The NVIDIA A100 brought the biggest single-generation performance gains ever in our company’s history. These speedups are a product of architectural innovations that include Multi-Instance GPU (MIG), support for accelerated structural sparsity, and a new precision called TF32, which is the focus of this post. TF32 is a great precision to use for deep learning training, as it combines the range of FP32 with the precision of FP16 to deliver up to 5x speedups compared to FP32 precision in the previous generation. In this post, I briefly step through the inner workings of TF32 and discuss performance data that shows its impact across an array of usages and networks.
TF32 at a glance
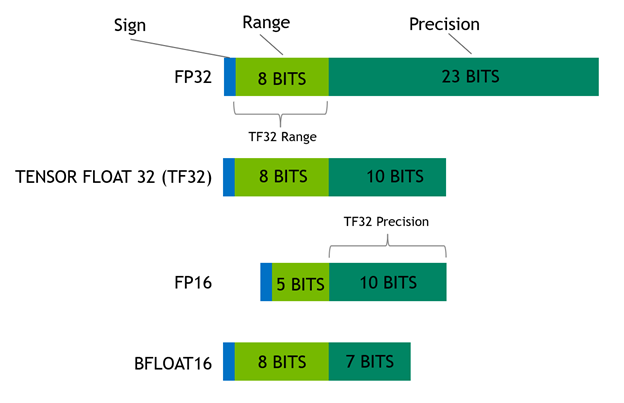
Floating-point data represents decimal numbers such as 3.14 in hardware using a sign bit (positive or negative number), exponent (number to the left of the decimal point), and mantissa (number to the right of the decimal point). The exponent expresses the range of the number, while the mantissa expresses its precision. TF32 strikes a balance, because it has the same range as FP32 and enough bits to deliver AI training’s required precision without using so many bits that it slows processing and bloats memory.
For maximum performance, the A100 also has enhanced 16-bit math capabilities, supporting both FP16 and Bfloat16 (BF16) at double the rate of TF32. Employing automatic mixed precision (AMP), you can double performance with just a few lines of code. For more information about TF32 mechanics, see TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x.
Accelerated training across use cases
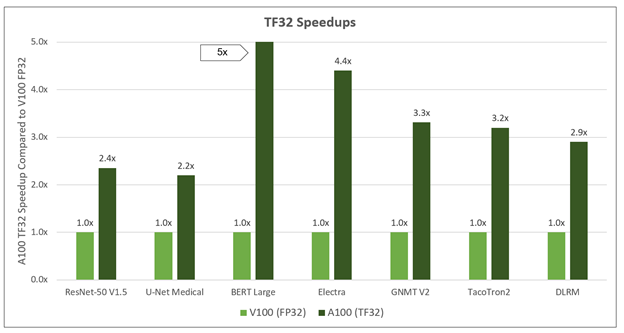
Compare training performance between A100 TF32 precision and the previous generation V100 FP32. What you see is time-to-solution (TTS) speedups ranging from 2x to over 5x. These speedups come with zero code changes and induce virtually no accuracy loss, so that networks converge more quickly. These gains enable applications to be trained faster and more often. Some modern AI applications are retraining networks multiple times per day. If you’re in the early stages of architecting your neural network, faster training times means completing the model construction faster, speeding time to a deployed application.
Here’s a look at the TTS speedups that TF32 can deliver across different networks, running in an 8-GPU server configuration. The chart shows time to solution, which is the critical metric when evaluating training performance. A network’s training run is complete when a stopping criterion is reached, such as the percentage of incremental accuracy improvement, or after finishing a set number of iterations, also known as epochs. If a network doesn’t converge, the training run never completes, which is why looking only at throughput gives an incomplete performance picture.
| ResNet-50 v1.5 | U-Net Medical | BERT | TacoTron2 | GNMT V2 | Electra | DLRM | |
| A100 | 4.1 hours | 3 minutes | 5 Days | 2.1 hours | 33 minutes | 2.3 days | 8 minutes |
| V100 | 9.7 hours | 7 minutes | 24 Days | 6.5 hours | 92 minutes | 10.1 days | 22 minutes |
| Speedup | 2.4x | 2.2x | 5x | 3.2x | 2.8x | 4.4x | 2.9x |
System configuration details: A100: Tested on a DGX A100 with eight NVIDIA A100 40GB GPUs. All networks trained using TF32 precision. V100: Tested on a DGX-2 with eight NVIDIA V100 32GB GPUs. All networks trained using FP32 precision. Results gathered using TensorFlow framework: DLRM, BERT, ResNet-50 v1.5, U-Net Medical, Electra. Results gathered using PyTorch framework: GNMT V2, Tacotron 2. Data gathered running NGC containers 20.08 and 20.09, CuDNN 8.0.4.12, CUDA 11.0.221, and driver version 450.51.06.
Using TF32 precision, the A100 delivers significant speedups for computer vision, speech, and language, as well as recommender system networks. The biggest speedup seen was on BERT natural language processing (NLP) networks, where TF32 brought a 5x TTS speedup.
You might notice that NVIDIA included a network called ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately), which is a novel pretraining method for language representations. Electra outperforms existing techniques, given the same compute budget on a wide array of NLP tasks. For computer vision networks, the TTS speedup was ~2.5x. For DLRM, a recommender system network created by Facebook, there was a ~3x TTS speedup.
In addition to the networks shown in the chart, we evaluated data across 23 different networks from the Deep Learning Examples on GitHub. All told, we saw an average TTS speedup of 2.6x across these networks. All without any code changes. For more information about performance data, see NVIDIA Data Center Deep Learning Product Performance.
Putting TF32 to work
NVIDIA makes it easy for you to take advantage of TF32. It’s the default precision in the cuDNN library, which accelerates key math operations for neural networks. Both the TensorFlow and PyTorch deep learning frameworks now natively support TF32 and are available on NGC. TF32 is also supported in CuBLAS (basic linear algebra) and CuTensor (tensor primitives).
For HPC applications, CuSolver, a GPU-accelerated linear solver, can take advantage of TF32. Linear solvers use algorithms with repetitive matrix-math calculations and are found in a wide range of fields such as earth science, fluid dynamics, healthcare, material science, nuclear energy, and oil and gas exploration.
Get started with TF32 today
A100 arrives in the market a decade after the first GPU instance went live in the cloud. With its TF32 precision, as well as other features like MIG and accelerated structural sparsity, it propels GPU-accelerated computing into the next decade of cloud GPU computing on every major CSP.
However, great hardware isn’t enough. Deep learning and HPC require a full-stack platform approach. In addition to the Deep Learning Examples, NVIDIA NGC includes containerized resources for frameworks and applications, as well as pretrained models, Helm charts, and scripts.
