
Large language models (LLMs) have revolutionized natural language processing (NLP) with their ability to learn from massive amounts of text and generate fluent and coherent texts for various tasks and domains. However, customizing LLMs is a challenging task, often requiring a full training process that is time-consuming and computationally expensive. Moreover, training LLMs requires a diverse and representative dataset, which can be difficult to obtain and curate.
How can enterprises leverage the power of LLMs without paying the cost of full training? One promising solution is Low-Rank Adaptation (LoRA), a fine-tuning method that can significantly reduce the number of trainable parameters, the memory requirement, and the training time, while achieving comparable or even better performance than fine-tuning on various NLP tasks and domains.
This post explains the intuition and the implementation of LoRA, and shows some of its applications and benefits. It also compares LoRA with supervised fine-tuning and prompt engineering, and discusses their advantages and limitations. It outlines practical guidelines for both training and inference of LoRA-tuned models. Finally, it demonstrates how to use NVIDIA TensorRT-LLM to optimize deployment of LoRA models on NVIDIA GPUs.
Tutorial prerequisites
To make best use of this tutorial, you will need basic knowledge of LLM training and inference pipelines, as well as:
- Basic knowledge of linear algebra
- Hugging Face registered user access and general familiarity with the Transformers library
- NVIDIA/TensorRT-LLM optimization library
- NVIDIA Triton Inference Server with TensorRT-LLM backend
What is LoRA?
LoRA is a fine-tuning method that introduces low-rank matrices into each layer of the LLM architecture, and only trains these matrices while keeping the original LLM weights frozen. It is among the LLM customization tools supported in NVIDIA NeMo (Figure 1).
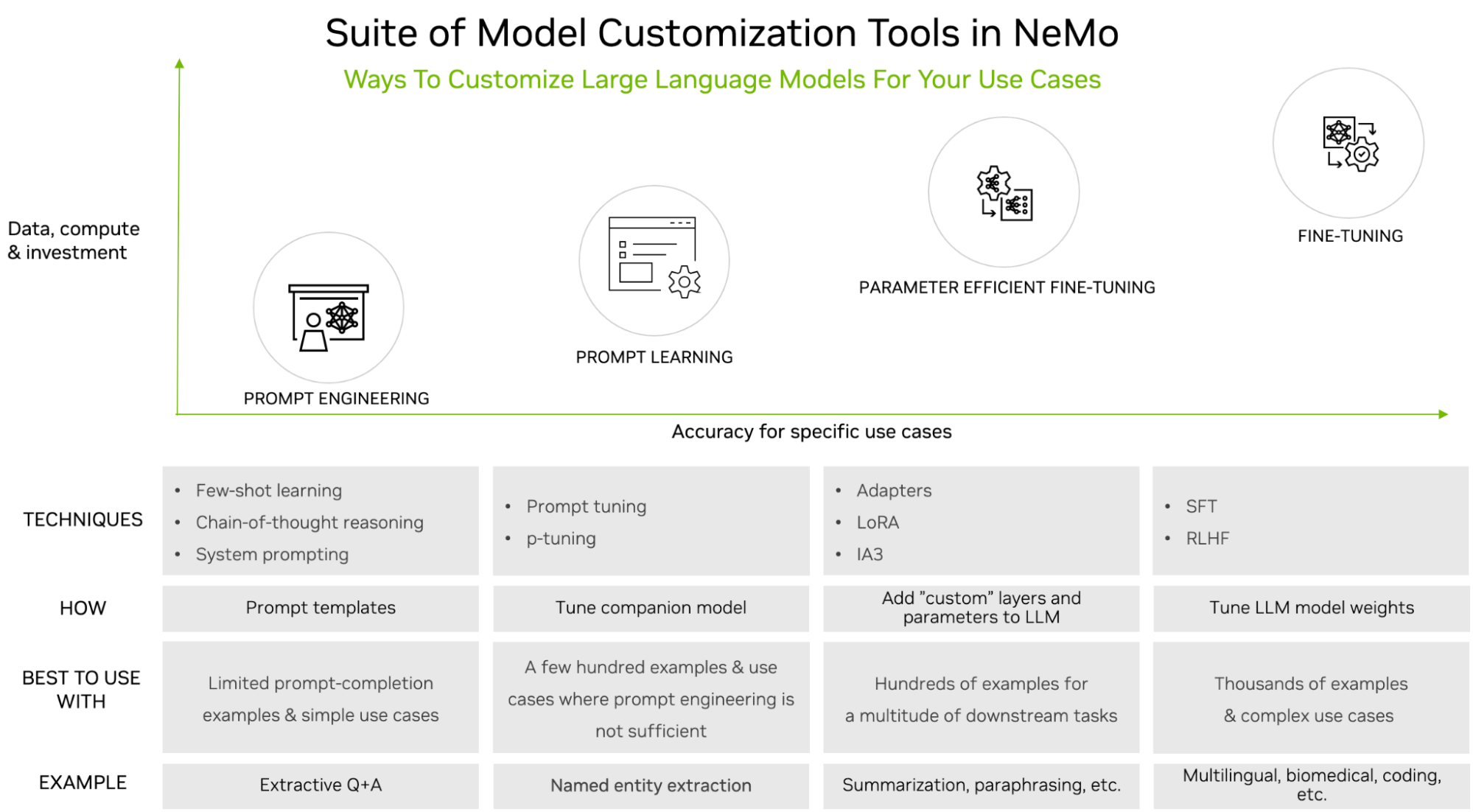
LLMs are powerful, but often require customization, especially when used for enterprise or domain-specific use cases. There are many tuning options, ranging from simple prompt engineering to supervised fine-tuning (SFT). The choice of tuning option is typically based on the size of the dataset required (minimum for prompt engineering, maximum for SFT) and compute availability.
LoRA tuning is a type of tuning family called Parameter Efficient Fine-Tuning (PEFT). These techniques are a middle-of-the-road approach. They require more training data and compute compared to prompt engineering, but also yield much higher accuracy. The common theme is that they introduce a small number of parameters or layers while keeping the original LLM unchanged.
PEFT has been proven to achieve comparable accuracy to SFT while using less data and less computational resources. Compared to other tuning techniques, LoRA has several advantages. It reduces the computational and memory cost, as it only adds a few new parameters, but does not add any layers. It enables multi-task learning, allowing a single-base LLM to be used for different tasks by deploying the relevant fine-tuned LoRA variant on demand, only loading its low-rank matrices when needed.
Finally, it avoids catastrophic forgetting, the natural tendency of LLMs to abruptly forget previously learned information upon learning new data. Quantitatively, LoRA performs better than models using alternative tuning techniques such as prompt tuning and adapters, as shown in LoRA: Low-Rank Adaptation of Large Language Models.
The math behind LoRA
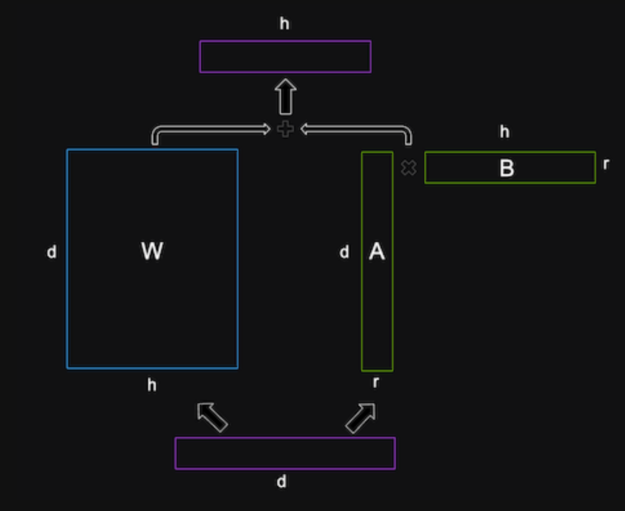
The math behind LoRA is based on the idea of low-rank decomposition, which is a way of approximating a matrix by a product of two smaller matrices with lower ranks. A rank of a matrix is the number of linearly independent rows or columns in the matrix. A low-rank matrix has fewer degrees of freedom and can be represented more compactly than a full-rank matrix.
LoRA applies low-rank decomposition to the weight matrices of the LLM, which are usually very large and dense. For example, if the LLM has a hidden size of 1,024 and a vocabulary size of 50,000, then the output weight matrix \(W\) would have 1024 x 50,000 = 51,200,000 parameters.
LoRA decomposes this matrix \(W\) into two smaller matrices, matrix \(A\) with the shape of 1024 x \(r\) and matrix \(B\) with the shape of \(r\) x 50,000, where \(r\) is a hyperparameter that controls the rank of the decomposition. The product of these two matrices would have the same shape as the original matrix, but only 1024 x \(r\) + \(r\) x 50,000 = 51,200,000 – 50,000 x (1024 – \(r\)) parameters.
The hyperparameter \(r\) is critical to set correctly. Choosing a smaller \(r\) can save a lot of parameters and memory and achieve faster training. However, a smaller \(r\) can potentially decrease task-specific information captured in the low-rank matrices. A larger \(r\) can lead to overfitting. Hence, it’s important to experiment in order to achieve the ideal accuracy-performance trade-off for your specific task and data.
LoRA inserts these low-rank matrices into each layer of the LLM, and adds them to the original weight matrices. The original weight matrices are initialized with the pretrained LLM weights and are not updated during training. The low-rank matrices are randomly initialized and are the only parameters that are updated during training. LoRA also applies layer normalization to the sum of the original and low-rank matrices to stabilize the training.
Multi-LoRA deployment
One challenge in deploying LLMs is how to efficiently serve hundreds or thousands of tuned models. For example, a single base LLM, such as Llama 2, may have many LoRA-tuned variants per language or locale. A standard system would require loading all the models independently, taking up large amounts of memory capacity. Take advantage of LoRA’s design, capturing all the information in smaller low-rank matrices per model, by loading a single base model together with the low-rank matrices A and B for each respective LoRA tuned variant. In this manner, it’s possible to store thousands of LLMs and run them dynamically and efficiently within a minimal GPU memory footprint.
LoRA tuning
LoRA tuning requires preparing a training dataset in a specific format, typically using prompt templates. You should determine and adhere to a pattern when forming the prompt, which will naturally vary across different use cases. An example for question and answer is shown below.
{
"taskname": "squad",
"prompt_template": "<|VIRTUAL_PROMPT_0|> Context: {context}\n\nQuestion: {question}\n\nAnswer:{answer}",
"total_virtual_tokens": 10,
"virtual_token_splits": [10],
"truncate_field": "context",
"answer_only_loss": True,
"answer_field": "answer",
}
The prompt contains all the 10 virtual tokens at the beginning, followed by the context, the question, and finally the answer. The corresponding fields in the training data JSON object will be mapped to this prompt template to form complete training examples.
There are several available platforms for customizing LLMs. You can use NVIDIA NeMo, or a tool such as Hugging Face PEFT. For an example of how to tune LoRA on the PubMed dataset using NeMo, see NeMo Framework PEFT with Llama 2.
Note that this post uses ready-tuned LLMs from Hugging Face, so there is no need to tune.
LoRA inference
To optimize a LoRA-tuned LLM with TensorRT-LLM, you must understand its architecture and identify which common base architecture it most closely resembles. This tutorial uses Llama 2 13B and Llama 2 7B as the base models, as well as several LoRA-tuned variants available on Hugging Face.
The first step is to use the converter and build scripts in this directory to compile all the models and prepare them for hardware acceleration. I’ll then show examples of deployment using both the command line and Triton Inference Server.
Note that the tokenizer is not handled directly by TensorRT-LLM. But it is necessary to be able to classify it within a defined tokenizer family for runtime and for setting preprocessing and postprocessing steps in Triton.
Set up and build TensorRT-LLM
Start by cloning and building the NVIDIA/TensorRT-LLM library. The easiest way to build TensorRT-LLM and retrieve all its dependencies is to use the included Dockerfile. These commands pull a base container and install all the dependencies needed for TensorRT-LLM inside the container. It then builds and installs TensorRT-LLM itself in the container.
git lfs install
git clone -b v0.7.1 https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
git submodule update --init --recursive
make -C docker release_build
Retrieve model weights
Download the base model and LoRA model from Hugging Face:
git-lfs clone https://huggingface.co/meta-llama/Llama-2-13b-hf
git-lfs clone https://huggingface.co/hfl/chinese-llama-2-lora-13b
Compile the model
Build the engine, setting --use_lora_plugin and --hf_lora_dir. If LoRA has a separate lm_head and embedding, these will replace the lm_head and embedding of the base model.
python convert_checkpoint.py --model_dir /tmp/llama-v2-13b-hf \
--output_dir ./tllm_checkpoint_2gpu_lora \
--dtype float16 \
--tp_size 2 \
--hf_lora_dir /tmp/chinese-llama-2-lora-13b
trtllm-build --checkpoint_dir ./tllm_checkpoint_2gpu_lora \
--output_dir /tmp/new_lora_13b/trt_engines/fp16/2-gpu/ \
--gpt_attention_plugin float16 \
--gemm_plugin float16 \
--lora_plugin float16 \
--max_batch_size 1 \
--max_input_len 512 \
--max_output_len 50 \
--use_fused_mlp
Run the model
To run the model during inference, set up the lora_dir command line argument. Remember to use the LoRA tokenizer, as the LoRA-tuned model has a larger vocabulary size.
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \
--max_output_len 50 \
--tokenizer_dir "chinese-llama-2-lora-13b/" \
--input_text "今天天气很好,我到公园的时后," \
--lora_dir "chinese-llama-2-lora-13b/" \
--lora_task_uids 0 \
--no_add_special_tokens \
--use_py_session
Input: "今天天气很好,我到公园的时后,"
Output: "发现公园里人很多,有的在打羽毛球,有的在打乒乓球,有的在跳绳,还有的在跑步。我和妈妈来到一个空地上,我和妈妈一起跳绳,我跳了1"
You can run ablation tests to see the contribution of the LoRA-tuned model first-hand. To easily compare results with and without LoRa, simply set the UID to -1 using --lora_task_uids -1. In this case, the model will ignore the LoRA module and the results will be based on the base model alone.
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \
--max_output_len 50 \
--tokenizer_dir "chinese-llama-2-lora-13b/" \
--input_text "今天天气很好,我到公园的时后," \
--lora_dir "chinese-llama-2-lora-13b/" \
--lora_task_uids -1 \
--no_add_special_tokens \
--use_py_session
Input: "今天天气很好,我到公园的时后,"
Output: "我看见一个人坐在那边边看书书,我看起来还挺像你,可是我走过过去问了一下他说你是你吗,他说没有,然后我就说你看我看看你像你,他说说你看我像你,我说你是你,他说你是你,"
Run the base model with multiple LoRA-tuned models
TensorRT-LLM also supports running a single base model with multiple LoRA-tuned modules at the same time. Here, we use two LoRA checkpoints as examples. As the rank \(r\) of the LoRA modules of both checkpoints is 8, you can set --max_lora_rank to 8 in order to reduce the memory requirement for the LoRA plugin.
This example uses a LoRA checkpoint fine-tuned on the Chinese dataset chinese-llama-lora-7b and a LoRA checkpoint fine-tuned on the Japanese dataset Japanese-Alpaca-LoRA-7b-v0. For TensorRT-LLM to load several checkpoints, pass in the directories of all the LoRA checkpoints through --lora_dir "chinese-llama-lora-7b/" "Japanese-Alpaca-LoRA-7b-v0/". TensorRT-LLM will assign lora_task_uids to these checkpoints. lora_task_uids -1 is a predefined value, which corresponds to the base model. For example, passing lora_task_uids 0 1 will use the first LoRA checkpoint on the first sentence and use the second LoRA checkpoint on the second sentence.
To verify correctness, pass the same Chinese input 美国的首都在哪里? \n答案: three times, as well as the same Japanese input アメリカ合衆国の首都はどこですか? \n答え: three times. (In English, both inputs mean, “Where is the capital of America? \nAnswer”). Then run on the base model, chinese-llama-lora-7b and Japanese-Alpaca-LoRA-7b-v0, respectively:
git-lfs clone https://huggingface.co/hfl/chinese-llama-lora-7b
git-lfs clone https://huggingface.co/kunishou/Japanese-Alpaca-LoRA-7b-v0
BASE_LLAMA_MODEL=llama-7b-hf/
python convert_checkpoint.py --model_dir ${BASE_LLAMA_MODEL} \
--output_dir ./tllm_checkpoint_1gpu_lora_rank \
--dtype float16 \
--hf_lora_dir /tmp/Japanese-Alpaca-LoRA-7b-v0 \
--max_lora_rank 8 \
--lora_target_modules "attn_q" "attn_k" "attn_v"
trtllm-build --checkpoint_dir ./tllm_checkpoint_1gpu_lora_rank \
--output_dir /tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/ \
--gpt_attention_plugin float16 \
--gemm_plugin float16 \
--lora_plugin float16 \
--max_batch_size 1 \
--max_input_len 512 \
--max_output_len 50
python ../run.py --engine_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \
--max_output_len 10 \
--tokenizer_dir ${BASE_LLAMA_MODEL} \
--input_text "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" \
--lora_dir "lchinese-llama-lora-7b/" "Japanese-Alpaca-LoRA-7b-v0/" \
--lora_task_uids -1 0 1 -1 0 1 \
--use_py_session --top_p 0.5 --top_k 0
The results are shown below:
Input [Text 0]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 0 Beam 0]: "Washington, D.C.
What is the"
Input [Text 1]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 1 Beam 0]: "华盛顿。
"
Input [Text 2]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 2 Beam 0]: "Washington D.C.'''''"
Input [Text 3]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 3 Beam 0]: "Washington, D.C.
Which of"
Input [Text 4]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 4 Beam 0]: "华盛顿。
"
Input [Text 5]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 5 Beam 0]: "ワシントン D.C."
Notice that chinese-llama-lora-7b produces correct answers on the first sentence and the fifth sentence (in Chinese). Japanese-Alpaca-LoRA-7b-v0 produces correct answers on the sixth sentence (in Japanese).
Important note: If one of the LoRA modules contains a fine-tuned embedding table or logit GEMM, users must guarantee that all instances of the model can use the same fine-tuned embedding table or logit GEMM.
Deploying LoRA tuned models with Triton and inflight batching
This section shows how to deploy LoRA-tuned models using inflight batching with Triton Inference server. For specific instructions on setting up and launching the Triton Inference Server, see Deploy an AI Coding Assistant with NVIDIA TensorRT-LLM and NVIDIA Triton.
As before, first compile a model with LoRA enabled, this time with the base model Llama 2 7B.
BASE_MODEL=llama-7b-hf
python3 tensorrt_llm/examples/llama/build.py --model_dir ${BASE_MODEL} \
--dtype float16 \
--remove_input_padding \
--use_gpt_attention_plugin float16 \
--enable_context_fmha \
--use_gemm_plugin float16 \
--output_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \
--max_batch_size 128 \
--max_input_len 512 \
--max_output_len 50 \
--use_lora_plugin float16 \
--lora_target_modules "attn_q" "attn_k" "attn_v" \
--use_inflight_batching \
--paged_kv_cache \
--max_lora_rank 8 \
--world_size 1 --tp_size 1
Next, generate LoRA tensors that will be passed in with each request to Triton.
git-lfs clone https://huggingface.co/hfl/chinese-llama-lora-7b
git-lfs clone https://huggingface.co/kunishou/Japanese-Alpaca-LoRA-7b-v0
python3 tensorrt_llm/examples/hf_lora_convert.py -i Japanese-Alpaca-LoRA-7b-v0 -o Japanese-Alpaca-LoRA-7b-v0-weights --storage-type float16
python3 tensorrt_llm/examples/hf_lora_convert.py -i chinese-llama-lora-7b -o chinese-llama-lora-7b-weights --storage-type float16
Then create a Triton model repository and launch the Triton server as previously described.
Finally, run the multi-LoRA example by issuing multiple concurrent requests from the client. The inflight batcher will execute mixed batches with multiple LoRAs in the same batch.
INPUT_TEXT=("美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:")
LORA_PATHS=("" "chinese-llama-lora-7b-weights" "Japanese-Alpaca-LoRA-7b-v0-weights" "" "chinese-llama-lora-7b-weights" "Japanese-Alpaca-LoRA-7b-v0-weights")
for index in ${!INPUT_TEXT[@]}; do
text=${INPUT_TEXT[$index]}
lora_path=${LORA_PATHS[$index]}
lora_arg=""
if [ "${lora_path}" != "" ]; then
lora_arg="--lora-path ${lora_path}"
fi
python3 inflight_batcher_llm/client/inflight_batcher_llm_client.py \
--top-k 0 \
--top-p 0.5 \
--request-output-len 10 \
--text "${text}" \
--tokenizer-dir /home/scratch.trt_llm_data/llm-models/llama-models/llama-7b-hf \
${lora_arg} &
done
wait
Example output is shown below:
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: ワシントン D.C.
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 29871, 31028, 30373, 30203, 30279, 30203, 360, 29889, 29907, 29889]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: Washington, D.C.
What is the
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 5618, 338, 278]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: Washington D.C.
Washington D.
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 360, 29889, 29907, 29889, 13, 29956, 7321, 360, 29889]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: Washington, D.C.
Which of
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 8809, 436, 310]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: Washington D.C.
1. ア
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 360, 29889, 29907, 29889, 13, 29896, 29889, 29871, 30310]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: 华盛顿
W
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 1
Conclusion
With baseline support for many popular LLM architectures, TensorRT-LLM makes it easy to deploy, experiment, and optimize with a variety of code LLMs. Together, NVIDIA TensorRT-LLM and NVIDIA Triton Inference Server provide an indispensable toolkit for optimizing, deploying, and running LLMs efficiently. With support for LoRA-tuned models, TensorRT-LLM enables efficient deployment of customized LLMs, significantly reducing memory and computational cost.
To get started, download and set up the NVIDIA/TensorRT-LLM open-source library, and experiment with the different example LLMs. You can tune your own LLM using NVIDIA NeMo—see NeMo Framework PEFT with Llama 2 for an example. As an alternative, you can also deploy using the NeMo Framework Inference Container.
