GPU Integration Propels Data Center Efficiency and Cost Savings for Taboola
When you see a context-relevant advertisement on a web page, it's most likely content served by a Taboola data pipeline. As the leading content recommendation...
Dividing NVIDIA A30 GPUs and Conquering Multiple Workloads
Multi-Instance GPU (MIG) is an important feature of NVIDIA H100, A100, and A30 Tensor Core GPUs, as it can partition a GPU into multiple instances. Each...
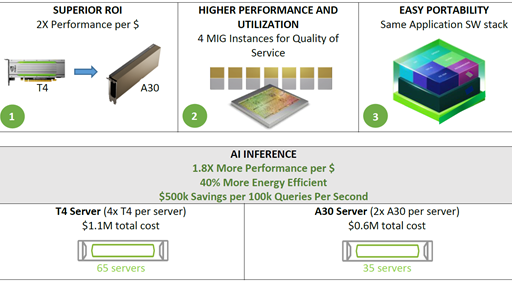
Accelerating AI Inference Workloads with NVIDIA A30 GPU
NVIDIA A30 GPU is built on the latest NVIDIA Ampere Architecture to accelerate diverse workloads like AI inference at scale, enterprise training, and HPC...
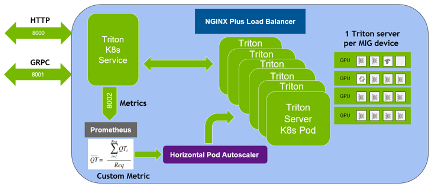
Deploying NVIDIA Triton at Scale with MIG and Kubernetes
NVIDIA Triton Inference Server is an open-source AI model serving software that simplifies the deployment of trained AI models at scale in production. Clients...
Real-Time Natural Language Processing with BERT Using NVIDIA TensorRT (Updated)
This post was originally published in August 2019 and has been updated for NVIDIA TensorRT 8.0. Large-scale language models (LSLMs) such as BERT, GPT-2, and...