大型语言模型 (LLM) 从处理复杂的编码任务到创作引人入胜的故事,再到翻译自然语言,已展示出非凡的功能。企业正在定制这些模型,以提高特定于应用程序的效率,从而为最终用户提供更高的准确性和更好的响应。
然而,为特定任务定制大语言模型 (LLM) 会导致模型对先前学习的任务“忘记”。这称为 **灾难性遗忘**。因此,随着企业在应用中采用 LLM,有必要针对原始任务和新学习的任务评估 LLM,不断优化模型以提供更好的体验。这意味着在自定义模型上运行评估需要重新运行基础和对齐评估,以检测任何潜在的回退。
为了简化 LLM 评估,NVIDIA NeMo 团队宣布 抢先体验计划 用于 NeMo Evaluator。NeMo Evaluator 是一种云原生微服务,可提供自动基准测试功能。它评估先进的 基础模型 和自定义模型,这些模型使用一系列多样化、精心策划的学术基准测试、客户提供的基准测试或 LLM 作为判断。
NeMo Evaluator 简化了生成式 AI 模型评估
NVIDIA NeMo 是一个端到端平台,用于开发定制生成式 AI。它包含用于训练、fine-tuning、检索增强生成、guardrailing、数据管护以及预训练模型的工具。NeMo 提供跨技术堆栈的产品,从框架到更高级别的 API、托管端点和微服务。
最近,NeMo Evaluator 微服务作为 NeMo 微服务套件的一部分推出,由一组 API 端点组成,为企业提供了使用 LLM 评估的简便途径。有关详细信息,请参阅 借助 NVIDIA NeMo 微服务简化自定义生成式 AI 开发。
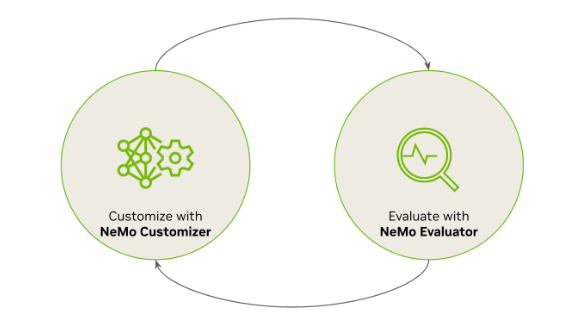
随着 NVIDIA NeMo 定制器微服务,企业可以轻松地对模型进行持续自定义和评估,以提高其性能 (图 1)。
抢先体验版中支持的评估方法
NeMo Evaluator 微服务支持对一组精选的学术基准测试和用户提供的评估数据集进行自动评估。它还支持使用 LLM-as-a-Judge 对模型响应执行整体评估,这与可能未定义真值的生成式任务相关。支持的各种评估方法在下文中有更全面的说明。
基于学术基准的自动评估
学术基准测试全面评估了 LLM 在不同语言理解和生成任务中的表现。它们是比较不同模型的宝贵工具,有助于根据特定需求选择最适合的 LLM.此外,基准测试还可以深入了解模型可能表现不佳的领域,指导在这些特定领域改进性能。
NeMo Evaluator 目前支持热门的学术基准测试,包括:
- 超越模拟游戏基准测试 (BIG-bench):协作基准测试旨在探索 large language models (LLMs) 的功能并推断其未来性能。它包含 200 多项任务,例如总结、重述、解决数独难题等。
- 多语言:基准测试由分类和生成任务组成,以了解各种语言的多语言功能。此基准测试针对各种任务测试 LLM,包括常识推理、多语言问答以及 101 种语言的多语言翻译。
- Toxicity:用于测量 LLM 的 toxicity 度的基准测试。Toxicity 被定义为不适合、不尊重或不合理的内容。此 toxicity 基准测试基于 RealToxicityPrompts 的 100000 个提示和 toxicity 分数。
自动评估自定义数据集
标准学术数据集和基准测试通常无法满足企业的独特需求,因为它们忽略了领域专业知识、文化细微差别、本地化和其他具体考虑因素等关键方面。因此,企业需要借助专家来构建自定义数据集并运行符合其需求的评估。
为支持对自定义数据集进行评估,NeMo Evaluator 微服务支持热门自然语言处理 (NLP) 指标,以测量真值标签与 LLM 生成的响应的相似性,例如:
- 准确率:正确预测的实例在数据集中实例总数中所占的比例。
- 双语评估下课 (BLEU) 是用于自动评估机器翻译文本的指标。BLEU 分数介于 0 到 1 之间,用于评估机器翻译与质量参考的相似性。分数为 0 表示不匹配 (低质量),分数为 1 表示完全匹配 (高质量)。
- 用于 Gisting 评估 (ROUGE) 的面向回忆的 Understudy 通过比较机器生成的摘要和人工生成的参考摘要之间的重叠,测量自动文本摘要以及文本合成的质量。
- F1 分数将精度和召回结合到单个分数中,在二者之间提供平衡。它通常用于评估分类模型的性能以及问答。
- 精确匹配:测量与真值或预期输出完全匹配的预测比例。
使用 LLM 作为评委进行自动评估
使用人工评估 LLM 响应是一个耗时且昂贵的过程。然而,使用 LLM 作为评委在可扩展性和效率方面表现出有希望。LLM 可以快速评估大量响应,同时保持可靠的判断标准,可能减少评估时间和成本。有关更多详细信息,请参阅 使用 MT-Bench 和聊天机器人竞技场对 LLM 进行评审。
NeMo Evaluator 微服务可以利用 NVIDIA NIM 支持的 LLM,例如 NVIDIA API 目录,使用 MT-Bench 数据集或自定义数据集评估。使用 NVIDIA NeMo 定制器可以轻松定制和对齐 LLM。
申请抢先体验
首先,请 申请 NeMo Evaluator 抢先体验。系统会审核申请,并向获得批准的申请人发送访问微服务容器的链接。
作为抢先体验计划的一部分,您还可以请求访问 NVIDIA NeMo 策展人和 NVIDIA NeMo 定制器微服务。这些微服务可帮助企业轻松构建企业级自定义生成式 AI,并更快地将解决方案推向市场。