
GPU 最初专用于在电子游戏中渲染 3D 图形,主要用于加速线性代数计算。如今,GPU 已成为 AI 革命的关键组成部分之一。
现在,我们依靠这些主力来完成深度学习工作负载,处理庞大而复杂的半结构化数据集。
然而,随着对基于 AI 的解决方案的需求大幅增加,获取高端 GPU 变得更加困难,更不用说为自己的用例设置和配置高端 GPU 所带来的投资了。
NVIDIA DGX 云
为满足 AI 训练需求,NVIDIA 提供先进的加速计算资源,供用户访问,而无需自行寻找、设置和配置基础设施。对于希望突破深度学习范式所能完成的工作的 AI 团队来说,NVIDIA DGX Cloud 提供了一场游戏变革。
除了访问云端的 AI 超级计算之外,您还必须构建代码并围绕代码进行计算,以提高 AI 应用程序的效率和性能。根据我们的经验,要做到这一点,最好的方法是使用 AI 编排:基础设施、代码、数据和模型之间的交集。
在本文中,我很高兴介绍 Union 的 NVIDIA DGX Agent,它使您能够将 Flyte 工作流与 NVIDIA DGX 云集成。这项合作旨在为希望管理 GPU 密集型工作负载的复杂性和成本的团队普及生产 AI 工作流。
借助 Union 的多云结构和核心开源编排器 Flyte,我将向您展示如何将 AI 工作流容器化、生产化和迭代的头痛转变为代码中的单行配置更改。
工作流程为何重要
Union 旨在简化和抽象化生产级 AI 编排的低级细节,以便 ML 工程师和数据科学家可以专注于从数据中创造价值。
例如,了解 Repl.it 如何针对其编码专业模型微调 LLM (图 1)。
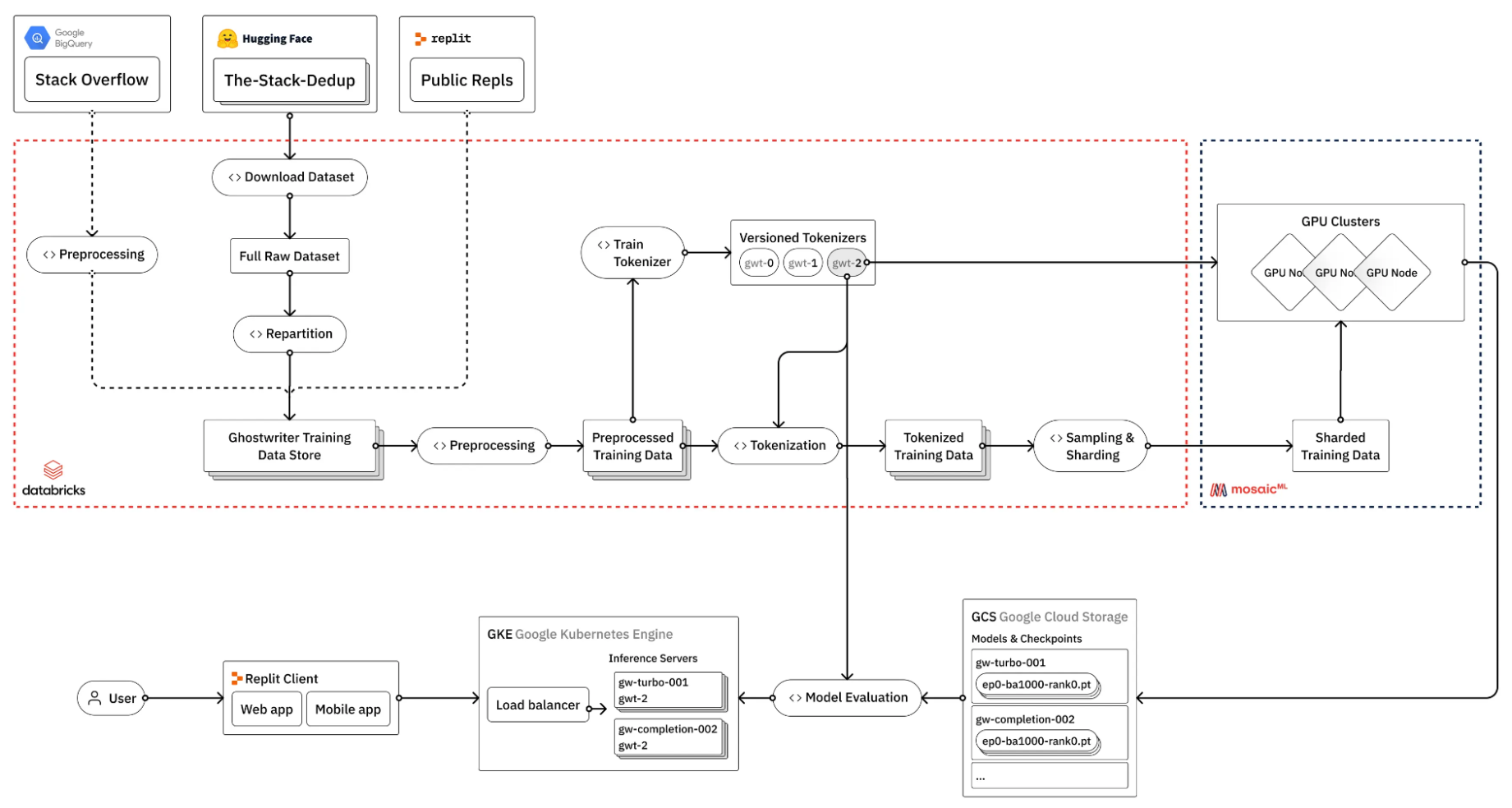
(来源:如何训练自己的大型语言模型)
图 1 显示微调 LLM 的过程涉及许多步骤,其中许多步骤不一定需要 GPU.那么,如何管理此类流程的复杂性呢?
在 AI 模型开发过程中,工作流程实际已成为管理数据复杂性和模型管理的抽象概念。
Flyte 是 Linux 基金会的开源项目,由 Union 联合创始人在 Lyft 发起,旨在使您的数据和机器学习流程具有可再现性和可扩展性。以下是实现这一点的一些核心功能:
- 任务:将任务视为数据或机器学习流程中的单个步骤,每个步骤都有自己的输入和输出。例如包括训练、数据转换、预测等。
- 工作流程:当您将这些步骤串联起来时,便形成一个工作流程。它就像一个食谱,其中每个任务在正确的时间点被添加。
- 声明性资源管理:与以前不同,技术水平有了提高。每个任务都有自己的资源需求,这意味着它可以明确告诉 Flyte 需要多少计算能力来完成特定工作。
- 智能体:代理作为中介,将 Flyte 连接到 DGX 云等外部服务,以简化对 Flyte 核心能力之外的服务的调用。
以下代码示例展示了这些元素如何在高层次上交互:
from collections import NamedTuple import pandas as pd import torch.nn as nn from flytekit import task, workflow, Resources from flytekit.extras.accelerators import T4 from flytekitplugins.spark import Databricks @task(task_config=Databricks(...)) def create_data() -> pd.DataFrame: ... @task(requests=Resources(gpu="4"), accelerator=T4) def train_model(data: pd.DataFrame) -> nn.Module: ...@workflowdef model_training_pipeline() -> nn.Module: train_data, test_data = get_data() model = train_model(data=train_data) return model |
此示例使用 Databricks 任务配置来执行 `create_data` 任务,它利用四个 NVIDIA T4 Tensor Core GPU,并使用 Flyte 的原生加速器声明语法来创建训练数据。
在 Flyte 中,Repl.it 微调流程如下所示:
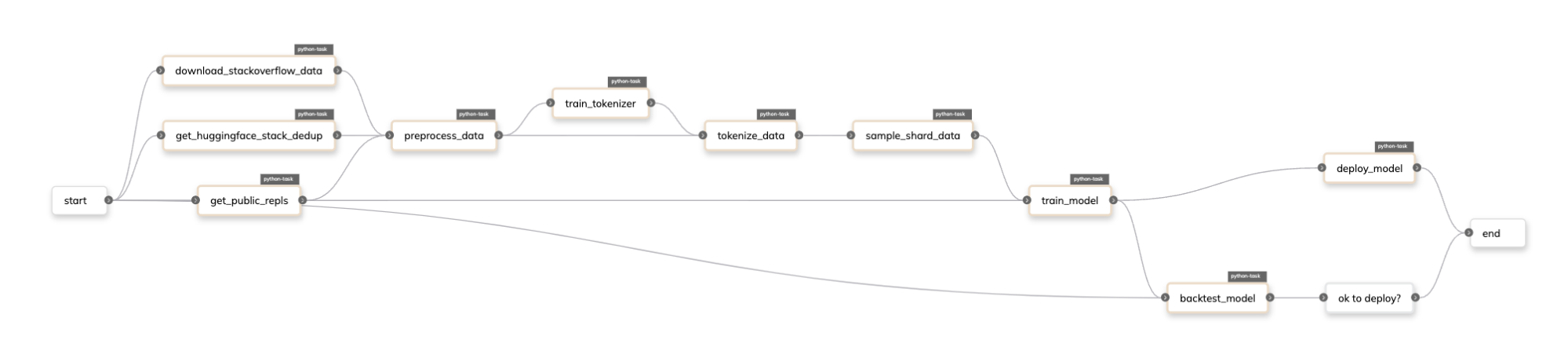
隆重推出 Union 的 NVIDIA DGX 智能体
假设您正在微调 Mixtral 8x7b 模型。尽管 Flyte 可以为您的工作负载配置 GPU,但您仍然可能会受到传统云提供商 (例如 Amazon Web Service、Google Cloud Platform 和 Microsoft Azure) 无法提供某些类型 GPU 的限制。
要利用 DGX 云绕过此限制,您必须执行以下操作:
- 在本地或基于云的 IDE 上开发模型训练工作流。
- 容器化您的代码和依赖项。
- 将镜像推送到 NVIDIA 容器注册表。
- 在云端出现问题时调试代码。
- 返回到步骤 2,冲洗,然后重复。
借助 Union,这项艰巨的任务将变得更加顺畅。我们为您提供工具,让您可以通过代码中的单行配置轻松利用 DGX 云的功能,将原本复杂的操作转变为简单的过程。
假设您有一个名为 Flyte 的任务,fine_tune 对 Mixtral 8x7B 模型进行微调:
from datasets import load_dataset from transformers import ( AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments, ) from trl import SFTTrainer @taskdef fine_tune(dataset_name: str, output_dir: str): # load model, tokenizer, and dataset model = AutoModelForCausalLM.from_pretrained( "mistralai/Mixtral-8x7B-v0.1", quantization_config=BitsAndBytesConfig(load_in_4bit=True), device_map="auto", torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained( "mistralai/Mixtral-8x7B-v0.1", use_fast=True) dataset = load_dataset(dataset_name, split="train") # configer training arguments and trainer training_args = TrainingArguments(...) trainer = SFTTrainer(...) # train and save the model trainer.train() trainer.save_model(output_dir) |
要使用 Flyte 和 Union 的 NVIDIA DGX 智能体,请在任务配置中添加 `DGXConfig` 任务和所需的依赖项,以及附带的文件:`dgx_image_spec` 代理插件。
from flytekitpligins.dgx import DGXConfig, dgx_image_spec fine_tuning_image_spec = dgx_image_spec.with_packages([ "accelerate", "datasets", "torch", "transformers", "trl",]) @task( task_config=DGXConfig(instance="dgxa100.80g.8.norm"), container_image=fine_tuning_image_spec, ) def fine_tune(dataset_name: str, output_dir: str): ... |
代码示例使用 `dgxa100.80g.8.norm` 实例,这是一个包含 8 个 NVIDIA A100 Tensor Core GPU 的单节点。您可以将其用于训练。对于多节点训练,代理插件还提供一个 `DGXTorchElastic` 配置类,可让您进一步扩展工作负载。
NVIDIA DGX 智能体提供实用程序,以将您的数据安全地迁移到云原生 Blob 存储 (Amazon S3、GCS、Azure Blob Storage) 到 DGX 云的 Blob 存储系统。结合 Flyte 的缓存功能,您可以管理数据出口成本,以进一步控制成本。有关更多信息,请参阅 联盟 AI 平台上的文档。
立即体验先进的加速计算!
如果您正在深入研究 AI 开发,却发现自己在与 GPU 短缺或设置问题作斗争,那么值得仔细了解一下 Union 的多云结构。它旨在简化您的收购流程,让您更专注于开发,而不是管理和维护硬件或云服务的物流。
准备好简化您的 AI 项目了吗?联系联盟团队,深入了解代码,看看您的生活会变得更加轻松。使用合适的工具,正面应对这些 AI 挑战。



