When developing an application from scratch it is feasible to design the code, data structures, and data movement to support accelerators. However when facing an existing application it is often hard to know where to start, what to expect, and how best to make use of an accelerator like a GPU. Based on our experience working with various application developers to help them accelerate applications using NVIDIA GPUs, we have documented a process that allows one to incrementally add improvements to the code. It’s not complex, and to some people it may be obvious, but even for experts writing it down helps to structure the effort and leads to faster results.
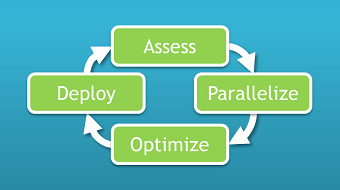
The process consists of four stages: Assess, Parallelize, Optimize, Deploy, or APOD, executed in a cycle. Having identified where to start developing, our goal is to realize and deploy a benefit before returning to the first stage, Assess, and adding further improvements.
Assess
The first step is to assess the existing code to identify which parts take the most time by analysing the application with one or more realistic data sets. By profiling the code we can identify the hot spots, which we then analyse to estimate how changing the hot spot performance will help—for example, we need to consider the value of strong and weak scaling and how they relate to the overall performance. The assessment step is crucial, both at the outset when facing a non-accelerated code and in subsequent iterations when evaluating progress and building progress.
Profiling
Many developers will have some measure of intuition about where their application spends most of its cycles, but profiling the application is always worthwhile to validate assumptions. In particular, consider using multiple different data sets to see how the behaviour changes for different types of problems, including those that users would like to address in the future. By examining the application with realistic workloads you can be sure that you will focus your effort on the areas that will give the most benefit for your users.
Myriad tools are available to help profile applications. For example. either gprof or VTune can make the task very simple. If you’re prepared to add timers in the code you could also use a high-resolution timer or the NVIDIA Tools Extension Library (NVTX) together with Nsight (available in Visual Studio and Eclipse editions). Be aware that when using standalone profiling tools, enabling a high level of detail can make be intrusive and in some instances can change the performance behaviour of the application, kind of like Heisenberg’s Uncertainty Principle!
Scaling
Strong scaling (often equated with Amdahl’s Law) is a measure of how, for a given problem size, performance changes as more processors are added to the system. The greater the fraction of work that is parallelized, the greater the potential speed-up. For many applications, the users want to solve existing problems faster which means that strong scaling is important. Weak scaling, however, is a measure of how the performance per unit of work changes as more processors are added. Often equated with Gustafson’s Law, weak scaling indicates what happens when the problem size grows as the number of processors increases. Many applications crave weak scaling to allow users to solve problems with greater accuracy (e.g. higher resolution) or to solve larger problems than those in use today. Understanding the short- and long-term goals, in terms of strong or weak scaling (or a combination), helps us to focus our efforts and estimate the potential speed-up from each stage of development.
Parallelize
Having identified the first candidate hotspot(s) we need to parallelize the code. As Mark discussed in his recent post Six Ways to SAXPY, there are three main ways to accelerate applications with GPUs: GPU-accelerated libraries, OpenACC directives, and GPU programming languages. For many operations this is as simple as using optimized libraries such as cuBLAS, cuFFT or cuSPARSE (read more about libraries), for others we may be able to add a few directives and minimal changes to expose parallelism to a parallelizing compiler (see these posts about OpenACC). In some cases we will want to use a GPU programming language, and while this will require some level of refactoring, languages such as CUDA C/C++ and CUDA Fortran aim to make this as easy as possible by integrating with your existing code.
Optimize
Of course, the purpose of parallelizing parts of an application is to improve performance, so we need to make sure to measure the application performance, with realistic data sets as always, and follow best practices to maximise the performance. This may include high-level optimizations such as algorithm choice and data movement (overlapping movement with computation, for example) and low-level optimizations such as explicitly caching data in shared memory or tuning floating point sequences. See the CUDA C Programming Guide and CUDA C Best Practices Guide for more details on optimizing CUDA code. This GTC On Demand presentation by Paulius Micikevicius is an excellent resource for understanding GPU program optimization. I mentioned Nsight (Visual Studio and Eclipse editions) before in the context of profiling non-accelerated applications using NVTX. Nsight is, of course, also a great tool for profiling your GPU-accelerated application, helping you to collect and analyse information about your kernels and your data management.
Deploy
Taking the initial development all the way through to deployment is an important part of the flow. It’s good to get any benefit, even a small benefit on the way to larger rewards, as early as possible. More importantly, taking the first improvements all the way through to production allows us to reduce risk by ironing out any integration or IT issues. Subsequent changes are then evolutionary, and not revolutionary, and hence are lower-risk. Here are some key points to look out for when productizing your GPU-accelerated code.
- Make sure you check the return value from API calls—all CUDA runtime and CUDA library API calls return an error code which is cudaSuccess if no error has occurred.
- Consider how you will distribute the CUDA runtime and libraries—the libraries are redistributable with your application to ensure that users with a different versions (or none at all) can still run the application.
- For clusters, various tools are available to monitor GPUs, from NVIDIA (e.g. nvidia-smi) and from third parties including OEMs.
This post has given you a taste of the APOD process. APOD is s a very simple idea that helps us to focus on what’s important, set expectations, build knowledge and experience, and minimise risk while also getting results as quickly as possible. For more information check out the CUDA C Best Practices Guide, available for download with the CUDA Toolkit or separately.