
Consider a large language model (LLM) application that is designed to help financial analysts answer questions about the performance of a company. With a well-designed retrieval augmented generation (RAG) pipeline, analysts can answer questions like, “What was X corporation’s total revenue for FY 2022?” This information can be easily extracted from financial statements by a seasoned analyst.

Now consider a question like, “What were the three takeaways from the Q2 earnings call from FY 23? Focus on the technological moats that the company is building”. This is the type of question a financial analyst would want answered to include in their reports but would need to invest time to answer.
How do we develop a solution to answer a question like above? It is immediately apparent that this information requires more than a simple lookup from an earnings call. This inquiry requires planning, tailored focus, memory, using different tools, and breaking down a complex question into simpler sub-parts.. These concepts assembled together are essentially what we have come to refer to as an LLM Agent.
In this post, I introduce LLM-powered agents and discuss what an agent is and some use cases for enterprise applications. For more information, see Building Your First Agent Application. In that post, I offer an ecosystem walkthrough, covering the available frameworks for building AI agents and a getting started guide for anyone experimenting with question-and-answer (Q&A) agents.
What is an AI agent?
While there isn’t a widely accepted definition for LLM-powered agents, they can be described as a system that can use an LLM to reason through a problem, create a plan to solve the problem, and execute the plan with the help of a set of tools.
In short, agents are a system with complex reasoning capabilities, memory, and the means to execute tasks.
This capability was first observed in projects like AutoGPT or BabyAGI, where complex problems were solved without much intervention. To describe agents a bit more, here’s the general architecture of an LLM-powered agent application (Figure 1).
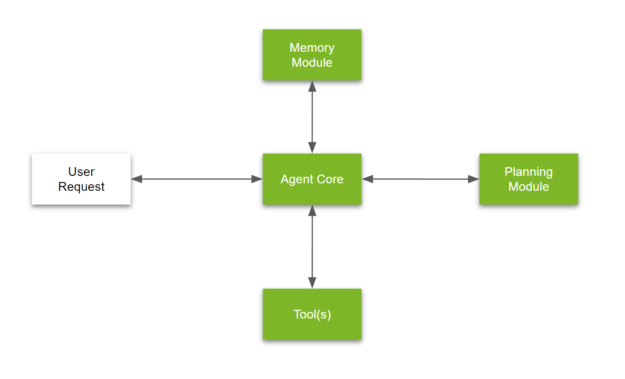
An agent is made up of the following key components (more details on these shortly):
- Agent core
- Memory module
- Tools
- Planning module
Agent core
The agent core is the central coordination module that manages the core logic and behavioral characteristics of an Agent. Think of it as the “key decision making module” of the agent. It is also where we define:
- General goals of the agent: Contains overall goals and objectives for the agent.
- Tools for execution: Essentially a short list or a “user manual” for all the tools to which the agent has access
- Explanation for how to make use of different planning modules: Details about the utility of different planning modules and which to use in what situation.
- Relevant Memory: This is a dynamic section which fills the most relevant memory items from past conversations with the user at inference time. The “relevance” is determined using the question user asks.
- Persona of the Agent (optional): This persona description is typically used to either bias the model to prefer using certain types of tools or to imbue typical idiosyncrasies in the agent’s final response.
Memory module
Memory modules play a critical role in AI agents. A memory module can essentially be thought of as a store of the agent’s internal logs as well as interactions with a user.
There are two types of memory modules:
- Short-term memory: A ledger of actions and thoughts that an agent goes through to attempt to answer a single question from a user: the agent’s “train of thought.”
- Long-term memory: A ledger of actions and thoughts about events that happen between the user and agent. It is a log book that contains a conversation history stretching across weeks or months.
Memory requires more than semantic similarity-based retrieval. Typically, a composite score is made up of semantic similarity, importance, recency, and other application-specific metrics. It is used for retrieving specific information.
Tools
Tools are well-defined executable workflows that agents can use to execute tasks. Oftentimes, they can be thought of as specialized third-party APIs.
For instance, agents can use a RAG pipeline to generate context aware answers, a code interpreter to solve complex programmatically tasks, an API to search information over the internet, or even any simple API service like a weather API or an API for an Instant messaging application.
Planning module
Complex problems, such as analyzing a set of financial reports to answer a layered business question, often require nuanced approaches. With an LLM–powered agent, this complexity can be dealt with by using a combination of two techniques:
- Task and question decomposition
- Reflection or critic
Task and question decomposition
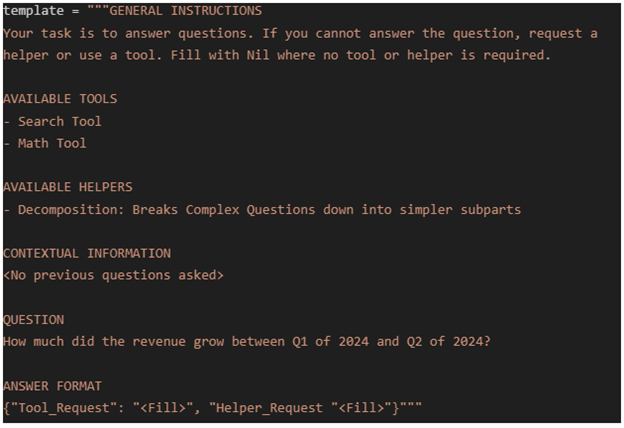
Compound questions or inferred information require some form of decomposition. Take, for instance, the question, “What were the three takeaways from NVIDIA’s last earnings call?”
The information required to answer this question is not directly extractable from the transcript of an hour long meeting. However, the problem can be broken down into multiple question topics:
- “Which technological shifts were discussed the most?”
- “Are there any business headwinds?”
- “What were the financial results?”
Each of these questions can be further broken into subparts. That said, a specialized AI agent must guide this decomposition.
Reflection or critic
Techniques like ReAct, Reflexion, Chain of Thought, and Graph of thought have served as critic– or evidence-based prompting frameworks. They have been widely used to improve the reasoning capabilities and responses of LLMs. These techniques can also be used to refine the execution plan generated by the agent.
Agents for enterprise applications
While the applications of agents are practically boundless, the following are a few interesting cases that may have an outsized impact for many businesses:
- “Talk to your data” agent
- Swarm of agents
- Recommendation and experience design agents
- Customized AI author agents
- Multi-modal agents
“Talk to your data” agent
“Talk to your data” isn’t a simple problem. There are a lot of challenges that a straightforward RAG pipeline can’t solve:
- Semantic similarity of source documents
- Complex data structures, like tables
- Lack of apparent context (not every chunk contains markers for its source)
- The complexity of the questions that users ask
- …and more
For instance, go back to the prior earning’s call transcript example (Q3, 2023 | Q1 2024). How do you answer the question, “How much did the data center revenue increase between Q3 of 2023 and Q1 of 2024?” To answer this question, you essentially must answer three questions individually (i.e., we need a planning module):
- What was the data center revenue in Q3 of 2023?
- What was the data center revenue in Q1 of 2024?
- What was the difference between the two?
In this case, you would need an agent that has access to a Planning Module that does question-decomposition (generates sub-questions and searches for answers till the larger problem is solved), a RAG pipeline (used as a tool) to retrieve specific information, and memory modules to accurately handle the subquestions. In the LLM-Powered Agents: Building Your First Agent Application post, I go over this type of case in detail.
Swarm of agents
A swarm of agents can be understood as a collection of agents working together towards co-existing in a single environment which can collaborate with each other to solve problems. A decentralized ecosystem of agents is very much akin to multiple “smart” microservices used in tandem to solve problems.
Multi-agent environments like Generative Agents and ChatDev have been extremely popular with the community (Figure 3). Why? Frameworks like ChatDev enable you to build a team of engineers, designers, product management, CEO, and agents to build basic software at low costs. Popular games like Brick Breaker or Flappy Bird can be prototyped for as low as 50 cents!
With a swarm of agents, you can populate a digital company, neighborhood, or even a whole town for applications like behavioral simulations for economic studies, enterprise marketing campaigns, UX elements of physical infrastructure, and more.

These applications are currently not possible to simulate without LLMs and are extremely expensive to run in the real world.
Agents for recommendation and experience design
The internet works off recommendations. Conversational recommendation systems powered by agents can be used to craft personalized experiences.
For example, consider an AI agent on an e-commerce website that helps you compare products and provides recommendations based on your general requests and selections. A full concierge-like experience can also be built, with multiple agents assisting an end user to navigate a digital store. Experiences like selecting which movie to watch or which hotel room to book can be crafted as conversations—and not just a series of decision-tree-style conversations!
Customized AI author agents
Another powerful tool is having a personal AI author that can help you with tasks such as co-authoring emails or preparing you for time-sensitive meetings and presentations. The problem with regular authoring tools is that different types of material must be tailored according to various audiences. For instance, an investor pitch must be worded differently than a team presentation.
Agents can harness your previous work. Then, you have the agent mold an agent-generated pitch to your personal style and customize the work according to your specific use case and needs. This process is often too nuanced for general LLM fine-tuning.
Multi-modal agents
With only text as an input, you cannot really “talk to your data.” All the mentioned use cases can be augmented by building multi-modal agents that can digest a variety of inputs, such as images and audio files.
That was just a few examples of directions that can be pursued to solve enterprise challenges. Agents for data curation, social graphs, and domain expertise are all active areas being pursued by the development community for enterprise applications.
What’s next?
LLM-powered agents differ from typical chatbot applications in that they have complex reasoning skills. Made up of an agent core, memory module, set of tools, and planning module, agents can generate highly personalized answers and content in a variety of enterprise settings—from data curation to advanced e-commerce recommendation systems.
For an overview of the technical ecosystem around agents, such as implementation frameworks, must-read papers, posts, and related topics, see Building Your First Agent Application. The walkthrough of a no-framework implementation of a Q&A agent helps you better talk to your data.
To delve into other types of LLM agents, see Build an LLM-Powered API Agent for Task Execution and Build an LLM-Powered Data Agent for Data Analysis.
