NVIDIA A30 GPU is built on the latest NVIDIA Ampere Architecture to accelerate diverse workloads like AI inference at scale, enterprise training, and HPC applications for mainstream servers in data centers. The A30 PCIe card combines the third-generation Tensor Cores with large HBM2 memory (24 GB) and fast GPU memory bandwidth (933 GB/s) in a low-power envelope (maximum 165 W).
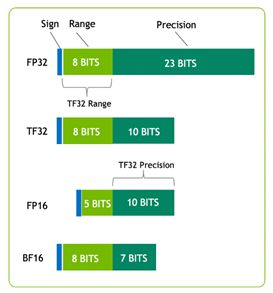
A30 supports a broad range of math precisions:
- double-precision (FP64)
- single-precision (FP32)
- half-precision (FP16)
- Brain Float 16 (BF16)
- Integer (INT8)
It also supports innovations such as Tensor Float 32 (TF32) and Tensor Core FP64, providing a single accelerator to speed up every workload.
Figure 1 shows TF32, which has the range of FP32 and precision of FP16. TF32 is the default option in PyTorch, TensorFlow, and MXNet, so no code change is needed to achieve speedup over the last-generation NVIDIA Volta Architecture.
Another important feature of A30 is Multi-Instance GPU (MIG) capability. MIG can maximize the GPU utilization across big to small workloads and ensure quality of service (QoS). A single A30 can be partitioned to up to four MIG instances to run four applications simultaneously, each fully isolated with its own streaming multiprocessors (SMs), memory, L2 cache, DRAM bandwidth, and decoder. For more information, see Supported MIG Profiles.
For interconnection, A30 supports both PCIe Gen4 (64 GB/s) and the high-speed third-generation NVLink (maximum 200 GB/s). Each A30 can support one NVLink bridge connection with a single adjacent A30 card. Wherever an adjacent pair of A30 cards exists in the server, the pair should be connected by the NVLink bridge that spans two PCIe slots for best bridging performance and balanced bridge topology.
| | NVIDIA T4 | NVIDIA A30 |
| Design | Small Footprint Data Center & Edge Inference | AI Inference & Mainstream Compute |
| Form Factor | x16 PCIe Gen3 1 slot LP | x16 PCIe Gen4 2 Slot FHFL 1 NVLink bridge |
| Memory | 16GB GDDR6 | 24GB HBM2 |
| Memory Bandwidth | 320 GB/s | 933 GB/s |
| Multi-Instance GPU | Up to 4 | |
| Media Acceleration | 1 Video Encoder 2 Video Decoder | 1 JPEG Decoder 4 Video Decoder |
| Fast FP64 | No | Yes |
| Ray Tracing | Yes | No |
| Power | 70W | 165W |
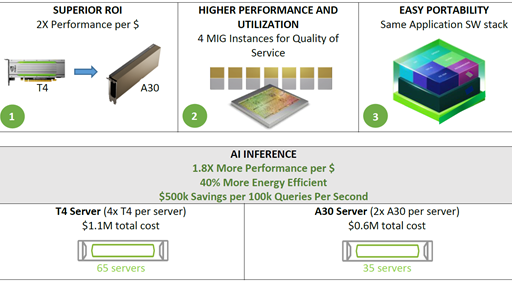
In addition to the hardware benefits summarized in Table 1, A30 can achieve higher performance per dollar compared to the T4 GPU. A30 also supports end-to-end software stack solutions:
- Libraries
- GPU-accelerated deep learning frameworks like PyTorch, TensorFlow, and MXNet
- Optimized deep learning models
- Over 2,000 HPC and AI applications, which can be obtained from NGC containers
Performance analysis
To analyze the performance improvement of A30 over T4, and CPUs, we benchmarked six models from MLPerf Inference v1.1 with the datasets:
- ResNet-50 v1.5 (ImageNet)
- SSD-Large ResNet-34 (COCO)
- 3D-Unet (BraTS 2019)
- DLRM (1TB Click Logs, offline scenario)
- BERT (SQuAD v1.1, seq-len: 384)
- RNN-T (LibriSpeech)
The MLPerf benchmark suite covers a broad range of inference use cases, from image classification and object detection to recommenders, and natural language processing (NLP).
Figure 2 shows the results of the performance comparison of A30 with T4 and CPU on AI inference workloads.A30 is around 300x faster than a CPU for BERT inference.
Compared to T4, A30 delivers around 3-4x performance speedup for inference using the six models. The performance speedup is due to A30 larger memory size. This enables larger batch size for the models and faster GPU memory bandwidth (almost 3x T4), which can send the data to compute cores in a much shorter time.
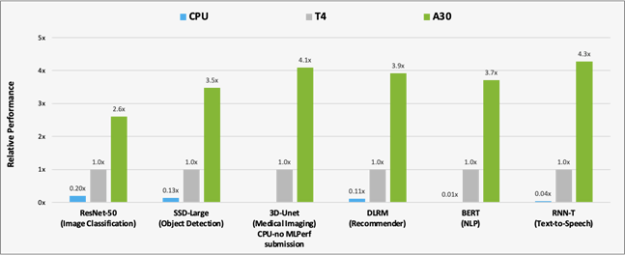
CPU: 8380H (no submission on 3D-Unet)
In addition to AI inference, A30 can rapidly pre-train AI models such as BERT Large with TF32, as well as accelerate HPC applications using FP64 Tensor Cores. A30 Tensor Cores with TF32 provide up to 10x higher performance over the T4 without requiring any changes in your code. They also provide an additional 2x boost with automatic mixed precision, delivering a combined 20x throughput increase.
Hardware decoders
While building a video analytics or video processing pipeline, there are several operations that must be considered:
- Compute requirements for your model or preprocessing steps. This comes down to the Tensor Cores, GPU DRAM, and other hardware components that accelerate the models or frame preprocessing kernels.
- Video stream encoding before transmission. This is done to minimize the bandwidth required on the network. To accelerate this workload, make use of NVIDIA hardware decoders.
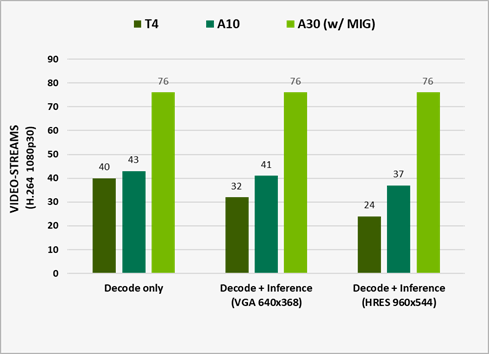
Measured performance with DeepStream 5.1. It represents e2e performance with video capture and decode, preprocessing, batching, inference, and post-processing. Output rendering was turned off for optimal perf running ResNet10, ResNet18, and ResNet50 networks for inference on H.264 1080p30 video-streams.
A30 is designed to accelerate intelligent video analysis (IVA) by providing four video decoders, one JPEG decoder, and one optical flow decoder.
To make use of these decoders along with the compute resources for analyzing videos, use the NVIDIA DeepStream SDK, which delivers a complete streaming analytics toolkit for AI-based, multisensor processing, video, audio, and image understanding. For more information, see TAO Toolkit Integration with DeepStream or Building a Real-time Redaction App Using NVIDIA DeepStream, Part 1: Training.
What’s next?
Representing the most powerful end-to-end AI and HPC platform for data centers, A30 enables researchers, engineers, and data scientists to deliver real-world results and deploy solutions into production at scale. For more information, see the NVIDIA A30 Tensor Core GPU datasheet and NVIDIA A30 GPU Accelerator product brief.
For more information about using the MIG feature of A30 to get the optimal GPU utilization, see Dividing NVIDIA A30 GPU and Conquering Multiple Workloads.
