
Multi-Instance GPU (MIG) is an important feature of NVIDIA H100, A100, and A30 Tensor Core GPUs, as it can partition a GPU into multiple instances. Each instance has its own compute cores, high-bandwidth memory, L2 cache, DRAM bandwidth, and media engines such as decoders.
This enables multiple workloads or multiple users to run workloads simultaneously on one GPU to maximize the GPU utilization, with guaranteed quality of service (QoS). A single A30 can be partitioned into up to four MIG instances to run four applications in parallel.
This post walks you through how to use MIG on A30 from partitioning MIG instances to running deep learning applications on MIG instances at the same time.
A30 MIG profiles
By default, MIG mode is disabled on the A30. You must enable MIG mode and then partition the A30 before any CUDA workloads can be run on the partitioned GPU. To partition the A30, create GPU instances and then create corresponding compute instances.
A GPU instance is a combination of GPU slices and GPU engines (DMAs, NVDECs, and so on). A GPU slice is the smallest fraction of the GPU that combines a single GPU memory slice and a single streaming multiprocessor (SM) slice.
Within a GPU instance, the GPU memory slices and other GPU engines are shared, but the SM slices could be further subdivided into compute instances. A GPU instance provides memory QoS.
You can configure an A30 with 24 GB of memory to have:
- One GPU instance, with 24 GB of memory
- Two GPU instances, each with 12 GB of memory
- Three GPU instances, one with 12 GB of memory and two with 6 GB
- Four GPU instances, each with 6 GB of memory
A GPU instance could be further divided into one or more compute instances depending on the size of the GPU instance. A compute instance contains a subset of the parent GPU instance’s SM slices. The compute instances within a GPU instance share memory and other media engines. However, each compute instance has dedicated SM slices.
For example, you could divide an A30 into four GPU instances, each having one compute instance, or divide an A30 into two GPU instances, each having two compute instances. Although both partitions result in four compute instances that can run four applications at the same time, the difference is that memory and other engines are isolated at the GPU instance level, not at the compute instance level. Therefore, if you have more than one user to share an A30, it is better to create different GPU instances for different users to guarantee QoS.
Table 1 provides an overview of the supported MIG profiles on A30, including the five possible MIG configurations that show the number of GPU instances and the number of GPU slices in each GPU instance. It also shows how hardware decoders are partitioned among the GPU instances.
| Config | GPC Slice #0 |
GPC Slice #1 |
GPC Slice #2 |
GPC Slice #3 |
OFA | NVDEC | NVJPG | P2P | GPU Direct RDMA |
| 1 |
4 | 1 | 4 |
1 | No | Supported MemBW proportional to the size of the instance | |||
| 2 | 2 | 2 | 0 | 2+2 | 0 | No | |||
| 3 | 2 | 1 | 1 | 0 | 2+1+1 | 0 | No | ||
| 4 | 1 | 1 | 2 | 0 | 1+1+2 | 0 | No | ||
| 5 | 1 | 1 | 1 | 1 | 0 | 1+1+1+1 | 0 | No | |
GPC (graphics processing cluster) or slice represents a grouping of the SMs, caches, and memory. The GPC maps directly to the GPU instance. OFA (Optical Flow Accelerator) is an engine on the GA100 architecture on which A100 and A30 are based. Peer-to-peer (P2P) is disabled.
Table 2 provides profile names of the supported MIG instances on A30, and how the memory, SMs, and L2 cache are partitioned among the MIG profiles. The profile names for MIG can be interpreted as its GPU instance’s SM slice count and its total memory size in GB. For example:
- MIG 2g.12gb means that this MIG instance has two SM slices and 12 GB of memory
- MIG 4g.24gb means that this MIG instance has four SM slices and 24 GB of memory
By looking at the SM slice count of 2 or 4 in 2g.12gb or 4g.24gb, respectively, you know that you can divide that GPU instance into two or four compute instances. For more information, see Partitioning in the MIG User Guide.
| Profile | Fraction of memory | Fraction of SMs | Hardware units | L2 cache size | Number of instances available |
| MIG 1g.6gb | 1/4 | 1/4 | 0 NVDECs /0 JPEG /0 OFA | 1/4 | 4 |
| MIG 1g.6gb+me | 1/4 | 1/4 | 1 NVDEC /1 JPEG /1 OFA | 1/4 | 1 (A single 1g profile can include media extensions) |
| MIG 2g.12gb | 2/4 | 2/4 | 2 NVDECs /0 JPEG /0 OFA | 2/4 | 2 |
| MIG 4g.24gb | Full | 4/4 | 4 NVDECs /1 JPEG /1 OFA | Full | 1 |
MIG 1g.6gb+me: me means media extensions to get access to the video and JPEG decoders when creating the 1g.6gb profile.
MIG instances can be created and destroyed dynamically. Creating and destroying does not impact other instances, so it gives you the flexibility to destroy an instance that is not being used and create a different configuration.
Manage MIG instances
Automate the creation of GPU instances and compute instances with the MIG Partition Editor (mig-parted) tool or by following the nvidia-smi mig commands in Getting Started with MIG.
The mig-parted tool is highly recommended, as it enables you to easily change and apply the configuration of the MIG partitions each time without issuing a sequence of nvidia-smi mig commands. Before using the tool, you must install the mig-parted tool following the instructions or grab the prebuilt binaries from the tagged releases.
Here’s how to use the tool to partition the A30 into four MIG instances of the 1g.6gb profile. First, create a sample configuration file that can then be used with the tool. This sample file includes not only the partitions discussed earlier but also a customized configuration, custom-config, that partitions GPU 0 to four 1g.6gb instances and GPU 1 to two 2g.12gb instances.
$ cat << EOF > a30-example-configs.yaml
version: v1
mig-configs:
all-disabled:
- devices: all
mig-enabled: false
all-enabled:
- devices: all
mig-enabled: true
mig-devices: {}
all-1g.6gb:
- devices: all
mig-enabled: true
mig-devices:
"1g.6gb": 4
all-2g.12gb:
- devices: all
mig-enabled: true
mig-devices:
"2g.12gb": 2
all-balanced:
- devices: all
mig-enabled: true
mig-devices:
"1g.6gb": 2
"2g.12gb": 1
custom-config:
- devices: [0]
mig-enabled: true
mig-devices:
"1g.6gb": 4
- devices: [1]
mig-enabled: true
mig-devices:
"2g.12gb": 2
EOF
Next, apply the all-1g.6gb configuration to partition the A30 into four MIG instances. If MIG mode is not already enabled, then mig-parted enables MIG mode and then creates the partitions:
$ sudo ./nvidia-mig-parted apply -f a30-example-configs.yaml -c all-1g.6gb MIG configuration applied successfully $ sudo nvidia-smi mig -lgi +-------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | |=======================================================| | 0 MIG 1g.6gb 14 3 0:1 | +-------------------------------------------------------+ | 0 MIG 1g.6gb 14 4 1:1 | +-------------------------------------------------------+ | 0 MIG 1g.6gb 14 5 2:1 | +-------------------------------------------------------+ | 0 MIG 1g.6gb 14 6 3:1 | +-------------------------------------------------------+
You can easily pick other configurations or create your own customized configurations by specifying the MIG geometry and then using mig-parted to configure the GPU appropriately.
After creating the MIG instances, now you are ready to run some workloads!
Deep learning use case
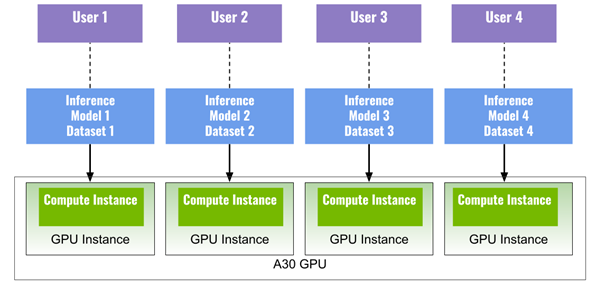
You can run multiple deep learning applications simultaneously on MIG instances. Figure 1 shows four MIG instances (four GPU instances, each with one compute instance), each running a model for deep learning inference, to get the most out of a single A30 for four different tasks at the same time.
For example, you could have ResNet50 (image classification) on instance one, EfficientDet (object detection) on instance two, BERT (language model) on instance three, and FastPitch (speech synthesis) on instance four. This example can also represent four different users sharing the A30 at the same time with ensured QoS.
Performance analysis
To analyze the performance improvement of A30 with and without MIG enabled, we benchmarked the fine-tuning time and throughput of the BERT PyTorch model for SQuAD (question answering) in three different scenarios on A30 (with and without MIG), also on T4.
- A30 four MIG instances, each has a model, in total four models fine-tuning simultaneously
- A30 MIG mode disabled, four models fine-tuning in four containers simultaneously
- A30 MIG mode disabled, four models fine-tuning in serial
- T4 has four models fine-tuning in serial
| Fine-tune BERT base, PyTorch, SQuAD, BS=4 | 1 | 2 | 3 | 4 | Result | ||
| A30 MIG: four models on four MIG devices simultaneously | Time (sec) | 5231.96 | 5269.44 | 5261.70 | 5260.45 | 5255.89 (Avg) | |
| Sequences/sec | 33.88 | 33.64 | 33.69 | 33.70 | 134.91 (Total) | ||
| A30 No MIG: four models in four containers simultaneously | Time (sec) | 7305.49 | 7309.98 | 7310.11 | 7310.38 | 7308.99 (Avg) | |
| Sequences/sec | 24.26 | 24.25 | 24.25 | 24.25 | 97.01 (Total) | ||
| A30 No MIG: four models in serial | Time (sec) | 1689.23 | 1660.59 | 1691.32 | 1641.39 | 6682.53 (Total) | |
| Sequences/sec | 104.94 | 106.75 | 104.81 | 108.00 | 106.13 (Avg) | ||
| T4: four models in serial | Time (sec) | 4161.91 | 4175.64 | 4190.65 | 4182.57 | 16710.77 (total) | |
| Sequences/sec | 42.59 | 42.45 | 42.30 | 42.38 | 42.43 (Avg) | ||
To run this example, use the instructions in Quick Start Guide and Performance benchmark sections in the NVIDIA/DeepLearningExamples GitHub repo.
Based on the experimental results in Table 3, A30 with four MIG instances shows the highest throughput and shortest fine-tuning time for four models in total.
- Speedup of total fine-tuning time for A30 with MIG:
- 1.39x compared to A30 No MIG on four models simultaneously
- 1.27x compared to A30 No MIG on four models in serial
- 3.18x compared to T4
- Throughput of A30 MIG
- 1.39x compared to A30 No MIG on four models simultaneously
- 1.27x compared to A30 No MIG on four models in serial
- 3.18x compared to T4
Fine-tuning on A30 with four models simultaneously without MIG can also achieve high GPU utilization, but the difference is that there is no hardware isolation such as MIG provides. It incurs overhead from context switching and leads to lower performance compared to using MIG.
What’s next?
Built on the latest NVIDIA Ampere Architecture to accelerate diverse workloads such as AI inference at scale, A30 MIG mode enables you to get the most out of a single GPU and serve multiple users at the same time with quality of service.
For more information about A30 features, precisions, and performance benchmarking results, see Accelerating AI Inference Workloads with NVIDIA A30 GPU. For more information about autoscaling AI inference workloads with MIG and Kubernetes, see Deploying NVIDIA Triton at Scale with MIG and Kubernetes.
