

Today NVIDIA announced Jetson Xavier NX, the world’s smallest, most advanced embedded AI supercomputer for autonomous robotics and edge computing devices. Capable of deploying server-class performance in a compact 70x45mm form-factor, Jetson Xavier NX delivers up to 21 TOPS of compute under 15W of power, or up to 14 TOPS of compute under 10W. The Jetson Xavier NX module (Figure 1) is pin-compatible with Jetson Nano and is based on a low-power version of NVIDIA’s Xavier SoC that led the recent MLPerf Inference 0.5 results among edge SoC’s, providing increased performance for deploying demanding AI-based workloads at the edge that may be constrained by factors like size, weight, power, and cost.

As shown in Figure 2, Jetson Xavier NX includes an integrated 384-core NVIDIA Volta GPU with 48 Tensor Cores, 6-core NVIDIA Carmel ARMv8.2 64-bit CPU, 8GB 128-bit LPDDR4x, dual NVIDIA Deep Learning Accelerator (NVDLA) engines, 4K video encoders and decoders, dedicated camera ingest for up to 6 simultaneous high-resolution sensor streams, PCIe Gen 3 expansion, dual DisplayPort/HDMI 4K displays, USB 3.1, and GPIOs including SPI, I2C, I2S, CAN bus, and UART. Refer to table 1 below for a list of features and the Jetson Xavier NX Module Datasheet for the full specifications. The shared memory fabric allows the processors to share memory freely without incurring extra memory copies (known as ZeroCopy), which efficiently improves bandwidth utilization and throughput of the system.
| NVIDIA Jetson Xavier NX | |
| CPU | 6-core NVIDIA Carmel 64-bit ARMv8.2 @ 1400MHz* (6MB L2 + 4MB L3) |
| GPU | 384-core NVIDIA Volta @ 1100MHz with 48 Tensor Cores |
| DL | Dual NVIDIA Deep Learning Accelerator (NVDLA) engines |
| Memory | 8GB 128-bit LPDDR4x @ 1600MHz | 51.2GB/s |
| Storage | 16GB eMMC 5.1 |
| Encoder† | (2x) 4Kp30 | (6x) 1080p60 | (12x) 1080p30 Maximum throughput up to (2x) 464MP/s – H.265 Main |
| Decoder† | (2x) 4Kp60 | (4x) 4Kp30 | (12x) 1080p60 | (32x) 1080p30 Maximum throughput up to (2x) 690MP/s – H.265 Main |
| Camera†† | (12x) MIPI CSI-2 lanes | 3×4 or 6×2 cameras
Up to 6 cameras (36 via virtual channels) |
| Display | (2x) DP 1.4 / eDP 1.4 / HDMI 2.0 a/b @ 4Kp60 |
| Ethernet | 10/100/1000 BASE-T Ethernet |
| USB | USB 3.1 (10Gbps) + (3x) USB 2.0 |
| PCIe‡ | (2x) PCIe Gen 3 controllers, 5 lanes | 1×1 + 1×1/2/4 |
| Misc I/Os | (3x) UART, (2x) SPI, (2x) I2C, I2S, CAN, GPIOs |
| Socket | 260-pin SODIMM edge connector, 70x45mm |
| Thermals^ | -25°C to 90°C (Tj) |
| Power | 10W / 15W modes, 5V input |
Table 1: Jetson Xavier NX compute module features and capabilities
* CPU maximum operating frequency is 1400MHz in 4/6-core mode, or 1900MHz in dual-core mode
† Maximum number of concurrent streams up to the aggregate throughput. Supported video codecs: H.265, H.264, VP9
Please refer to the Jetson Xavier NX Module Data Sheet for specific codec and profile specifications.
†† MIPI CSI-2, D-PHY V1.2 (2.5Gb/s per lane, up to 30Gbps total).
‡ PCIe 1×1 supports Root Port only, 1×1/2/4 supports Root Port or Endpoint modes
^ Operating temperature range, Xavier SoC junction temperature (Tj)
Jetson Xavier NX is supported by NVIDIA’s complete CUDA-X software stack and JetPack SDK for AI development, running popular machine learning frameworks and complex DNNs on multiple high-resolution sensor streams simultaneously, in addition to realtime computer vision, accelerated graphics and rich multimedia applications in a full desktop Linux environment. Jetson’s compatibility with NVIDIA’s AI accelerated computing platform makes for ease of development and seamless migration between cloud and edge.
The Jetson Xavier NX module will be available in March 2020 for $399 in volume, and embedded designers can create production devices and systems for the Jetson Xavier NX module by referring to the design collateral available for download, including the Jetson Xavier NX Design Guide. Pin-compatibility with Jetson Nano allows for shared designs and straightforward tech-insertion upgrades to Jetson Xavier NX. Hardware design partners from the Jetson Ecosystem are also able to provide custom design services and system integrations, in addition to offering off-the-shelf carriers, sensors, and accessories.
Software developers can get started building AI applications today for Jetson Xavier NX by using the Jetson AGX Xavier Developer Kit, and applying a device configuration patch to JetPack which makes the device behave as a Jetson Xavier NX. Through software, it will change the number of CPU and GPU cores available, in addition to setting the core clock frequencies and voltages across the system. The patch is fully reversible can be used to approximate the performance of Jetson Xavier NX prior to availability of the hardware.
Jetson Xavier NX defines default power modes for 10 and 15W, achieving between 14 and 21 TOPS peak performance depending on the active mode. The nvpmodel tool used to manage power profiles adjusts the maximum clock frequencies for the CPU, GPU, memory controller, and miscellaneous SoC clocks, along with the number of CPU clusters online – these settings are shown in table 2 for the pre-defined 10W and 15W modes of Jetson Xavier NX. The CPU is arranged in three clusters of 2 cores each, and has a maximum operating frequency of 1400MHz in 4/6-core mode and up to 1900MHz in dual-core mode for applications that may require greater single-threaded vs. multi-threaded performance.
| NVIDIA Jetson Xavier NX – Power Modes | ||
| 10W Mode | 15W Mode | |
| Performance | 14 TOPS (INT8) | 21 TOPS (INT8) |
| CPU | 2-core @ 1500MHz 4-core @ 1200MHz |
2-core @ 1900MHz
4/6-core @ 1400Mhz |
| GPU | 384 CUDA Cores, 48 Tensor Cores @ 800MHz* | 384 CUDA Cores, 48 Tensor Cores @ 1100MHz* |
| DLA | Dual NVDLA engines @ 900MHz | Dual NVDLA engines @ 1100MHz |
| Memory | 8GB 128-bit LPDDR4x @ 1600MHz | 51.2GB/s | |
Table 2: Jetson Xavier NX maximum operating frequencies and core configurations for 10W and 15W power modes.
* When NVDLA in use, GPU maximum operating frequency is 600MHz (10W mode) and 1000MHz (15W mode)
Depending on workload, the Dynamic Voltage and Frequency Scaling (DVFS) governor scales the frequencies at runtime up to their maximum limits as defined by the active nvpmodel, so power consumption is reduced at idle and depending on processor utilization. The nvpmodel tool also makes it easy to create and customize new power modes depending on application requirements and TDP. Power profiles can be edited and added to the /etc/nvpmodel.conf configuration file, and a GUI widget has been added to the Ubuntu status bar to easily manage and switch power modes at runtime.
Deep Learning Inferencing Benchmarks
Today NVIDIA also announced that it captured the top spot in 4 out of 5 categories from the MLPerf Inference 0.5 benchmarks, of which Jetson AGX Xavier was the leader among edge computing SoC’s, including all of the vision-based tasks: image classification with Mobilenet and ResNet-50, and object detection with SSD-Mobilenet and SSD-ResNet. NVIDIA GPUs were the only one of ten competing chip architectures to submit results in all five inferencing tests that were defined by MLPerf.
For reference of scalability between members of the Jetson family, we also measured inferencing performance across Jetson Nano, Jetson TX2, Jetson Xavier NX, and Jetson AGX Xavier on popular DNN models for image classification, object detection, pose estimation, segmentation, and others. These results, shown in Figure 3 below, were run with JetPack and NVIDIA’s TensorRT inferencing accelerator library that optimizes networks for realtime performance that were trained in popular ML frameworks like TensorFlow, PyTorch, Caffe, MXNet, and others.
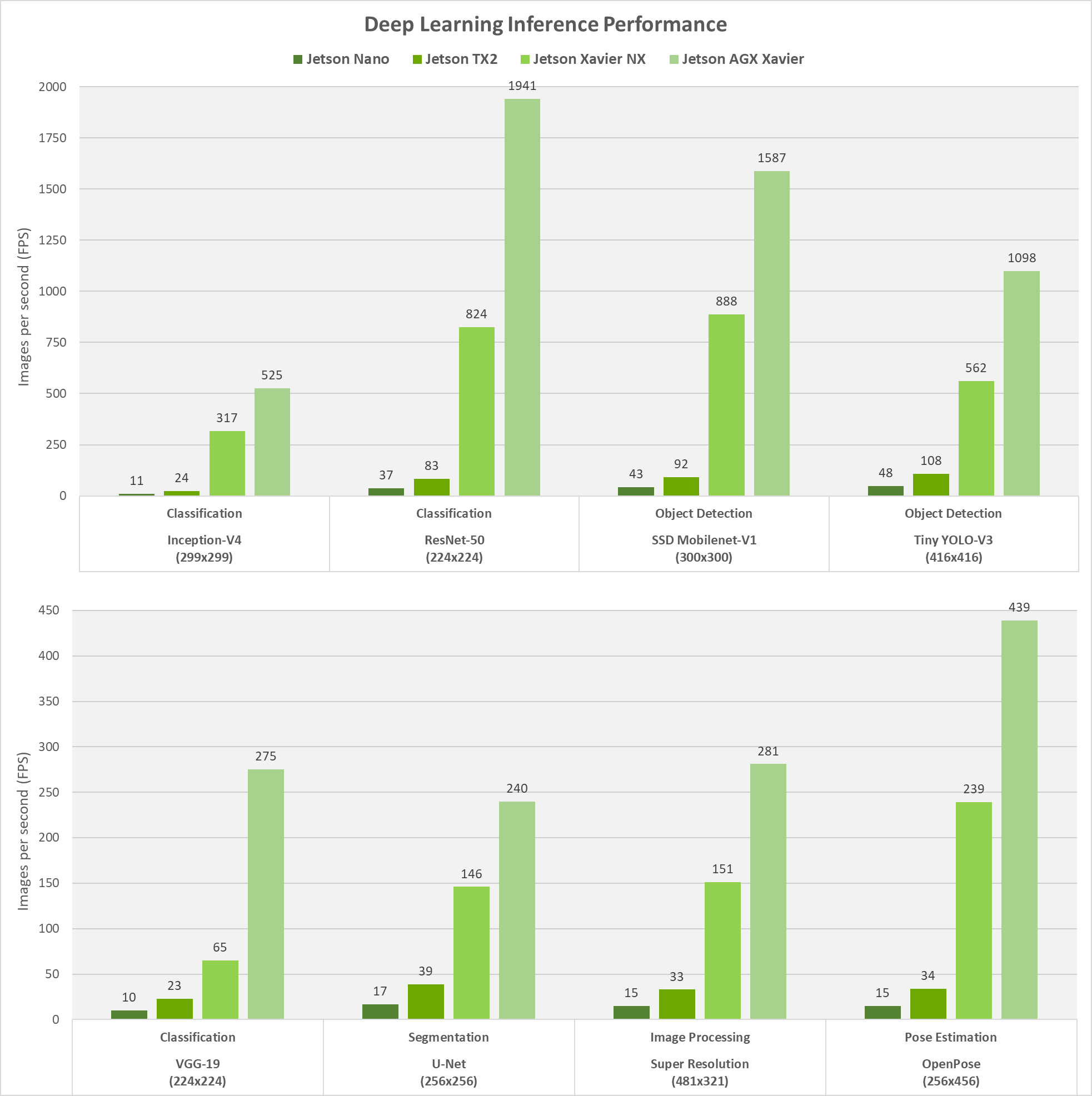
Jetson Xavier NX achieves up to 10X higher performance than Jetson TX2, with the same power and in a 25% smaller footprint. During these benchmarks, each platform was run with maximum performance (MAX-N mode for Jetson AGX Xavier, 15W for Xavier NX and TX2, and 10W for Nano). The maximum throughput was obtained with batch sizes not exceeding a latency threshold of 16ms, otherwise a batch size of one was used for networks where the platform exceeded this latency threshold. This methodology provides a balance between deterministic low-latency requirements for realtime applications and also maximum performance for multi-stream use-case scenarios.
On Jetson Xavier NX and Jetson AGX Xavier, both NVDLA engines and the GPU were run simultaneously with INT8 precision, while on Jetson Nano and Jetson TX2 the GPU was run with FP16 precision. The Volta architecture GPU with Tensor Cores in Jetson Xavier NX is capable of up to 12.3 TOPS of compute, while the module’s DLA engines produce up to 4.5 TOPS each.
In addition to running neural networks with TensorRT, ML frameworks can be natively installed on Jetson with acceleration through CUDA and cuDNN, including TensorFlow, PyTorch, Caffe/Caffe2, MXNet, Keras, and others. The Jetson Zoo includes pre-built installers and build instructions for these, in addition to IoT frameworks like AWS Greengrass and container engines like Docker and Kubernetes.

 Develop Breakthrough AI Products
Develop Breakthrough AI Products
Jetson Xavier NX opens up new opportunities for deploying next-generation autonomous systems and intelligent edge devices that require high-performance AI and complex DNN’s in a small, low-power footprint – think mobile robots, drones, smart cameras, portable medical equipment, embedded IoT systems, and more. NVIDIA’s JetPack SDK with support for CUDA-X provides the complete tools to develop cutting-edge AI solutions and scale your application between the cloud and edge with world-leading performance.
Get started today with the available design documents and the JetPack patch to conFigure the Jetson AGX Xavier Developer Kit as a Jetson Xavier NX. We look forward to seeing what you create! For information and support, visit the NVIDIA Embedded Developer site and DevTalk forums for help from experts in the community.