この投稿は、Orin プラットフォームを使用する組込み開発者が、YOLOv5 をリファレンスとして、どのようにディープ ニューラル ネットワーク (DNN) を展開できるかについて、技術的に深く掘り下げたものです。読者が簡単に理解できるように、次のセクション “NVIDIA DLA 紹介” で NVIDIA DLA を紹介し、セクション “NVIDIA cuDLA 紹介” で cuDLA と呼ばれる DLA 用の CUDA プログラミング モデル拡張を紹介します。そして最後の “YOLOv5 と cuDLA、Jetson Orin で共演” では、YOLOv5、DLA、cuDLA の組み合わせによる、Jetson Orin プラットフォーム上での効率的なオブジェクト検出実装について詳しく説明します。
DLA の詳細については、DLA 開発者ページおよび DLA チュートリアルの「Getting started with the Deep Learning Accelerator on NVIDIA Jetson Orin」を参照してください。DLA がディープラーニング アプリケーションの性能を最大化するのにどのように役立つかについては、「NVIDIA Jetson Orin の Deep Learning Accelerator (DLA) を活用して、ディープラーニングのパフォーマンスを最大化」をご覧ください。
NVIDIA DLA 紹介
NVIDIA Jetson Orin は、AI ワークロード向けのクラス最高の組み込みプラットフォームです。Orin プラットフォームの主要コンポーネントの 1 つは、AGX Orin プラットフォームの AI コンピューティング パワーの 3 分の 1 を提供する専用のディープラーニング推論エンジンである第 2 世代の Deep Learning Accelerator (DLA) です。
NVIDIA DLA ハードウェアは、ディープラーニング処理をターゲットとした固定機能アクセラレータ エンジンです。その固定機能とは、GPU (グラフィックス プロセッシング ユニット) による汎用アクセラレーションとは異なり、一連のオペレーションをハードウェアレベルで加速するように設計されていることを意味します。畳み込みニューラルネットワークの完全なハードウェア アクセラレーションを行うように設計されており、畳み込み、デコンボリューション、完全連結、活性化、プーリング、バッチ正規化などのさまざまなレイヤーをサポートしています。NVIDIA の Orin SoC は、最大 2 つの第 2 世代 DLA を搭載し、Xavier SoC は、最大 2 つの第 1 世代 DLA を搭載しています。
ハードウェア ブロックを見ると、DLA には次のようなものがあります。
- Depth-wise Processor は、深度ワイズ コンボリューション専用のプロセッサで、モービルネット ファミリに顕著なコンボリューションの一種です。
- コンボリューション コアは、最適化された高性能コンボリューション エンジンです。
- Single Data Processor は、活性化/スケール/バイアス関数用のシングル ポイント エンジンで、ルックアップ演算だけでなく、さまざまな演算を実行できます。
- Planar Data Processor は、各チャンネルを個別に扱い、平均、最大、最小プーリングなどを実行できるエンジンです。
- Channel Data Processor は、ローカル レスポンス ノーマライゼーションなどのノーマライゼーション機能のマルチチャンネル平均化に使用されます。
- 専用メモリ エンジンとデータ再形成エンジンは、異なる入出力テンソル フォーマットの変換、最近傍アップサンプリング、連結などのテンソルの再形成とコピー操作のためのメモリからメモリへの変換を高速化します。
図 1 は、DLA がその直接的なインターフェイスとどのように相互作用するかを示しています。
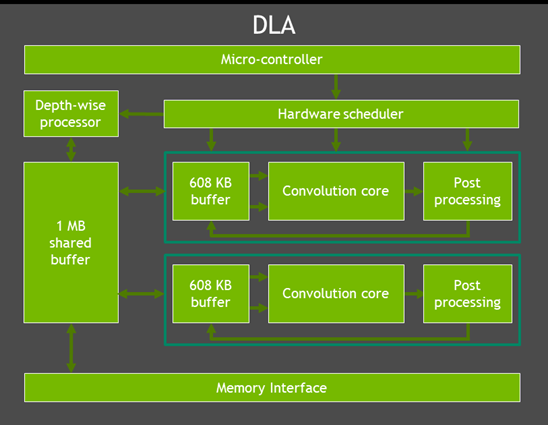
この図の上から、DLA には作業のスケジューリングに使用される専用のマイクロコントローラーがあることがわかります。これにより、CPU はモデル全体の要求をマイコンに提出することができ、マイコンは DLA がモデルを実行する間、CPU がアイドル状態であっても完全に引き継ぐことができます。
Orin の DLA により、AI ワークロードは以前のものよりも効率的にスケジューリングできるようになり、特にレイヤーあたりのワークロードが小さいモデルは、この最適化の恩恵を受けることができます。
DLA には、重み、モデルの入力、出力、および中間テンソルにアクセスするための、システム DRAM への直接インターフェイスがあります。中間テンソルのために、DLA には専用のオンチップ SRAM もあり、以下の典型的なシナリオのように、DRAM トラフィックを最小化し、より低いタスク レイテンシを達成することができます:
- Bias や ReLU のようなポイントワイズ演算を追加した場合と追加しない場合の畳み込みをシームレスに実行することができます。
- ResNets の残差構造部分では、要素ごとの和 (2 つ前の層の出力が要素ごとに追加される) を、ReLU などの後続のアクティベーションと融合させることができます。これは Xavier の DLA では不可能でした。
- Orin の DLA では、サブグラフ全体をローカル SRAM に保持することができます。この最適化により、レイテンシの低減と DRAM 帯域幅消費の低減の両方が得られます。
消費電力に関して、 DLA のハードウェアは、電力効率とトップ/面積の両方において、一連の処理を効率的に加速するように調整されています。実際、DLA の電力効率は約 2.5 倍であり、バッテリー駆動のアプリケーションなど、電力効率が求められる組み込みアプリケーションに最適です。
最も重要な点は、DLA が GPU に加えて DLA ごとに約 48.5 INT8 Sparse TOPS の AI コンピュート機能を提供するため、組み込みアプリケーションにAI機能を追加できることです。SoC プラットフォーム上の GPU を他の機能のために解放したり、SoC 上のアプリケーションの全体的なスループットを向上させることができます。さらに、ミッション クリティカルなアプリケーションや安全なアプリケーションなど、冗長性が重要な場合には、独立した実行パイプラインを提供することができます。
DLA の詳細については、DLA 開発者ページおよび DLA チュートリアル「GettingGetting started with the Deep Learning Accelerator on NVIDIA Jetson Orin」をご参照してください。
DLA がディープラーニング アプリケーションの性能を最大化するのにどのように役立つかについては、「NVIDIA Jetson Orin の Deep Learning Accelerator (DLA) を活用して、ディープラーニングのパフォーマンスを最大化」をご覧ください。
NVIDIA cuDLA を紹介
システム ソフトウェア側では、DLA ソフトウェアは DLA コンパイラと DLA ランタイム スタックで構成されています。オフライン コンパイラは、ニューラル ネットワーク グラフを DLA ロード可能なバイナリに変換し、NVIDIA TensorRT™ を使用して呼び出すことができます。ランタイム スタックは、DLA ファームウェア、カーネル モード ドライバー、およびユーザー モード ドライバーで構成されています。
DLA の性能は、ハードウェア アクセラレーションとソフトウェアの両方によって実現されます。たとえば、DLA ソフトウェアは、フュージョンを実行して、システム メモリとの間のパス数を減らします。また、TensorRT は、DLA ソフトウェア スタックにより高いレベルの抽象化を提供します。
TensorRT は、GPU または DLA のいずれか、あるいは両方で AI 推論を行うための統一プラットフォームと共通インターフェイスを提供します。TensorRT ビルダは、DLA コンパイラを呼び出すコンパイル時とビルド時のインターフェイスを提供します。プラン ファイルが生成されると、TRT ランタイムは DLA ランタイム スタックを呼び出し、DLA コア上でワークロードを実行します。TensorRT はまた、いくつかのフラグを追加指定するだけで、GPU から DLA への移植を容易にします。
以下の図 2 は、前述の DLA の構築フェーズと実行フェーズのワークフローを説明したものです。このプロセスでは、計画ファイルを作成した後、このファイルをアプリケーションからロードして実行したい場合、NVIDIA が提供する DLA ハードウェアを扱うためのアプリケーション プログラミング インターフェイスが cuDLA であることがわかります。
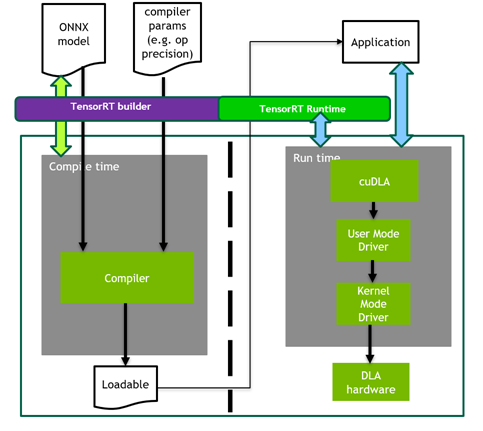
cuDLA は、GPU と DLA のプログラミングを統一するための CUDA のプログラミング モデル拡張です。
cuDLA を使用する開発者は以下を期待できます:
- DLA をプログラミングするための使い慣れた CUDA インターフェイス
- DLA のプログラミングの容易さとラピッド プロトタイピング機能
- 複雑な GPU + DLA ユースケースのセットアップが容易
- パフォーマンスの利点
cuDLA の詳細については、こちらの GTC トークをご参照ください:
cuDLA: CUDA を使用したディープラーニング アクセラレータ プログラミング
YOLOv5 と cuDLA、Jetson Orin で共演
YOLOv5 は物体検出アルゴリズムです。v3 と v4 の成功に基づき、YOLOv5 はリアルタイムの物体検出タスクにおける精度と速度の向上を目指しています。YOLOv5 は、精度と速度の優れたトレードオフにより、コンピュータービジョン分野の研究者や実務家の間で人気のある選択肢となっています。オープンソースで実装されているため、開発者は事前に訓練されたモデルを活用し、特定の目的に応じてカスタマイズすることができます。
以下のセクションでは、エンドツーエンドの YOLOv5 cuDLA サンプルについて説明します:
- Quantization-Aware Training (QAT) を使用して YOLOv5 モデルをトレーニングし、DLA へのデプロイ用にエクスポートします。
- ネットワークをデプロイし、TensorRT と cuDLA を介して CUDA を使用して推論を実行します。
- オンターゲットの YOLOv5 精度検証とパフォーマンス プロファイリングを実行します。
このサンプルを使用して、DLA INT8 を使用して COCO データセットで 37.3 mAP を達成する方法を示します (公式の FP32 mAP は 37.4)。また、NVIDIA Jetson Orin DLA 1 台で、YOLOv5 で 400 FPS 以上を達成する方法を示します。(Orin では合計 2 つの DLA インスタンスが利用可能です)。
DLA 向け QAT トレーニングおよび変換
YOLOv5 の推論性能と精度のバランスを取るには、モデルに Quantization-Aware-Training (QAT) を適用することが不可欠です。本稿執筆時点では、DLA は TensorRT による QAT をサポートしていないため、推論前に QAT モデルをPost-Training Quantization (PTQ) モデルに変換する必要があります。その手順を図 3 に示します。

QAT トレーニングのワークフロー
YOLOv5 を量子化するには、TensorRT pytorch-quantization ツールキットを使用します。最初のステップは、ニューラル ネットワーク グラフに量子化モジュールを追加することです。このツールキットは、一般的な DL 操作のための量子化レイヤ モジュールのセットを提供します。提供されている量子化モジュールの中にモジュールがない場合は、モデルの適切な場所にカスタム量子化モジュールを作成することができます。
図 4 は、QAT トレーニングのワークフローのステップをまとめたものです。2 つ目のステップはモデルのキャリブレーションで、各量子化/非量子化 (Q/DQ) モジュールのスケール値を取得します。キャリブレーションが完了したら、学習スケジュールを選択し、COCO データセットを使用してキャリブレーションされたモデルを微調整します。

Q/DQ ノードの追加
以下の議論では、DLA を使った疎な性能 (Sparse Performance) と密な性能 (Dense Performance) について言及します。これらの概念については、こちらの記事を参照してください:
ネットワークに Q/DQ ノードを追加するには、2 つのオプションがあります:
オプション 1: TensorRT Processing of Q/DQ Networks で推奨されているように、Q/DQ ノードを配置します。この方法は、Q/DQ 層の TensorRT 融合戦略に従います。これらの TensorRT ストラテジーは、ほとんどが GPU 推論用にチューニングされています。DLA と互換性を持たせるために、Q/DQ Translator を使用して、隣接層からのスケールを使用して導き出された Q/DQ ノードを追加します。
スケールが欠落すると、特定のレイヤーが FP16 で動作することになります。その結果、mAP がわずかに減少し、性能が大きく低下する可能性があります。Orin DLA は INT8 畳み込みに最適化されており、FP16 の密な性能の約 15 倍 (FP16 の密な性能と INT8 の疎な性能を比較すると 30 倍) です。
オプション2: Q/DQ ノードを各レイヤーに挿入し、すべてのテンソルが INT8 のスケールを持つようにします。このオプションを使用すると、モデルの微調整中にすべての層のスケールを取得することができます。しかし、この方法は、GPU 上で推論を実行する際に、Q/DQ レイヤーを用いた TensorRT 融合戦略を乱す可能性があり、GPU のレイテンシが高くなります。一方、DLA の場合、PTQ スケールの経験則上、”利用可能なスケールが多ければ多いほど、レイテンシは低くなる ” ことが知られています。
実験によって確認されたように、私たちの YOLOv5 モデルは、解像度 672×672 ピクセルの COCO 2017 検証データセットで検証されました。オプション 1 とオプション 2 はそれぞれ、37.1 と 37.0 の mAP スコアを達成しました。
どちらの方法を選ぶのかは、ニーズに応じて最適なオプションを選択してください。すでに GPU 用の既存の QAT ワークフローがあり、それをできるだけ維持したい場合は、おそらくオプション 1 の方がよいでしょう。(最適な DLA レイテンシを達成するためには、Q/DQ Translator を拡張して、より多くのミッシング スケールを推論する必要があるかもしれません)。
一方、全レイヤーに Q/DQ ノードを挿入し、DLA と互換性のある QAT トレーニング法をお探しなら、オプション 2 が最も有望かもしれません。
Q/DQ Translator ワークフロー
Q/DQ Translator の目的は、QAT で学習された ONNX グラフを、PTQ テンソル スケールと Q/DQ ノードのない ONNX モデルに変換することです。
この YOLOv5 モデルでは、QAT モデルの Q/DQ ノードから量子化スケールを抽出します。YOLOv5 の SiLU や Concat ノードの Sigmoid や Mul のような他の層の入出力スケールを推測するために、隣接する層の情報を使用します。スケールが抽出されたら、TensorRT が DLA エンジン用に構築して使用できるように Q/DQ ノードのない ONNX モデルと (PTQ) キャリブレーション キャッシュ ファイルをエクスポートします。
推論のために DLA にネットワークを展開
次のステップは、ネットワークをデプロイし、TensorRT と cuDLA を介して CUDA を使用して推論を実行することです。
TensorRT でロード可能なビルド
TensorRT を使用して、DLA ローダブルを構築します。これにより、DLA ローダブル構築のための使いやすいインターフェイスと、必要に応じて GPU とのシームレスな統合が実現します。TensorRT-DLA の詳細については、TensorRT 開発者ガイドの DLA を使用するを参照してください。
trtexec は、TensorRT が提供する便利なツールで、エンジンの構築や性能のベンチマークを行うことができます。DLA ローダブルとは、DLA コンパイラによる DLA のコンパイルに成功した結果であり、TensorRT は DLA ローダブルをシリアライズ エンジン内にパッケージ化できることに注意してください。
まず、ONNXモデルと前節で生成したキャリブレーションキャッシュを用意します。DLA ローダブルはコマンド 1 つでビルドできます。オプションを渡すと、モデル全体を DLA 上で実行することができます。これは、コンパイル結果をシリアライズされた DLA ローダブルとして直接保存します (TensorRT エンジンのラッピングなし)。このステップの詳細については、NVIDIA Deep Learning TensorRT ドキュメントを参照してください。
trtexec --onnx=model.onnx --useDLACore=0 --safe --saveEngine=model.loadable --inputIOFormats=int8:dla_hwc4 --outputIOFormats=fp16:chw16 --int8 --fp16 --calib=qat2ptq.cacheモデル入力が適格であれば、性能の観点から入力フォーマット dla_hwc4 を強く推奨します。入力は最大 4 つの入力チャンネルを持ち、コンボリューションによって消費されなければなりません。INT8 では、例えば --inputIOFormats=int8:chw32 を使用した場合には利用できない、DLA 特有のハードウェアとソフトウェアの最適化の恩恵を受けることができます。
cuDLA を使った推論の実行
前項 “cuDLAの紹介 “で述べたように、cuDLA は、DLA と CUDA を統合する CUDA プログラミング モデルの拡張である DLA 用の CUDA ランタイム インターフェイスです。cuDLA を使用して推論を実行するには、TensorRT ランタイムを介して暗黙的に実行するか、明示的に cuDLA API を呼び出します。このサンプルでは、ハイブリッド モードとスタンドアロン モードで推論を実行するために cuDLA API を明示的に呼び出す後者のアプローチを示します。
cuDLA ハイブリッド モードとスタンドアロン モードの主な違いは同期です。ハイブリッド モードでは、DLA タスクは CUDA ストリームに投入されるため、他の CUDA タスクとシームレスに同期を取ることができます。
スタンドアロン モードでは、cudlaTask 構造体は、cudlaSubmitTask の一部として、cuDLA が待機しなければならない待機イベントとシグナル イベントをそれぞれ指定する機能を持っています。
つまり、cuDLA ハイブリッド モードを使用すると、他の CUDA タスクと迅速に統合できます。cuDLA スタンドアロン モードを使用すると、CUDA コンテキストの作成を防ぐことができるため、パイプラインに CUDA コンテキストがない場合にリソースを節約できます。
この YOLOv5 サンプルで使用されている主な cuDLA API の詳細を以下に示します。
cudlaCreateDeviceは DLA デバイスを作成します。cudlaModuleLoadFromMemoryが DLA 使用のエンジンメモリをロードします。cudaMallocとcudlaMemRegisterが呼び出され、最初に GPU にメモリを割り当て、次に CUDA ポインタを DLA に登録します。(ハイブリッド モードでのみ使用)cudlaImportExternalMemoryとcudlaImportExternalSemaphoreは、外部の NvSci バッファと同期オブジェクトをインポートするために呼び出されます。(スタンドアロン モードでのみ使用)- cudlaModuleGetAttributes はロードされたモジュールからモジュール属性を取得します。
- cudlaSubmitTask は推論タスクを投入するために呼び出されます。ハイブリッド モードでは、cuDLA タスクを実行させるために CUDA ストリームを指定する必要があります。スタンドアロン モードでは、cuDLA が待機し、対応するフェンスの有効期限が切れたときにシグナルを送信するために、ユーザーはシグナル イベントと待機イベントを指定する必要があります。
ターゲット上でのバリデーションとプロファイリング
GPU と DLA の数値的な違いに注意することが重要です。基礎となるハードウェアが異なるため、計算がビット単位で正確ではありません。ネットワークのトレーニングは GPU 上で行われ、その後ターゲット上の DLA に展開されるため、ターゲット上で検証することが重要です。これは、量子化に関して特に重要です。基準ベースラインと比較することも重要です。
YOLOv5 DLA の精度検証
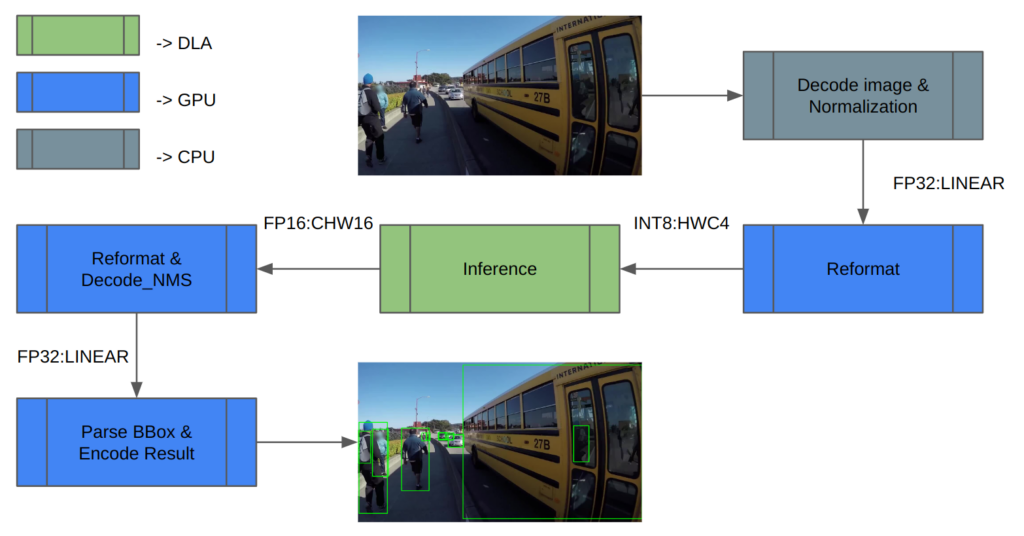
検証には COCO データセットを使用しました。図 5 に推論パイプラインのアーキテクチャを示します。まず、画像データを読み込み、正規化します。DLA は INT8/FP16 しかサポートしていないため、推論の入力と出力には余分な再フォーマットが必要です。
推論後、推論結果をデコードし、NMS (Non-maximum Suppression) を実行して検出結果を得ます。最後に結果を保存し、mAP を計算します。
YOLOv5 の場合、最後の 3 つの畳み込み層の特徴マップが最終的な検出情報をエンコードします。INT8 に量子化すると、バウンディング ボックス座標の量子化誤差が FP16/FP32 に比べて顕著になり、最終的な mAP に影響を与えます。
我々の実験では、最後の 3 つの畳み込みレイヤーを FP16 で実行することで、最終的な mAP が 35.9 から 37.1 に改善されることを示しています。Orin DLA は INT8 に高度に最適化された特別なハードウェア設計をしているため、これら 3 つの畳み込みを FP16 で実行すると性能が低下します。 (図 6 参照)
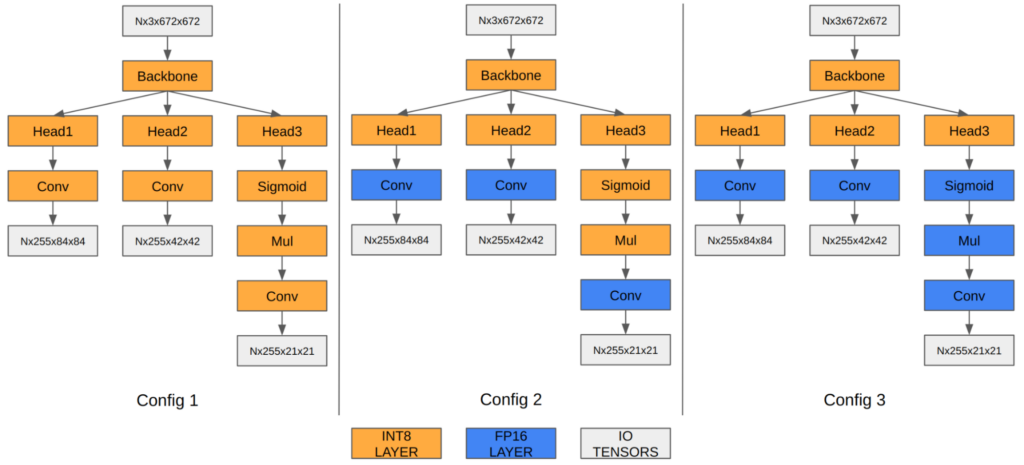
| 構成 1 | 構成 2 | 構成 3 | |
| 入力テンソル形式 | INT8:DLA_HWC4 | INT8:DLA_HWC4 | INT8:DLA_HWC4 |
| 出力テンソル形式 | INT8:CHW32 | FP16:CHW16 | FP16:CHW16 |
| COCO Val mAP | 35.9 | 37.1 | 37.3 |
| FPS (DLA 3.14.0, 1x DLA @ 1.33 GHz, EMC @ 3.2 GHz) | 410 | 255 | 252 |
mAP の結果は、Q/DQ ノードの追加に関する前のセクションで説明したオプション 1 に基づいていることに注意してください。同じ原理をオプション 2 にも適用できます。
YOLOv5 DLA のパフォーマンス
DLA は、2 つの DLA コアにより、Orin AGX プラットフォーム上のAIコンピューティングの 3 分の 1 を提供します。Orin DLA のパフォーマンスの一般的なベースラインについては、GitHubの Deep-Learning-Accelerator-SW を参照してください。
最新リリースの DLA 3.14.0 (DOS 6.0.8.0およびJetPack 6.0) では、DLA コンパイラに INT8 CNN アーキテクチャベースのモデルに特化したいくつかの性能最適化が追加されました:
- ネイティブ INT8 シグモイド (以前は FP16 で実行され、INT8 との間でキャストする必要がありました。)
- INT8 SiLU を 1 つの DLA HW 演算に融合 (単体のシグモイド+単体のエレメントワイズ Mul の代わり)
- INT8 SiLU HW 演算と以前の INT8 Conv HW 演算の融合 (単体の Sigmoid や Tanh にも適用可能)
これらの改善により、YOLO アーキテクチャは以前のリリースと比較して 6 倍のスピードアップを実現できます。例えば、YOLOv5 の場合、推論性能は INT8 で 13 ミリ秒から 2.4 ミリ秒 (いくつかのレイヤーは FP16 で実行) に跳ね上がり、これは 5.4 倍の改善です。さらに、cuDLA サンプルを使用して DNN をレイヤーごとにプロファイリングし、ボトルネックを特定し、パフォーマンスを向上させるためにネットワークを修正することができます。
DLA を始める
この投稿では、専用のディープラーニング アクセラレータで YOLOv5 を使用して、最も効率的な方法で Orin 上でオブジェクト検出パイプライン全体を実行する方法を説明しました。GPU などの他の SoC コンポーネントは、アイドリング状態か非常に小さな負荷で動作していることに留意してください。30fps で入力を生成するカメラが 1 台あれば、1 つの DLA インスタンスの負荷は 10% 程度です。したがって、アプリケーションに付加機能を追加する余地が十分にあります。
準備はいいですか? YOLOv5 のサンプルは、ここで説明したワークフロー全体を再現しています。あなた自身のユース ケースのリファレンス ポイントとしてお使いください。
初心者の方のために、GitHub の Jetson_dla_tutorial では基本的な DLA ワークフローを紹介しています。
DLA を活用して NVIDIA DRIVE または NVIDIA Jetson を最大限に活用するためのその他のサンプルやリソースについては、GitHub の Deep-Learning-Accelerator-SW をご覧ください。cuDLA の詳細については、Deep-Learning-Accelerator-SW/samples/cuDLA をご覧ください。
関連情報
- GTC セッション: Jetson Edge AI Developer Days: Getting the Most Out of Your Jetson Orin Using NVIDIA Nsight Developer Tools (Spring 2023)
- GTC セッション: How to Build a Robust Platform for Real-Time Inference: Learnings from Michelangelo (Spring 2023)
- NGC コンテナー: NVIDIA MLPerf Inference
- ウェビナー: JetPack 5.0.2 Walkthrough: The First Production Release for Jetson Orin-based Modules
- ウェビナー: Simplify model deployment and maximize AI inference performance with NVIDIA Triton Inference Server on Jetson
- ウェビナー: Train Smarter, Not Harder with Pre-Trained Models and Transfer Learning
- 技術ブログ: Deploying YOLOv5 on NVIDIA Jetson Orin with cuDLA: Quantization-Aware Training to Inference