
GPU アプリケーションを高速化する方法には、主にコンパイラ指示行、プログラミング言語、ライブラリの 3 つがあります。OpenACC などは指示行ベースのプログラミング モデルで、コードをスムーズに GPU に移植し、高速化することができます。使い方は簡単ですが、特定のシナリオでは最適なパフォーマンスが得られない場合があります。
CUDA C や C++ などのプログラミング言語は、アプリケーションを高速化する際に、より大きな柔軟性を与えてくれます。しかし、最新のハードウェアで最適なパフォーマンスを実現するために、新しいハードウェア機能を活用したコードを書くことも、ユーザーの責任です。そこで、そのギャップを埋めるのが、ライブラリです。
コードの再利用性を高めるだけでなく、NVIDIA 数学ライブラリは、最大の性能向上のために GPU ハードウェアを最大限に活用するように最適化されています。アプリケーションを高速化する簡単な方法をお探しなら、NVIDIA 数学ライブラリの使用方法について、引き続きお読みください。
CUDA Toolkit およびハイパフォーマンス コンピューティング (HPC) ソフトウェア開発キット (SDK) の一部として提供されている NVIDIA 数学ライブラリは、計算負荷の高いアプリケーションで遭遇する、幅広い関数の高品質な実装を提供します。これらのアプリケーションには、機械学習、深層学習、分子動力学、計算流体力学 (CFD)、計算化学、医用画像、地震探査の領域が含まれます。
これらのライブラリは、 OpenBLAS 、 LAPACK 、 Intel MKL などの一般的な CPU ライブラリを置き換えるとともに、最小限のコード変更で NVIDIA GPU 上のアプリケーションを高速化するように設計されています。その過程を示すために、倍精度行列の乗算 (DGEMM) 機能の例を作成し、 cuBLAS と OpenBLAS の性能を比較しました。
以下のコード例は、 OpenBLAS の DGEMM 呼び出しの使用方法を示しています。
// Init Data
…
// Execute GEMM
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasTrans, m, n, k, alpha, A.data(), lda, B.data(), ldb, beta, C.data(), ldc);
以下のコード例 2 は、 cuBLAS dgemm の呼び出しを示しています。
// Init Data
…
// Data movement to GPU
…
// Execute GEMM
cublasDgemm(cublasH, CUBLAS_OP_N, CUBLAS_OP_T, m, n, k, &alpha, d_A, lda, d_B, ldb, &beta, d_C, ldc));
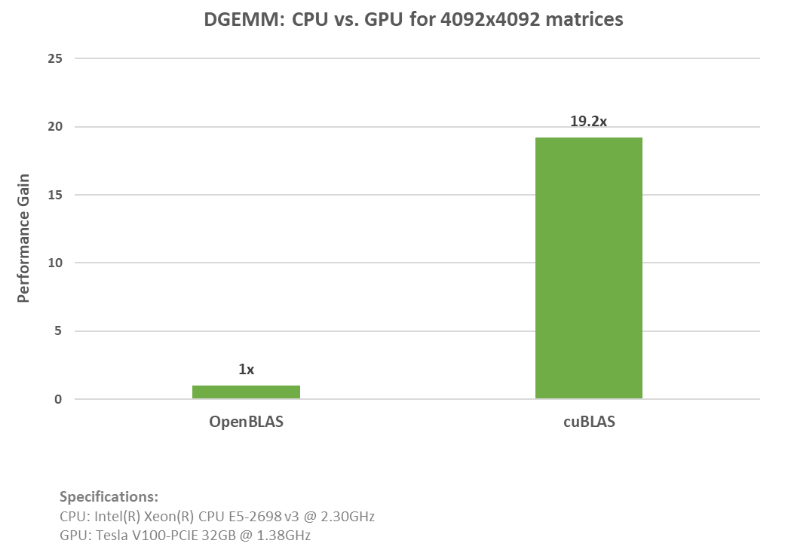
上の例のように、 GPU へのデータ移動を追加し、OpenBLAS の CPU コードを cuBLAS API 関数に置換するだけで、簡単に利用することができます。cuBLAS と OpenBLAS の両方の例の全コードをご覧ください。この cuBLAS の例を、 NVIDIA(R) V100 Tensor コア GPU で実行したところ、 20 倍近いスピードアップを実現しました。下図のグラフは、これらの例を実行した際の条件と、どれだけ高速化したかを示したものです。
面白いことに、これらのライブラリは、cuPy、cuDNN、RAPIDS などの上位の Python API で呼び出されるため、もしあなたがこれらの経験のある方なら、すでにこれらの NVIDIA 数学ライブラリを使っていることになるわけです。
この記事の残りの部分では、利用可能なすべての数学ライブラリについて説明します。最新のアップデートや情報については、 NVIDIA 数学ライブラリの最近の開発状況をご覧ください。
CPU のみの製品と比較して、より優れたパフォーマンスを提供
BLAS の GPU アクセラレーション実装から乱数生成まで、活用できる NVIDIA 数学ライブラリは多数あります。 NVIDIA 数学ライブラリの概要と、アプリケーションの性能を簡単に高めるための始め方については、以下をご覧ください。
cuBLAS による基本的な線形代数サブプログラムの高速化
行列の乗算 (GEMM) は、 AI や科学技術計算で活用されている最も一般的な基本線形代数サブプログラム (BLAS) の 1 つです。 GEMM はまた、ディープラーニング フレームワークの基礎ブロックを形成しています。ディープラーニング フレームワークにおける GEMM の使用については、 GEMM がディープラーニングの中核である理由を参照してください。
cuBLAS ライブラリは、 GPU の機能を利用して大幅な高速化を実現する BLAS の実装です。内積 (レベル 1)、ベクトル加算 (レベル 2)、行列の乗算 (レベル 3) などのベクトルや行列演算を行うルーチンで構成されています。
さらに、行列と行列の掛け算を複数並行して実行したい場合は、cuBLAS はテンソル計算、機械学習、 LAPACK などで利用されている汎用性の高い GEMM のバッチ版サポートしています。機械学習やテンソルの縮約の効率化について詳しくは CPU と GPU の拡張 BLAS カーネルによるテンソルの縮約を参照してください。
cuBLASXt
問題のサイズが大きすぎて GPU に収まらない場合、あるいはアプリケーションがシングルノード、マルチ GPU のサポートを必要とする場合、cuBLASXt は素晴らしい選択肢となります。cuBLASXt は CPU と GPU のハイブリッド計算が可能で、エルミート行列のランク更新を行う herk など、行列間の演算を行う BLAS レベル 3 演算をサポートしています。
cuBLASLt
cuBLASLt は、GEMM をカバーする軽量なライブラリです。cuBLASLt は 2 つ以上のカーネルを 1 つのカーネルに「結合」するカーネル融合により、データの再利用やデータ移動の削減を可能にし、アプリケーションを高速化します。また、エピローグのための後処理オプション (Bias を適用してから ReLU 変換、または入力行列にバイアス勾配を適用など) をユーザーが設定することが可能です。
cuBLASMg: CUDA 数学ライブラリ早期アクセス プログラム
大規模な問題については、最先端のマルチ GPU 、マルチノードの行列 – 行列乗算をサポートする cuBLASMg をチェックしてみてください。現在、 CUDA 数学ライブラリ早期アクセス プログラムの一部となっています。是非、アクセスを申請してください。
cuSPARSE による疎行列の処理
疎行列と密行列の乗算 (SpMM) は、機械学習、深層学習、 CFD 、地震探査、さらには経済分析、グラフ分析、データ分析における多くの複雑なアルゴリズムにとって基本的なものです。疎行列を効率的に処理することは、多くの科学的シミュレーションに不可欠です。
ニューラル ネットワークのサイズが拡大し、それに伴って発生するコストやリソースが増大するため、疎行列化の必要性が生じています。疎行列化は、リソースの使用を最適化するために、ディープラーニングのトレーニングと推論の両方の文脈で人気を博しています。この考え方と cuSPARSE のようなライブラリの必要性についての詳細は、 ディープ ニューラル ネットワークにおける疎性の未来を参照してください。
cuSPARSE は、 GPU で加速されたソルバーを構築するために使用できる、疎行列を扱うための基本的な線形代数サブプログラムのセットを提供します。ライブラリ ルーチンには 4 つのカテゴリがあります。
- レベル 1 は、 2 つのベクトル間の内積など、疎ベクトルと密ベクトル間の演算を行います。
- レベル 2 は、行列 – ベクトル積のように、疎行列と密ベクトル間の演算を行います。
- レベル 3 は、行列 – 行列積のような、疎行列と密ベクトルの集合 (密行列ともみなせる) 間の演算を行います。
- レベル 4 では、異なる行列フォーマット間の変換や、CSR 形式で格納された行列の圧縮が可能です。
cuSPARSELt
疎行列と密行列の乗算を実行する計算機能と、行列の枝刈りや圧縮のためのヘルパー機能を備えた cuSPARSE ライブラリの軽量版については、 cuSPARSELt を試してみてください。 cuSPARSELt ライブラリの詳細については、 cuSPARSELt による NVIDIA Ampere の構造化された疎性の活用を参照してください。
cuTENSOR でテンソルアプリケーションを加速
cuTENSOR ライブラリは、テンソル線形代数ライブラリの実装です。テンソルは機械学習アプリケーションの中核であり、応用問題で使用される支配方程式を導くために用いられる必須の数学ツールです。 cuTENSOR はテンソルの収縮、テンソルのリダクション、要素ごとのテンソル演算のルーチンを提供します。 cuTENSOR は深層学習の学習と推論、コンピューター ビジョン、量子化学、計算物理アプリケーションの性能向上に利用されています。
cuTENSORMg
cuTENSOR の機能はそのままに、大きなテンソルを DGX A100 のような単一ノードで複数の GPU に分散させる機能が必要な場合は、 cuTENSORMg が最適なライブラリとなるでしょう。 広範な混合精度をサポートし、主な計算ルーチンとして直接的なテンソルの縮約、テンソルのリダクション、要素ごとのテンソル演算が含まれます。
cuSOLVER による GPU により高速化された LAPACK 機能
cuSOLVER ライブラリは、cuBLAS と cuSPARSE ライブラリをベースにした線形代数関数のハイレベルなパッケージです。 cuSOLVER は、行列の分解、密行列に対する行列の三角化、疎行列に対する最小二乗法ソルバー、固有値ソルバーなど LAPACK 的機能を備えています。
cuSOLVER は、 3 つの独立したコンポーネントがあります。
- cuSolverDN は、密行列の分解に使用されます。
- cuSolverSP は、 QR 分解に基づく疎行列のためのルーチンのセットを提供します。
- cuSolverRF は、疎行列の構造を共有する行列を繰り返し解くのに有用な疎行列の分解パッケージです。
cuSOLVERMg
GPU で加速された ScaLAPACK 機能、対称行列の固有値ソルバー、 列方向の 1 次元ブロック サイクリック レイアウトのサポート、 cuSOLVER 機能のシングルノード、マルチ GPU サポートについては、cuSOLVERMg を検討してください。
cuSOLVERMp
大規模な連立方程式を解くには、マルチノード、マルチ GPU サポートが必要です。LU 分解やコレスキー分解の機能で知られる cuSOLVERMp は優れた解決策です。
cuRAND による乱数の大規模生成
cuRAND ライブラリは、ホスト (CPU) API またはデバイス (GPU) API のいずれかで、疑似乱数または準乱数ジェネレーターによる乱数生成を行うためのライブラリです。ホスト API では、純粋にホスト上で乱数を生成してホストメモリに格納することもできますし、あるいはホストからのライブラリ呼び出しを通してデバイス上で乱数を生成し、グローバル メモリに格納することも可能です。
デバイス API は、乱数ジェネレーターの状態を設定し、グローバル メモリへの読み書きなしに、ユーザー カーネルが直ちに利用できる乱数列を生成するための関数を定義しています。物理学に基づくいくつかの問題では、大規模な乱数生成の必要性が示されています。
モンテ カルロ シミュレーションは、 GPU 上の乱数ジェネレーターのユースケースの 1 つです。 CUDA Fortran によるモンテ カルロ アプリケーション用 GPU ベースの並列 PRNG の開発は、大規模な乱数生成における cuRAND の応用を紹介しています。
cuFFT による高速フーリエ変換の計算
CUDA Fast Fourier Transform (FFT) ライブラリである cuFFT は、 NVIDIA GPU 上で FFT を計算するためのシンプルなインターフェイスを提供します。 FFT は、複素数または実数値のデータセットの離散フーリエ変換を効率的に計算するための、分割統治法の一種です。計算物理学や一般的な信号処理において、最も広く使用されている数値アルゴリズムの 1 つです。
cuFFT は、医用画像や流体力学など、幅広い用途に使用することができます。光音響顕微鏡における定量的血流イメージングのための並列コンピューティングでは、物理学ベースのアプリケーションにおける cuFFT の利用を例示しています。既存の FFTW アプリケーションをお持ちのユーザーは、 cuFFT を使用して、最小限の労力で簡単に NVIDIA GPU にコードを移植することができます。 cuFFT ライブラリは、既存の FFTW アプリケーションの移植を容易にするために、 FFTW3 API を提供しています。
cuFFTXt
単一ノードの GPU にまたがって FFT 計算を分散させるには、cuFFTXt をチェックしてください。このライブラリには、ユーザーが複数の GPU 上のデータを操作し、データのオーダリングを追跡できるようにし、データを最も効率的に処理できるようにするための関数が含まれています。
cuFFTMp
単一システム内でのマルチ GPU サポートだけでなく、cuFFTMp では複数ノード間でのマルチ GPU をサポートしています。本ライブラリは、 MPI 実装の品質に依存しないため、どのような MPI アプリケーションでも使用することができます。 OpenSHMEM 規格に基づいて NVIDIA GPU のために設計された通信ライブラリである、 NVSHMEM を使用しています。
cuFFTDx
グローバル メモリへの不要なデータ移動を回避し、 FFT カーネルと他の演算の融合を可能にすることでパフォーマンスを向上させるには、cuFFT デバイス拡張 (cuFFTDx) をチェックしてください。 数学ライブラリ デバイス拡張の一部で、アプリケーションはユーザー カーネル内で FFT を計算することができます。
CUDA Math API による標準的な数学関数の最適化
CUDA Math API は、すべての NVIDIA GPU アーキテクチャに最適化された標準数学関数のコレクションです。すべての CUDA ライブラリは、 CUDA Math ライブラリに依存しています。 CUDA Math API は、すべての C99 標準の float および double 数学関数、 float 、 double 、およびすべての丸めモード、そして三角関数および指数関数 (cospi、sincos) や、誤差関数の逆関数 (erfinv、erfcinv) などの異なる関数がサポートされています。
CUTLASS による C ++テンプレートを使ったコードのカスタマイズ
行列の乗算は、多くの科学計算の基礎となっています。特に、ディープラーニング アルゴリズムの効率的な実装において、これらの乗算は重要です。 cuBLAS と同様に、線形代数サブルーチンの CUDA テンプレート (CUTLASS) は、効率的な計算とスケーリングを行うための線形代数ルーチン セットから構成されています。
cuBLAS や cuDNN の実装に用いられたものと同様の、階層的な行列の分解とデータ移動の戦略を取り入れています。しかし、 cuBLAS とは異なり、 CUTLASS はモジュール化と再構成が可能です。 GEMM の各処理を C++ のテンプレート クラスのように再利用可能な基本コンポーネントやブロックに分解し、それによってアルゴリズムをカスタマイズするための柔軟性を提供します。
ソフトウェアはパイプライン化されており、レイテンシを隠蔽し、データの再利用を最大化します。共有メモリに競合なくアクセスし、データ スループットを最大化し、メモリ フットプリントを削減し、アプリケーションを思い通りに設計できます。 CUTLASS を利用したアプリケーションのパフォーマンス向上について詳しくは CUTLASS: CUDA C++ における高速線形代数を参照してください。
AmgX で微分方程式を計算
AmgX は GPU で加速された AMG (代数的マルチグリッド) ライブラリを提供し、シングル GPU または分散ノード上でのマルチ GPU をサポートしています。複雑なネストされたソルバー、スムージング、前処理を作成することができます。このライブラリは、ブロック ヤコビ、ガウス ザイデル、不完全 LU 分解などの様々なスムーザーを備えた古典的、および Unsmoothed aggregation に基づく代数的マルチグリッド法を実装しています。
このライブラリには、 PCG や BICGStab などの前処理付きクリロフ部分空間反復法も含まれています。 AmgX は、シミュレーションにおいて計算量の多い線形ソルバー部分を最大 10 倍まで高速化し、非構造格子を用いた陰解法ソルバーによく適しています。
AmgX は、特に CFD アプリケーションのために開発され、エネルギー、物理、原子力安全などのドメインで使用することができます。 AmgX ライブラリの実際の使用例としては、小規模から大規模の計算問題におけるポアソン方程式の解法が挙げられます。
トビヘビの飛行シミュレーションの例では、GPU で AmgX 使用して CFD コードを高速化することで、時間とコストが削減されることを示しています。この例では、1 台の K20 GPU で 300 万メッシュを処理した場合、 1 台の 12 コア CPU ノードと比較して 21 倍もの高速化を実現しました。
NVIDIA 数学ライブラリを始めましょう
- cuBLAS 、cuRAND 、cuFFT 、cuSPARSE 、cuSOLVER CUDA Math Library は、NVIDIA HPC SDK および CUDA ツールキット に含まれています。
- Math Library Device Extensions (cuFFTDx) は、 MathDx 20.22 で提供されています。
- cuTENSOR、cuSPARSELt、MathDx は DevZone に掲載されています。
- AmgX と CUTLASS は GitHub で公開されています。
- cuBLASMg は、現在 CUDA 数学ライブラリ早期アクセス プログラム の一部として提供されています。
私たちは、NVIDIA 数学ライブラリの改善に引き続き取り組んでいきます。ご質問や新機能のご要望は、プロダクト マネージャーの Matthew Nicely (英語のみ) までご連絡ください。
謝辞
Matthew Nicely の指導と積極的なフィードバックに感謝いたします。また、 Anita Weemaes には、多くのフィードバックと、絶え間ないサポートをいただきました。ありがとうございました。
翻訳に関する免責事項
この記事は、「Accelerating GPU Applications with NVIDIA Math Libraries」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。