chipset
The Jetson Xavier NX Developer Kit is available now for $399. To access the Jetson Xavier NX technical documentation, reference design files, and software, see the Jetson Downloads Center.
JetPack 4.4 Developer Preview
The NVIDIA JetPack SDK contains the libraries, tools, and core OS for building AI applications on Jetson. The JetPack 4.4 Developer Preview adds support for Jetson Xavier NX. It includes CUDA Toolkit 10.2 along with preview releases of cuDNN 8.0, TensorRT 7.1, DeepStream 5.0, and the NVIDIA Container Runtime for deploying cloud-native services, in addition to the other components shown in Table 2. Pre-built package installers for popular machine learning frameworks such as TensorFlow and PyTorch are also available at the Jetson Zoo, in addition to new framework containers for JetPack on NGC.
| NVIDIA JetPack 4.4 Developer Preview | |
| Linux For Tegra R32.4.2 | Ubuntu 18.04 LTS aarch64 |
| CUDA Toolkit 10.2 | cuDNN 8.0 DP |
| TensorRT 7.1 DP | GStreamer 1.14.5 |
| VisionWorks 1.6 | OpenCV 4.1.1 |
| DeepStream 5.0 DP | VPI 0.2 DP |
| OpenGL 4.6 / GLES 3.2 | Vulkan 1.2 |
| L4T Multimedia API R32.4.2 | L4T Argus Camera API 0.97 |
| NVIDIA Nsight Systems 2020.2 | NVIDIA Nsight Graphics 2020.1 |
| NVIDIA SDK Manager 1.1.0 | NVIDIA Container Runtime 1.0.1 |
Download JetPack 4.4 Developer Preview for Jetson Xavier NX, Jetson AGX Xavier, Jetson TX1/TX2, and Jetson Nano. After receiving a new Jetson Xavier NX Developer Kit, flash your microSD card with the JetPack image, as described in the Getting Started guide.
This Developer Preview release can be used to get up and running with the Jetson Xavier NX Developer Kit and begin application development, while the production JetPack 4.4 SDK is planned to be released later this summer. After you have JetPack installed, you can follow along with some of the AI-driven Jetson community projects.
Deep learning inferencing benchmarks
Jetson can be used to deploy a wide range of popular DNN models and ML frameworks to the edge with high performance inferencing, for tasks like real-time classification and object detection, pose estimation, semantic segmentation, and natural language processing (NLP).
The JetPack SDK and NVIDIA CUDA-X support common to the Jetson and NVIDIA discrete GPUs means that you can easily scale your performance and size, weight, and power (SWaP) consumption down to as little as 5W without having to re-write your applications. Figure 3 shows the inferencing benchmarks of popular vision DNNs across Jetson Nano, Jetson TX2, Jetson Xavier NX, and Jetson AGX Xavier with JetPack 4.4 Developer Preview and TensorRT 7.1.These results can be reproduced by running the open jetson_benchmarks project from GitHub.
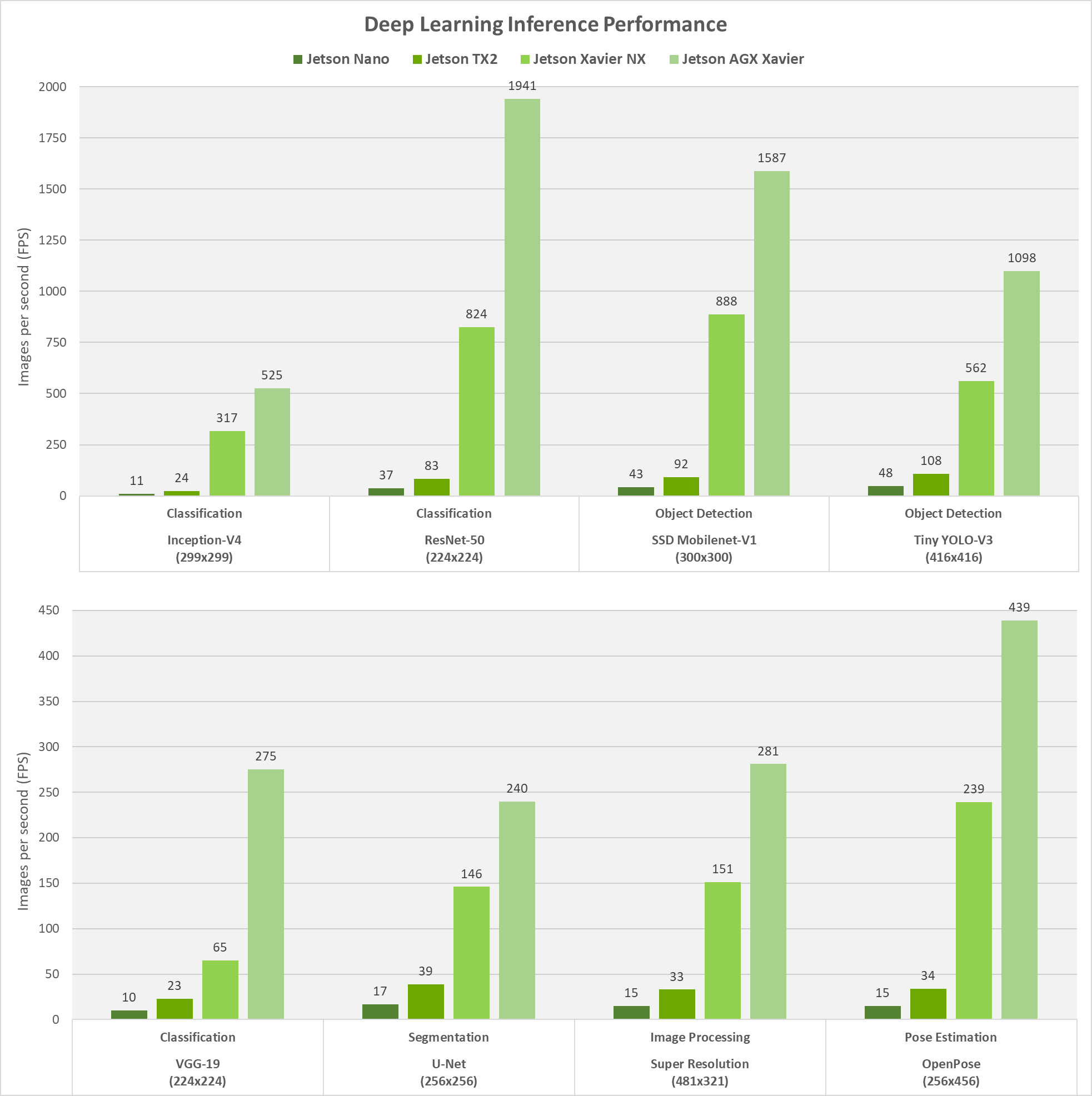
On Jetson Xavier NX and Jetson AGX Xavier, both NVIDIA Deep Learn Accelerator (NVDLA) engines and the GPU were run simultaneously with INT8 precision, while on Jetson Nano and Jetson TX2 the GPU was run with FP16 precision. Jetson Xavier NX achieves up to 10X higher performance than Jetson TX2, with the same power and in a 25% smaller footprint.
During these benchmarks, each platform was run with maximum performance (MAX-N mode for Jetson AGX Xavier, 15W for Xavier NX and TX2, and 10W for Nano). The maximum throughput for these vision-based tasks was obtained with batch sizes not exceeding a latency threshold of 15ms. — Otherwise, a batch size of one was used for networks where the platform exceeded this latency threshold. This methodology provides a balance between deterministic low-latency requirements for real-time applications and maximum performance for multi-stream use-case scenarios.
We also provide benchmarking results for BERT on question answering. BERT is a versatile architecture that has grown in popularity from its successful applications across several NLP tasks, including QA, intent classification, sentiment analysis, translation, name/entity recognition, paraphrasing, recommender systems, autocompletion, and more.
BERT has traditionally been too complex to deploy locally onboard edge devices, especially the BERT Large variant. However, with Tensor Core optimizations for BERT included in TensorRT, BERT can easily be run on Jetson Xavier NX and Jetson AGX Xavier.
Deploying BERT to the edge is useful for low-latency, intelligent human-machine interaction (HMI) and conversational AI, as in the chatbot portion of the multi-container demo later in this post, which also performs automatic speech recognition (ASR) locally and does not rely on cloud connectivity.
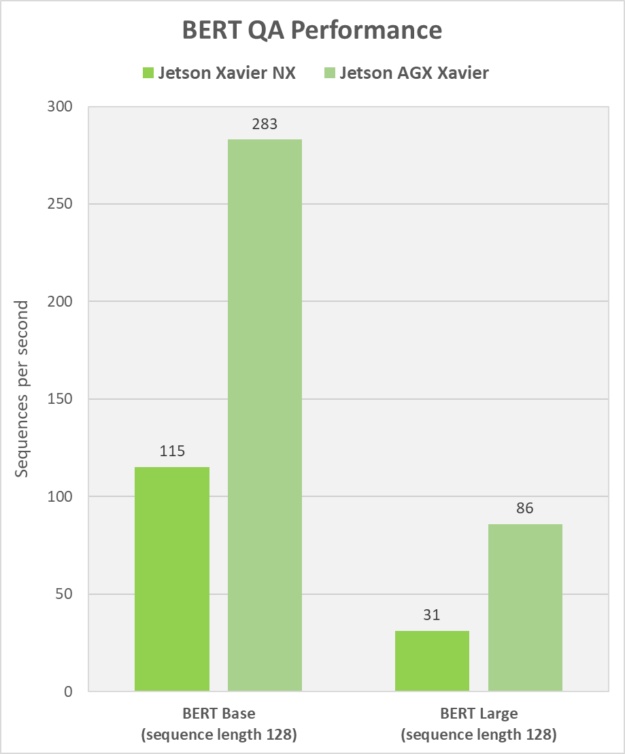
Figure 4 shows the runtime performance of BERT Base and BERT Large on question answering, using a 50ms latency threshold for NLP tasks. These results are measured in sequences per second, where each sequence of text is a query or question that BERT answers. The performance of BERT on Jetson provides near-instant feedback to the user, with latencies as low as 5.9ms. This allows BERT processing to be executed concurrently with other real-time processing streams, such as video.
Bringing cloud-native methodologies to the edge
Until now, software for embedded and edge devices has been written as monolithic systems. The complexity of upgrading a monolithic software image increases the risk of bugs and makes the cadence of updates difficult to accelerate. This is especially problematic for edge devices with AI, which requires frequent updates to sustain rapid capability improvements. Modern expectations for agile capabilities and constant innovation—with zero downtime—calls for a change in how software for embedded and edge devices are developed and deployed.
Adopting cloud-native paradigms like microservices, containerization, and container orchestration at the edge is the way forward.
Microservice architecture, containerization, and orchestration have enabled cloud applications to escape the constraints of the monolithic workflow. Now, Jetson is bringing the cloud-native transformation ideology to AI edge devices.
Jetson is the leading AI edge computing platform, with close to half a million developers. It’s powered by JetPack SDK with the same CUDA-X accelerated computing stack and NVIDIA Container Runtime used in data centers and workstations around the world.
With several development and deployment containers for Jetson, containerized frameworks and pretrained AI models hosted on NVIDIA NGC, it can serve as building blocks to AI application development. The latest Jetson Xavier NX enables full-featured, multi-modal AI applications in the smallest form factor possible.
We welcome cloud-native technologies that enable customers with lifecycle agility needed to scale their businesses. Time-to-market is accelerated with scalable software development. Why? Because updating product lifecycles becomes less process-heavy when you don’t have to also update other application components simultaneously.
Multi-container demo
The NVIDIA multi-container demo for Jetson Xavier NX shows the process of developing and deploying a service robot AI application using cloud-native approaches. Service robots are autonomous robots that typically interact with people in retail, hospitality, healthcare, or warehouses.
Consider a service robot whose purpose is to improve customer service in a retail department store by interacting with shoppers. The robot can only provide helpful answers to customer queries if it can perform many computational tasks including human identification, interaction detection, human pose detection, speech detection, and NLP. The robot would have to run the multiple AI models needed to support these functions.
With the cloud-native approach, AI models can be developed independently, containerized with all dependencies included, and deployed onto any Jetson device.
The demo runs four containers simultaneously on Jetson Xavier NX with seven deep learning models, including pose estimation, face and gaze detection, people counting, speech recognition, and BERT question answering. The results are that these service building-block containers are easily modified and re-deployed without disruption, giving zero downtime and seamless update experience.
The computational horsepower of Jetson Xavier NX provides you with the capability of running all these containers at one time, without sacrificing real-time performance across multiple streams of sensor data. You can download the demo from the NVIDIA-AI-IOT/jetson-cloudnative-demo GitHub repo with the containers hosted on NGC.
Take the next leap in edge computing
Computational performance, a compact, power-efficient form factor, and comprehensive software support make the Jetson Xavier NX Developer Kit an ideal platform for creating advanced AI-powered applications to deploy to the edge.
Get started today by ordering your devkit, installing JetPack SDK, and following along with some of the exciting Jetson community projects and Jetson Developer Forums threads.
We are hosting a series of webinars focused on Jetson Xavier NX with live Q&A during NVIDIA GTC Digital:
- Register for a deep dive into the new Jetson Xavier NX Developer Kit on Wednesday, May 20 at 11:30 AM PST.
- Learn how to develop for Jetson using cloud containers on Tuesday, May 26 at 10 AM PST.

