
本文聚焦 NVIDIA FP8 训练与推理的实践应用,该内容来源于 2023 云栖大会 NVIDIA 专场演讲。
FP8 训练利用 E5M2/E4M3 格式,具备与 FP16 相当的动态范围,适用于反向传播与前向传播。FP8 训练在相同加速平台上的峰值性能显著超越 FP16/BF16,并且模型参数越大,训练加速效果越好,且其与 16-bits 训练在收敛性和下游任务表现上无显著差异。FP8 训练通过 NVIDIA Transformer Engine 实现,仅需少量代码改动,并且支持 FlashAttention、混合精度训练迁移等。支持 FP8 的框架包括 NVIDIA Megatron-LM、NeMo、DeepSpeed、飞桨 PaddlePaddle、Colossal AI、HuggingFace 等。
FP8 推理通过 NVIDIA TensorRT-LLM 实现,权重输入先转换为 FP8,并融合操作以提高内存吞吐,但部分输出仍需 FP16 进行 reduction。NVIDIA 技术团队正研究直接 FP8 reduction 以实现端到端的加速优化。
FP8 基本原理、采用理由和收益
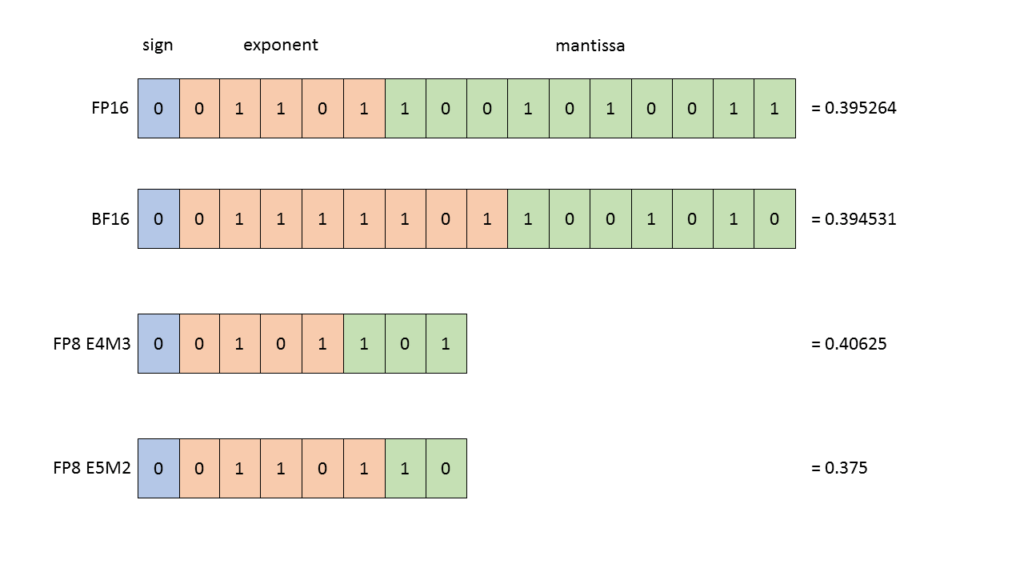
图 1. 四种数据类型
首先详解 FP8 的概念,图 1 展示了 FP8、FP16、FP32 与 BF16 四种数据类型。业界曾长期依赖 FP16 与 FP32 训练,直至 GPT 横空出世,BF16 因能避免计算过程中的数值溢出问题而受到青睐。
近年来,NVIDIA 技术团队在 FP8 领域持续投入,发布了多篇论文,并在历届 GTC 大会也分享了 FP8 在计算机视觉 (CV)、自然语言处理 (NLP) 以及大模型训练中的实际效果。
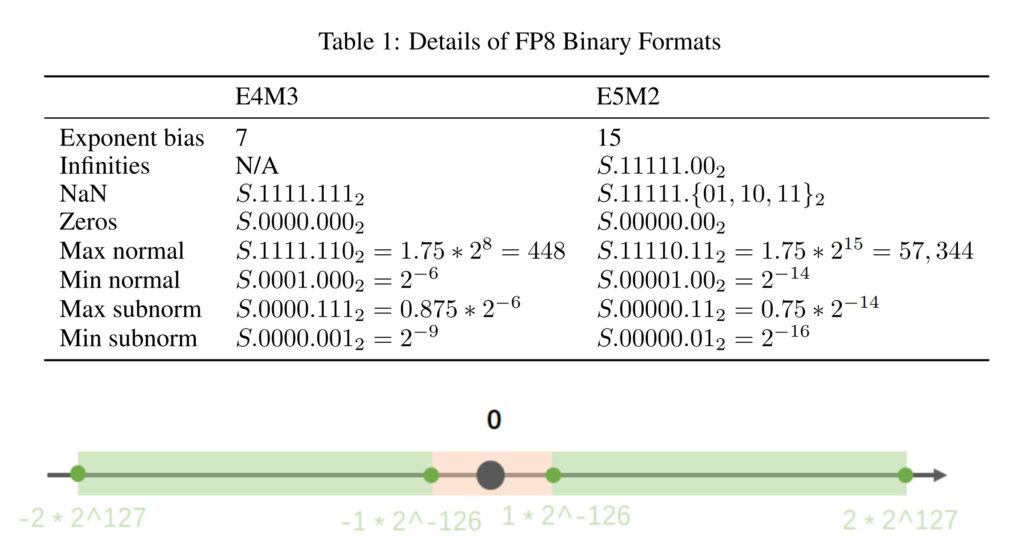
图 2. E4M3 与 E5M2 两种数据格式
图 2 表格展示了 E4M3 与 E5M2 两种数据格式。其中可以看到,FP8 精度的 E5M2 数据格式的数部分,与 FP16 的保持一致。这意味着 FP8 精度的 E5M2 数据格式具备与 FP16 相当的动态范围,因此该数据格式常被用在训练的反向传播阶段。而 E4M3 是在前向传播中采用的 FP8 格式。图 2 详尽展示了 FP8 格式下各类特殊数值的表示方式。
当我们考虑浮点数的数据精度会不会损失的时候,这个浮点数往往会落入图 2 下半部分里粉色的 subnormal 区间。图 2 下半部分是以 FP32 举例的,读者可根据图 2 表格看到 FP8 的 subnormal 区间,因此我们在训练模型时可进行理论分析,探究数值精度是否影响模型效果。
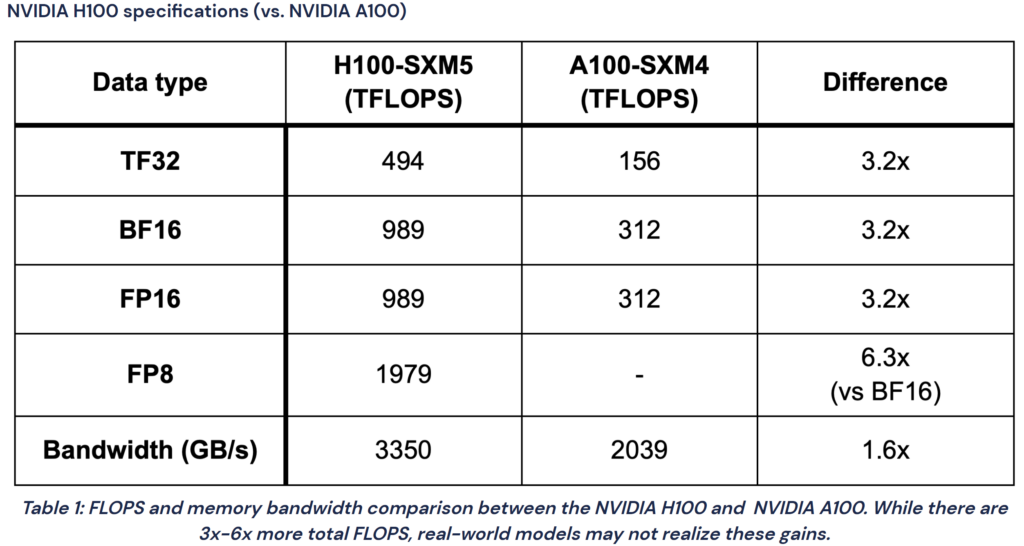
表 1. 援引的测试数据[1]仅供技术参考和讨论
表 1 旨在阐述采用 FP8 的原因,以在 NVIDIA H100 Tensor Core GPU 上为例,单位是 TFLOPS,相较 FP16 和 BF16,FP8 的峰值性能能够实现翻倍。并且此表展示的基准测试数据是在 2023 年采集的,当前性能提升更为显著。
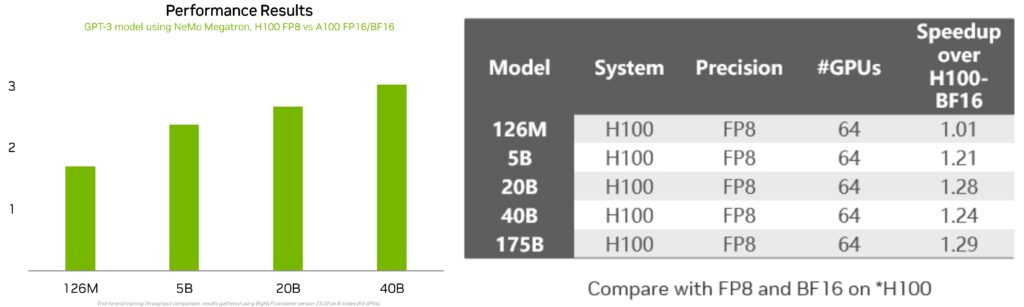
图 3. 测试数据仅供技术参考和讨论
图 3 左侧图表对比了不同参数规模的 GPT-3 模型在 H100 上做 FP8 训练,以及在 NVIDIA A100 Tensor Core GPU 上做 FP16/BF16 训练的吞吐加速比。这个加速效果随模型规模正向变化,比如参数规模为 5B 至 40B,它的加速效果约为 2 到 3 倍。
右侧表格则进一步对比了不同参数规模的模型同在 H100 GPU上,使用 FP8 训练相对 BF16 的性能加速比。就 126M 至 175B 参数的模型而言,除了个别特殊任务外,FP8 训练的加速效果同样随模型规模增大而提升。换言之,模型规模越大,采用 FP8 训练的的收益越大。
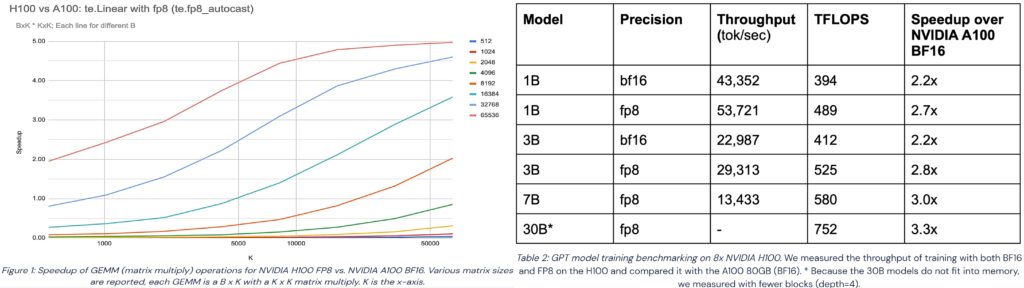
图 4. 援引的测试数据[2]仅供技术参考和讨论
图 4 援引的是行业测试数据。左侧图表显示的是对 GEMM 单一计算任务的加速对比。在 H100 GPU 上 FP8 训练相对于 A100 GPU 上 BF16 训练的峰值性能加速比约为 6 倍,而在 GEMM 任务测试中接近 5 倍。并且鉴于底层 CUDA 内核持续优化,未来性能将进一步提升。
右侧表格则展示了在不同规模的 GPT 模型做 FP8 训练的实际加速效果,模型参数规模分别为 1B、3B、7B 和 30B。该图表分别对比了在 H100 GPU 与 A100 GPU 上做 BF16 和 FP8 训练的加速效果。可以看到 BF16 训练对 1B,3B 模型的加速比约为 2.2 倍,而 FP8 训练的加速比分别达 2.7 倍、2.8 倍,对 7B,30B 模型加速比则达到 3 倍和 3.3 倍,说明 FP8 训练的性能优化效果更加显著。
FP8 的训练性能和收敛性
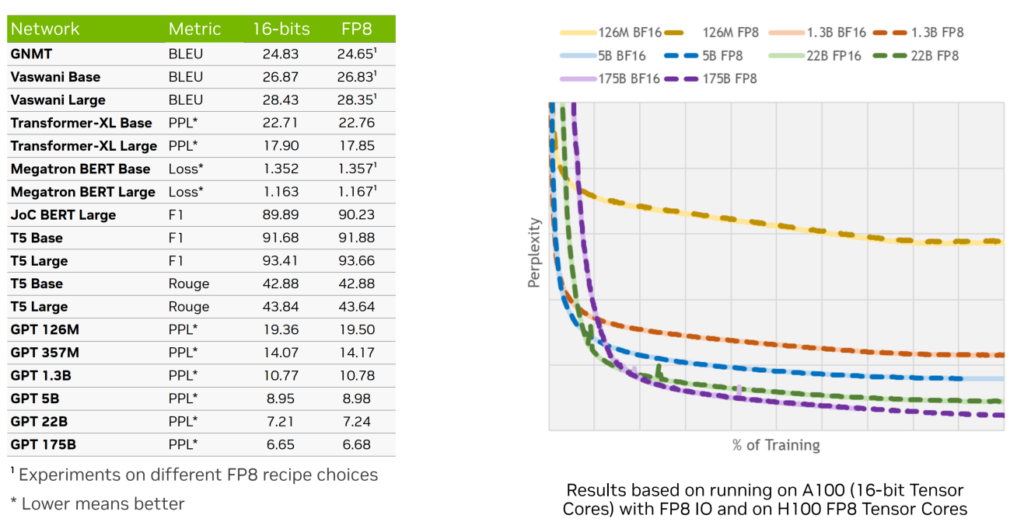
图 5. 测试数据仅供技术参考和讨论
图 5 展示了 FP8 训练的性能与收敛性。右图显示在不同规模的 GPT 模型上使用 BF16 与 FP8 进行训练的 loss (损失值)曲线,并以困惑度 PPL(Perplexity) 为度量指标。同色曲线代表相同模型规模,实线代表 BF16,虚线为 FP8。观察 PPL 曲线走势,可见随着训练进程,FP8 与 BF16 的曲线几乎完全吻合,表明两者收敛性并无显著差异。
左侧表格则汇总了历届 GTC 大会中分享的下游任务数据,包括 PPL 指标及 FP8 与 16-bits 训练的对比,涵盖 NLP 模型和 CV 模型。结果显示,使用 FP8 训练的模型与 16-bits 训练的模型在各项指标上的数值差异甚微,证实了 FP8 训练能达到同等效果。
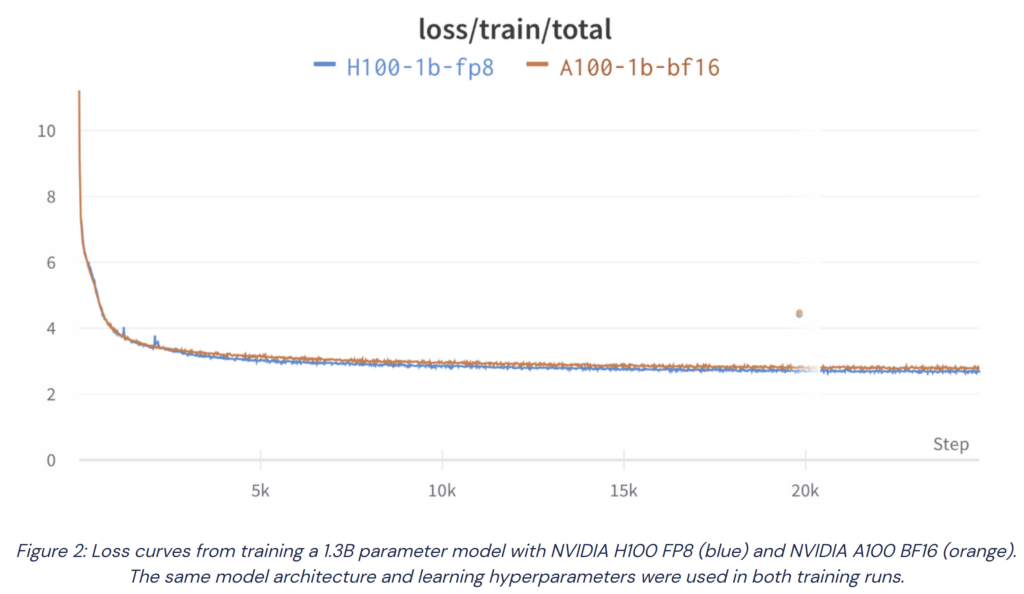
图 6. 援引的测试数据[3]仅供技术参考和讨论
图 6 展示了我们在本地测试的一个 1.3B 参数模型的实际训练结果,共进行了约 2.5 万步训练。结果显示,该模型的 loss 曲线与预期基本相符,仅有微小(零点零几)的差异。
这里列举在 FP8 训练中实际采用的配置。可以看到使用 FP8 训练时对代码的改动极少,只需添加几行代码即可,后文将详细解释这些代码的具体含义。
--fp8-hybrid \
--transformer-impl transformer_engine \
--fp8-amax-history-len 1024 \
--fp8-amax-compute-algo max此外,我们在实际训练中的常见问题解答如下:
- 目前广泛采用 BF16 进行混合训练,转用 FP8 是否需要自行编译 kernel 或进行复杂的数据类型转换?答案是否,建议使用 NVIDIA Transformer Engine 预置的多种 FP8 kernel(Linear、MLP、LayerNorm等基础算子及基于这些算子的fused kernel),无需开发,直接调用即可。
- 如果没使用 NVIDIA Megatron 或 DeepSpeed 框架,而是采用自定义框架,可以无缝使用 Transformer Engine 进行 FP8 训练吗?答案是可以。只需在 PyTorch 上使用 Transformer Engine 提供的 fp8_autocast 包装器 (wrapper),即可在原生 PyTorch 环境中开展 FP8 训练。此 wrapper 主要用于提供一系列 FP8-safe 的算子,自动将高精度的输入数据转换为 FP8,简化了低精度训练的实现过程。在上述过程中,需要对每个 tensor 更新其缩放因子 (scale),为此我们引入 amax(maximums of absolute value)的概念,fp8_autocast wrapper 会更新 amax 值。此外,根据 amax 值,该 wrapper 还会自动计算每个 tensor 的实际scale值。
- Transformer Engine 除提供 FP8 layer-wise 模块和自动数据类型转换外,还有什么功能?答案是它还支持 FlashAttention 机制。这意味着 Transformer Engine 也能够提升传统 BF16、FP16 训练的性能。
- 对于已使用 BF16 训练的存量模型,能够使用 FP8 做继续训练吗?答案是可以。实践证明,BF16 格式的 checkpoint 可以直接导入进行 FP8 继续训练;反之亦然,即在预训练阶段使用了 FP8,那么在 SFT(supervised Fine-Tuning) 阶段,出于对模型精度或数据健壮性的考虑,仍旧可以从 FP8 无缝切换到 BF16 做继续训练。Transformer Engine 全面支持此类精度迁移的操作。
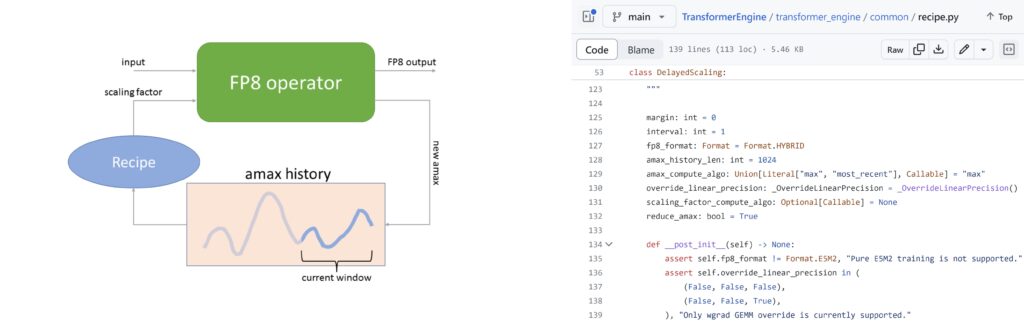
图 7. 解读 FP8 训练中新增的五行代码
图 7 旨在解读前文提及的 FP8 训练中新增的五行代码,代码的功能是用于计算当前 tensor 的 scale 值。我们采用名为 delayed scaling 策略,即当前 tensor 的 scale 值并非基于实时计算得出,而是依据其历史数据,例如基于前几个迭代周期的值计算得出。计算方法可选择取 max 值,也可采用最近时间的值。
以该图展示的 amax history 说明,针对当前 tensor,系统可存储 1,024 个 amax 值,并从中选取最大值作为当前 tensor 的 amax 值。随后,根据一个简化的 recipe 算法即可计算出 scale 值。
实际应用中,Hopper GPU 上 FP8 训练相较于 BF16 的加速效果为 30%-40%,低于 FP8 在单一 GEMM 计算任务中理论可达的 5 倍加速比。为解释此现象,本文借助图 8 进行阐述。
使用 Transformer Engine 训练 FP8 LLM
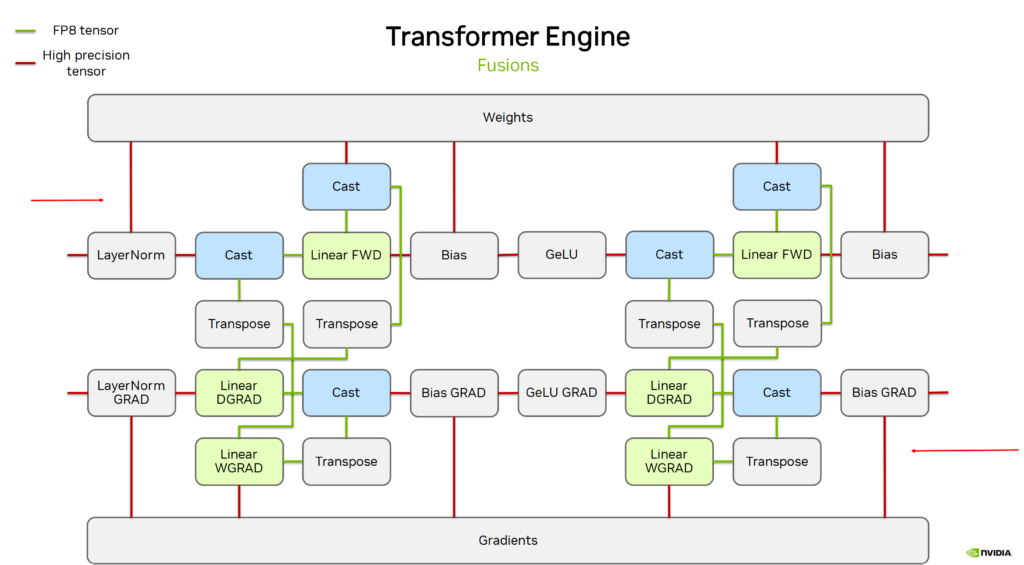
图 8. FP8 训练在 Transformer Engine 上的完整流程
图 8 显示了训练中前向与反向计算的精度差异:红线表示高精度(BF16、FP32),绿线为FP8。在整个训练期间,图片上半部分的权重(weight)及下半部分的梯度(gradient)始终以高精度存储。仅在执行 linear 操作时,才对当前 tensor 进行数据格式转换(cast),转为 FP8 精度计算,但 linear 输出仍为高精度。因此,后续 bias 计算等均在高精度上进行。
图示表明,实际训练中仅 GEMM 计算采用 FP8,其余计算保持高精度。尽管业界存在对非线性操作也采用 FP8 计算和存储的激进策略,并在部分下游任务中表现良好,但主流方案依然遵循上述精细化的精度分配原则。
目前支持 FP8 训练的分布式训练框架与工具包括 NVIDIA Megatron-LM、NeMo 框架,DeepSpeed、飞桨 PaddlePaddle、Colossal AI、HuggingFace 等,也就是说这些框架均已集成了 Transformer Engine,可选用上述任一框架进行大模型 FP8 训练。
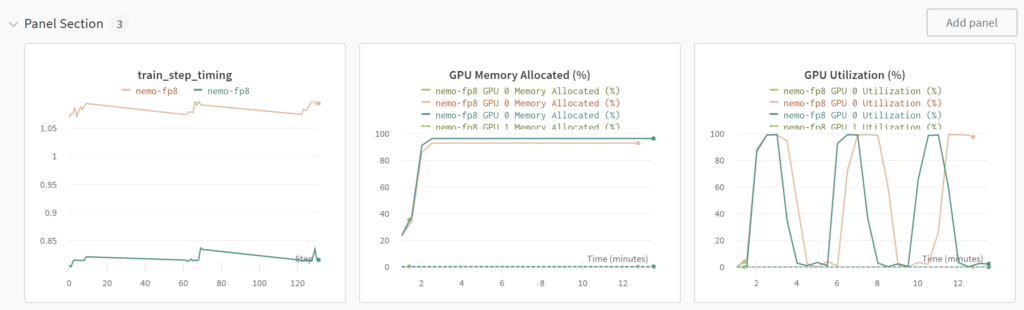
图 9. 不同数据精度集合 Transformer Engine 的训练测试结果对比
图 9 总结了上述重点,通过对比三类测试情况:绿线代表仅使用 BF16 训练,橘线表示 BF16 训练结合 Transformer Engine,即在启用 FlashAttention 的同时,使用 Transformer Engine 内置的 fused kernel),蓝线为 FP8 训练结合 Transformer Engine。
绿线显示,仅用 BF16 训练时,模型在单 GPU 卡上即遭遇内存不足(OOM),而在启用 Transformer Engine 后,依旧采用 BF16,模型也能顺利完成训练。若进一步转为 FP8,单次迭代时间可提升约 34.56%。
中间的图表展示了各类测试的显存占用情况。如前文所述,权重、梯度及优化器(optimizer)的数据均以高精度存储,此外,FP8 训练因需在 checkpoint 中保存额外值,训练时显存占用比 FP16 略高约 5% 以内。须注意,推理阶段的显存占用与训练阶段是完全不同的。
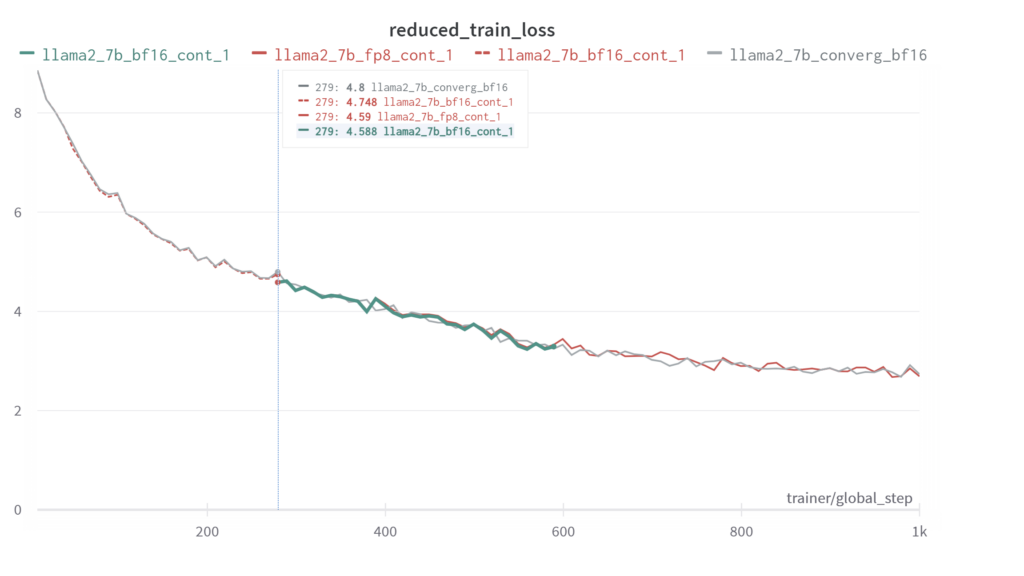
图 10. Llama2-7B 模型做 FP8/BF16 继续训练的 loss 曲线高度一致
图 10 展示了对 Llama2-7B 模型做 FP8 继续训练的效果。本测试并未进行长时间的训练,目的是在为了提供概念验证 (PoC, Proof of Concept)。图中共有四条曲线:灰色曲线代表全程使用 BF16 训练,其余三条线分别表示以 BF16 进行预训练,保存 checkpoint 后,再分别以 BF16 与 FP8 继续训练。从继续训练的两条曲线来看,loss 曲线高度一致,且与灰色曲线的趋势也保持一致。
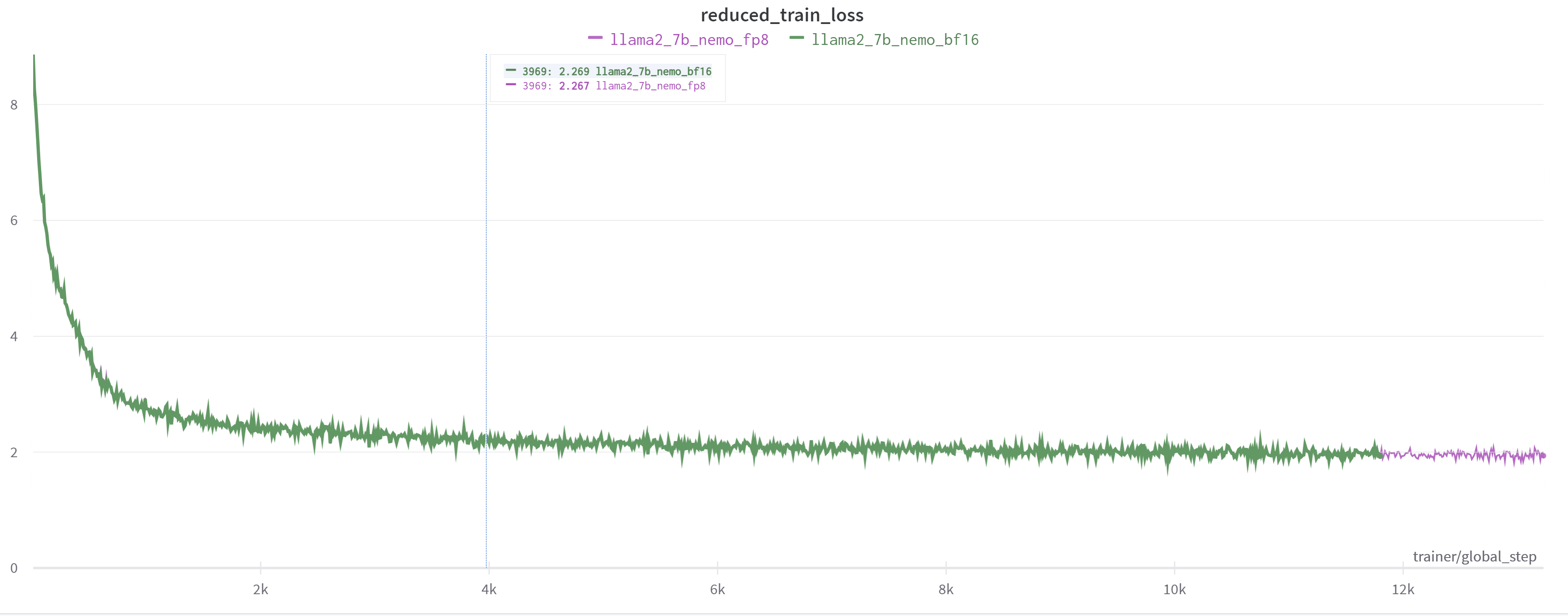
图 11. Llama2-7B 模型 1.3 万步内全程 FP8/BF16 训练的 loss 曲线基本一致
图 11 展示的是对 Llama2-7B 在1.3万迭代步内做全程 FP8 训练,可以看到它和全程 BF16 训练的 loss 曲线也几乎一致。
FP8 推理流程
本章节分享使用 TensorRT-LLM 进行 FP8 推理。前文图 8 展示的 FP8 训练在 Transformer Engine 上的完整流程,而在进入推理阶段,图 8 下半部分如梯度等训练特有部分可去除,仅保留上半部份即可。
训练时为确保梯度计算准确,权重通常维持为高精度(如 BF16 或 FP32),这是由于训练时需更新参数,而在推理时,权重已固定,故可在模型加载或预处理阶段提前将权重转换为 FP8,确保模型加载即为 FP8 格式。此外,推理阶段应尽量进行操作融合,如将 LayerNorm 与后续数据格式转换操作整合,确保 kernel 输入输出尽可能维持 FP8,从而能够有效提升 GPU 内存吞吐。同样,GeLU (Gaussian Error Linear Unit) 激活函数也要力求融合。
目前少量输出仍会保持为 FP16,原因是 NVIDIA NCCL 仅支持高精度规约操作 (reduction),所以现在仍然需采用 FP16 进行 reduction,完成后再转化为 FP8。
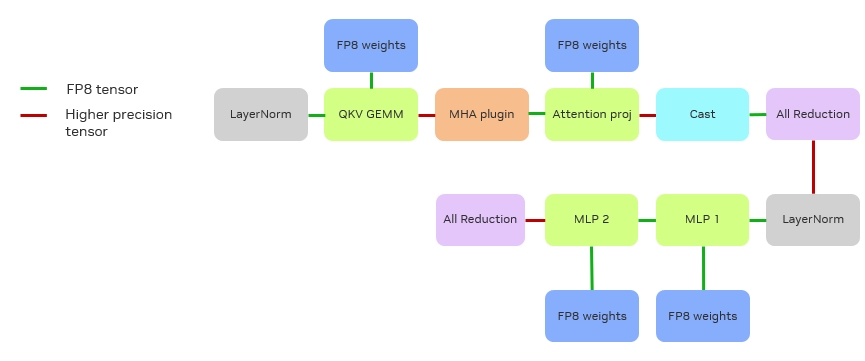
图 12. FP8 推理流程
经过上述融合后,推理流程就简化为图 12 所示。绿线代表 FP8 的输入输出(I/O),红线表示高精度 I/O。图中可见,最前端的 LayerNorm 输出与权重均为 FP8,矩阵输出暂时保持 FP16,与前文描述一致。并且经过测试验证可得,虽然矩阵输出精度对整体性能影响较小,但与输入问题的规模相关;且因其计算密集特性,对输出形态影响微弱。
在完成 MHA(Multi-Head Attention)后,需要将结果转换为 FP8 以进行后续矩阵计算,Reduction 是以 FP16 执行后再转换到 FP8 的。对于 MLP1 和 MLP2,两者逻辑相似,但不同之处在于:MLP1 的输出可保持在 FP8,因为它已经把 GeLU 加 Bias 等操作直接融合到 MLP1 的 kernel。
由此引发的关键问题是,能否将剩余红线(高精度 I/O)全部转为绿线(FP8 I/O),实现进一步的加速优化?这正是 NVIDIA 持续进行的方向。以 reduction 为例,NVIDIA 正研究直接实现 FP8 reduction,尽管中间累加仍需高精度,但在数据传输阶段可采用 FP8。与现有 reduction 不同的是,FP8 reduction 内部需引入反量化(de-quantization)与量化 (quantization)操作,故需定制开发 reduction kernel。
最佳实践:使用 TensorRT-LLM 实现 FP8 推理
TensorRT-LLM 是基于 NVIDIA TensorRT 构建,其 FP8 能力也主要是通过 TensorRT 提供。自 TensorRT 9.0 版本起,官方就已经开始支持 FP8 推理。要在 TensorRT 中启用 FP8 推理,需完成以下几步:
- 设置 FP8 标志:通过调用 config.set_flag (trt.BuilderFlag.FP8) 在 TensorRT 配置中启用 FP8 支持。类似 INT8、BF16、FP16,FP8 也是类似的启用方式。
- 添加 GEMM 缩放因子(scale):主要针对输入和权重,需在 weight.py (TensorRT-LLM 中的文件)中额外加载这些缩放因子。这是 FP8 推理中不可或缺的步骤。
- 编写 FP8模型:现阶段我们需要明确编写需要 FP8 支持的模型。具体做法如下:将原始 FP16 输入量化至 FP8,随后进行反量化;权重同样进行量化与反量化操作。如此编写的模型,TensorRT 会自动将量化与反量化操作尽可能与前一个 kernel 融合,以及将反量化操作与 matmul kernel 融合。最终生成的计算图表现为量化后的 X 与 W 直接进行 FP8 计算,输出也为 FP8 结果。
为了简化 FP8 在 TensorRT-LLM 中的应用,TensorRT-LLM 已对其进行封装,提供了 FP8 linear 函数和 FP8 row linear 函数来实现。对于使用直接线性层(linear layer),则无需重新编写代码,直接调用函数即可。
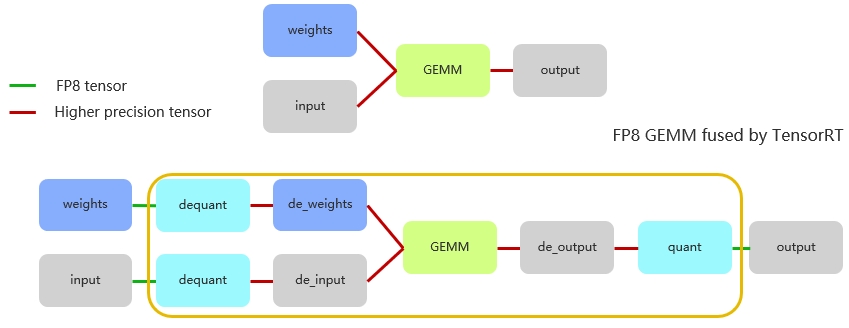
图 13. FP8 推理计算流程
本文用图 13 总结上述内容。首先权重以 FP8 精度存储的,在进行计算前,权重先经历一次反量化。注意,在此之前,权重的量化已在输入前完成了,此处仅需进行反量化操作。这意味着,在进行矩阵内部计算时,实际上是使用反量化后的数据,通常是 FP16 或甚至 FP32来进行运算的。
矩阵层尽管以 FP8 表示,但累加是采用 FP32 完成,累加后再乘以 scale 的相关参数,形成如图所示的计算流程。最终得到的结果具备较高精度。由于累加器(accumulator)需要采用高精度的数值,因此,要获得最终 FP8 的输出结果,模型还需经过一个量化节点 (quantitation node)。
回顾整个流程,输入经历了量化与反量化操作。其中,量化 kernel 发生在反量化 kernel 之前,而 TensorRT 则会智能地融合这些 kernel,确保计算的高效和准确。
使用 Tensor-LLM 实现 FP8 推理的性能
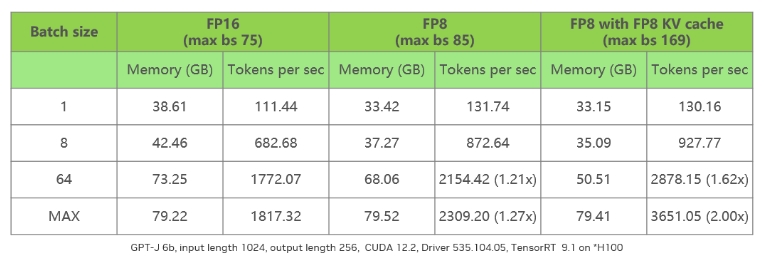
表 2 测试数据仅供技术参考和讨论
表 2 对比第一列不同的 batch size,其中 max 值指的是在设定输入为 1,024,输出为 256,模型为 GPT-J 6B,所能使用的最大 batch size。
列表显示,FP16 的 max 值为 75,而 FP8 的 max 值则提升至 85。原因是 FP8 仅节省了权重部分的内存,部分 tensor 以及 KV cache 仍保持在 FP16。表格最后一列展示了使用 FP8 KV cache 的情况,此时能够看到其 max 值相比 FP16 的 max 值超出 2 倍。
在性能方面,单纯启用 FP8 会由于 batch size 提升有限,以及 KV cache 的影响,导致性能提升并不显著。然而,一旦将 KV cache 也转换至 FP8,通过减半其内存消耗,模型吞吐量可以相较 FP16 提升约两倍左右,这是一个相当理想的性能提升幅度。
[1][2][3] Khudia, D. & Chiley, V. Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave (Part 1)[EB/OL]. Mosaic AI Research, 2023-04-27. [2024-04-23]. https://www.databricks.com/blog/coreweave-nvidia-h100-part-1.




