
In the era of generative AI, where machines are not just learning from data but generating human-like text, images, video, and more, retrieval-augmented generation (RAG) stands out as a groundbreaking approach.
A RAG workflow builds on large language models (LLMs), which can understand queries and generate responses. However, LLMs have limitations, including training complexity and a lack of current (sometimes proprietary) information. Also, they tend to hallucinate and synthesize factually incorrect information when not trained on specific data to answer the prompt. RAG helps to overcome these limitations by augmenting queries with enterprise-specific information provided to the LLM.
In this post, we discuss how RAG can empower businesses to create high-quality, relevant, and engaging content for various enterprise use cases. We dive into the technical challenges of scaling RAG to handle massive amounts of data and users and how to address them using a scalable architecture powered by NVIDIA GPU computing, accelerated Ethernet networking, network storage, and AI software.
RAG enables enterprises to capitalize on data
A typical RAG workflow uses a vector database, a class of data management system tailored for performing similarity searches, to store and retrieve enterprise-specific information related to the query.
By integrating RAG into their information systems, businesses can tap into vast amounts of internal and external data to generate insightful, up-to-date, contextually relevant content. This fusion is a significant leap forward, enabling enterprises to capitalize on their data and domain expertise, opening new avenues for personalized customer interactions, streamlined content creation, and more efficient knowledge use cases.
However, deploying RAG at enterprise scale comes with its own set of challenges, including the complexity of managing hundreds of data sets and thousands of users. This necessitates a distributed architecture capable of efficiently handling the processing and storage requirements of such a large-scale operation.
To scale this architecture, you must embed, vectorize, and index millions of documents, images, audio files, and videos, while also accommodating the embedding of newly created content every day.
Another challenge is ensuring low-latency responses for interactive, multimodal applications. With the need to integrate data enterprise apps and structured and unstructured data stores, there is a demand for real-time processing and response, which can be challenging to achieve at scale.
The indexing and storage of data for generative AI also pose a challenge.
While traditional enterprise apps can compress data and store it for efficient retrieval, to support indexing and semantic search, RAG-based databases can expand to more than 10x larger than the original text documents and their associated metadata. This leads to significant data growth and storage challenges.
To achieve optimal results, enterprises must invest in accelerated computing, networking, and storage infrastructure, which is essential for handling the large volumes of data required for training and deploying RAG models.
How to enable scalable and efficient RAG inference
At GTC 2024, NVIDIA launched a catalog of generative AI microservices that empower developers with enterprise-grade building blocks for creating and deploying custom AI applications.
Enterprises can use these microservices as a foundation to create RAG-powered applications. By combining them with NVIDIA RAG workflow examples, you can speed up the process of building and productizing generative AI applications.
In this post, we benchmark these RAG workflow examples using multi-node GPU compute inference, accelerated Ethernet networking, and network-connected storage. Our test results show that high-performance networking and network-connected storage enable efficient and scalable generative AI inferencing, empowering enterprises to develop RAG-powered applications that scale to thousands of users while facilitating continuous data processing.
Figure 1 shows a RAG workflow with two phases and data pipelines.
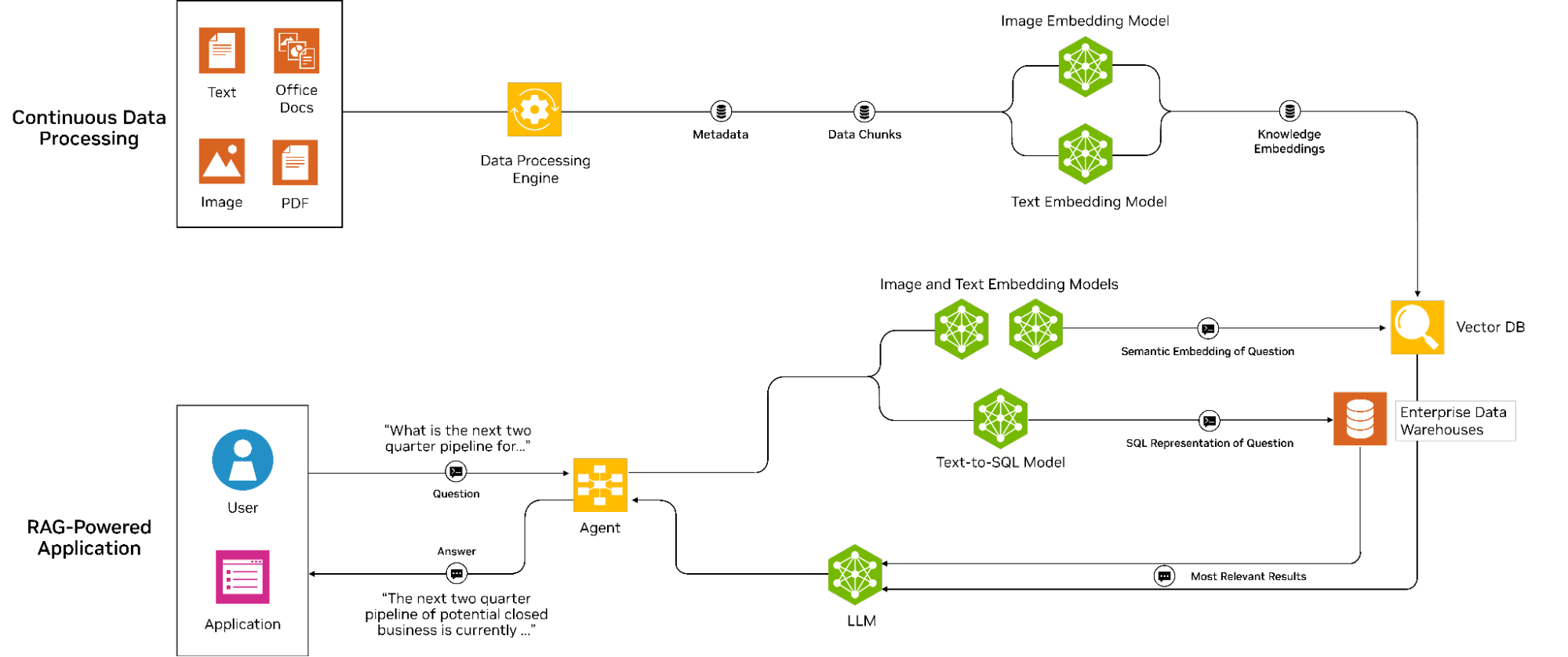
In the first phase, data ingestion converts documents and other data modalities into numerical embeddings, which are then indexed in a vector database. This process enables the efficient retrieval of relevant documents based on similarity scores.
The query phase begins when a user inputs a question, which is also converted into an embedding and used to search the vector database for relevant content. After the relevant content is retrieved, it is passed to the LLM for further processing. The original input question along with the augmented context is provided to the LLM, which generates a more precise answer to the user’s query.
This workflow enables the effective retrieval and generation of information, making it a powerful tool for every manner of enterprise application.
Accelerated Ethernet networking, network-connected storage excel at data ingestion
We initially tested the data ingestion pipeline based on a single GPU node. Figure 2 shows the test setup with one DGX system that has 8x A100 GPUs, and a network-connected all-flash storage platform, designed for object storage workloads.
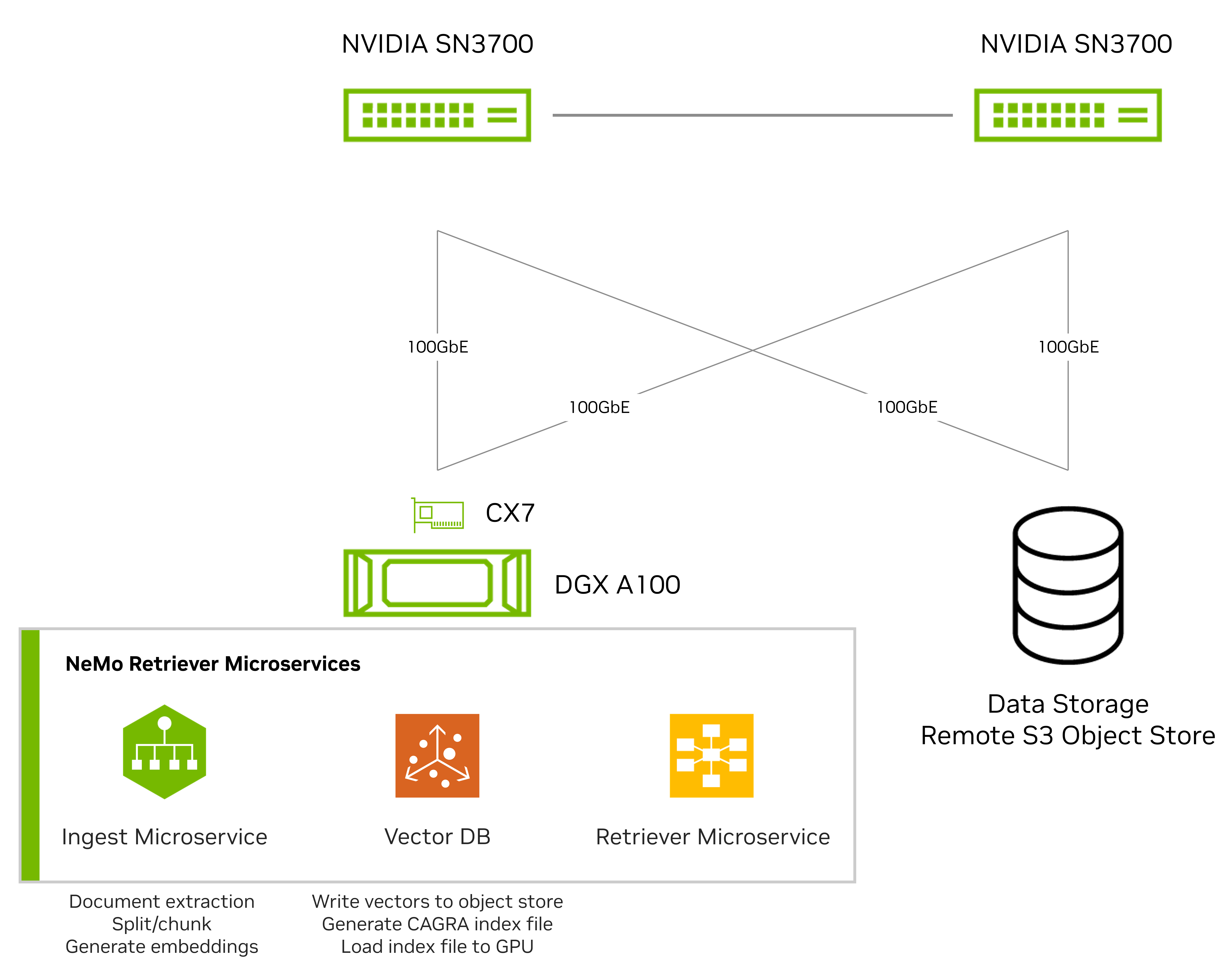
The DGX system connects to the network through an NVIDIA ConnectX-7 NIC, using the accelerated NVMe-over-Fabrics (NVMe-oF) and Amazon S3 object storage protocols, and two NVIDIA Spectrum SN3700 switches.
Using NeMo Retriever microservices, we compared the performance of embedding and indexing of PDF documents including text and images. This comparison involved directly attached storage (DAS) in the DGX system and network-connected storage.
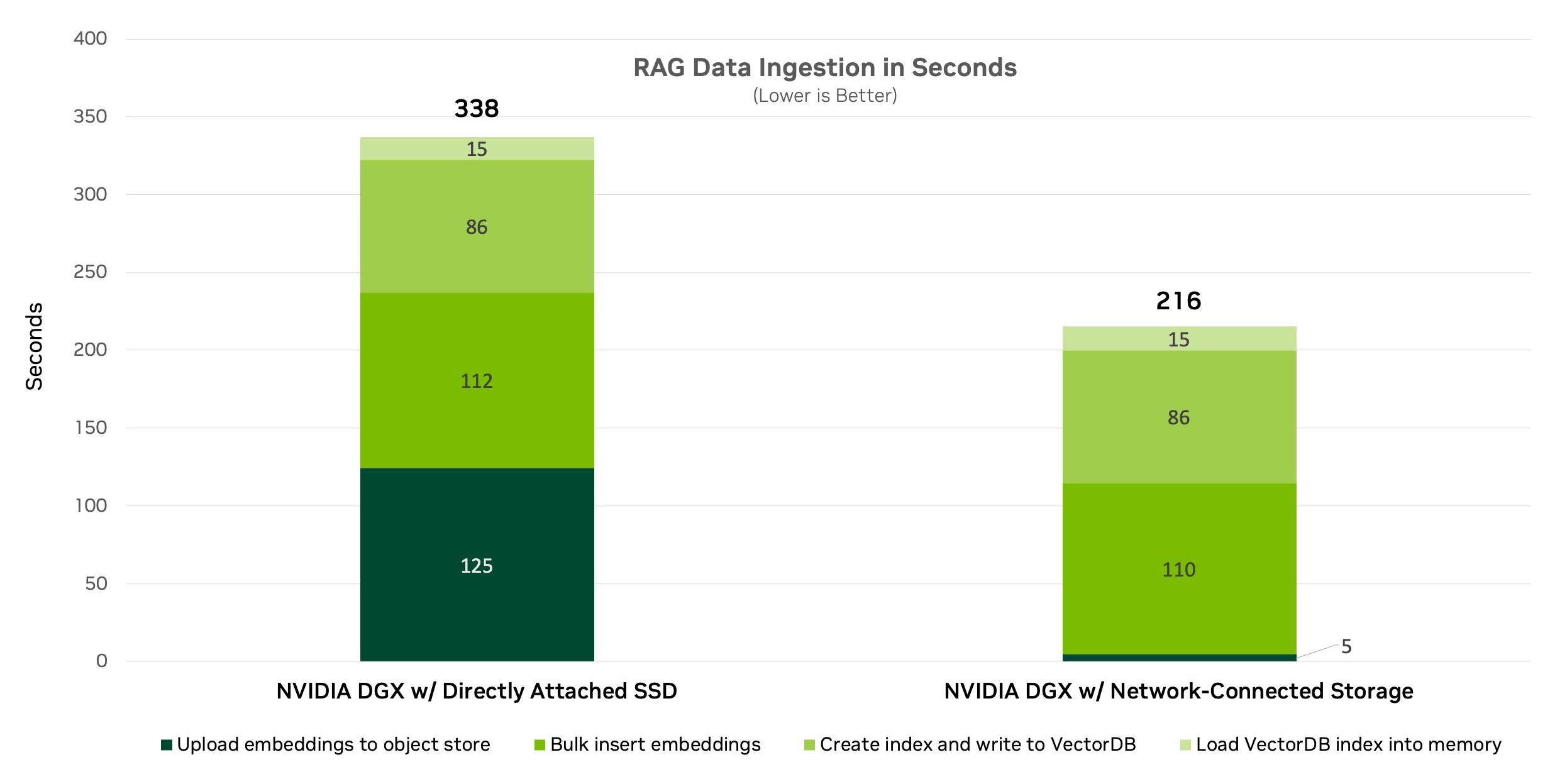
Figure 3 shows the outcomes of the data ingestion benchmark on a single node. It reveals that using network-connected storage with Amazon S3 accelerated data ingestion by 36% over using DAS, reducing the processing time by 122 seconds. This indicates that network-connected storage is a better choice for data ingestion, which also relies on the network speed and latency.
Accelerated Ethernet networking is essential to provide robust, performant, and secure connectivity. Besides enhancing document embedding, network-connected storage also provides various enterprise-level data management features.
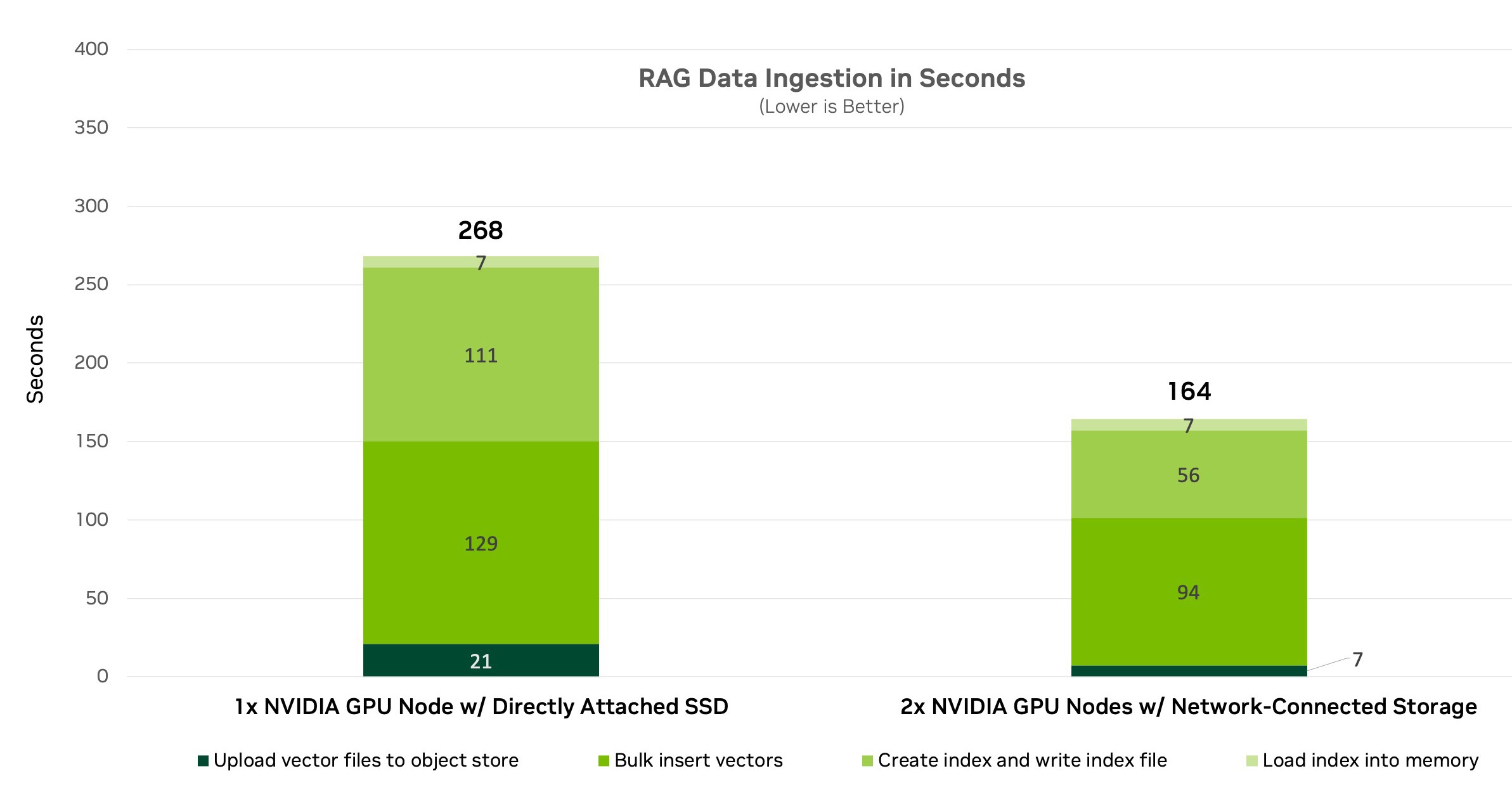
We then tested with a multi-node RAG setup that used a distributed microservices architecture connected through NVIDIA BlueField-3 DPUs (Figure 4). Performance scaled up as multiple nodes ran in parallel to upload embeddings, calculate the index, and insert to the vector database.
We compared the performance using directly attached SSDs in each server compared to network-connected storage. For the SSDs within the servers, MinIO acted as the object storage layer. With the network-connected storage, we bypassed MinIO and tested the storage system’s own native Amazon S3 object interface.
Results showed that multi-node delivered faster performance than using a single node, reducing the processing time by almost 102 seconds. These results attest to the performance advantages of multi-node GPU acceleration combined with enterprise-class network-connected storage.
Advantages of network-connected storage for RAG-powered applications
Network-connected storage enables access to blocks, files, and objects over a network, instead of directly connecting storage media to a server.
Network-connected storage not only provides clear performance advantages for RAG-based applications, but also offers additional enterprise benefits, making it the optimal data platform to enhance natural language processing.
Some benefits of network-connected storage for RAG workflows include the following:
- Real-time streaming data ingestion: Network-connected storage supports the ingestion of real-time streaming data from various sources, such as social media, web, sensors, or IoT devices. This data can be used by RAG applications to generate relevant and up-to-date content. DAS may not be able to handle the high volume and velocity of streaming data or may require additional processing or buffering to store the data.
- Scalability: It is easier to expand storage capacity with network-connected storage by adding more disks or devices without affecting performance or data availability. DAS, on the other hand, has limited scalability and may require downtime or reconfiguration for storage upgrades.
- Metadata annotation: Network-connected storage enables data annotation with metadata, such as tags, categories, keywords, or summaries. This metadata can be used by RAG applications to retrieve and rank data sources according to queries or context. DAS may not support data annotation or may require separate databases or indexes to store metadata.
- Utilization: Network-connected storage optimizes storage resource utilization by enabling multiple users and applications to access the same data simultaneously, without creating duplicates or conflicts. DAS may result in under– or overused storage, depending on demand and data allocation within a specific server.
- Reliability: Network-connected storage improves reliability and data availability by using advanced redundant array of independent disks (RAID) features, which are not available for DAS, or other methods to protect data from disk failures, network failures, or power outages. DAS may suffer data loss or corruption if a disk or server fails.
- De-duplication: Network-connected storage reduces storage space and network bandwidth by eliminating duplicate or redundant data across files or devices. DAS may store multiple copies of the same data, wasting storage space and network resources.
- Source citation for data provenance: Network-connected storage provides source citation for data, such as URL, author, date, or license. This information can be used by RAG applications to attribute and verify data sources and ensure the quality and credibility of generated content. DAS may not provide source citation for data or may require manual or external methods to track data provenance.
- Backup: Network-connected storage facilitates data backup and recovery by using snapshots, replication, or other methods to create copies of data on different locations or devices. DAS may require manual or complex backup procedures, which can be time-consuming or erro-prone.
- Data protection and retention: Network-connected storage ensures data protection and retention by using encryption, compression, or other techniques to secure data from unauthorized access or modification. It also uses policies, rules, or regulations to manage the data lifecycle, such as the creation, deletion, or archiving of data. DAS may not provide data protection and retention or may require additional software or hardware to implement data security and governance.
Conclusion
Retrieval-augmented generation holds immense potential for enterprises to capitalize on data by harnessing the power of generative AI augmented with enterprise-specific context and information.
However, deploying RAG at scale presents challenges such as managing large datasets, ensuring low latency for interactive applications, and addressing the storage requirements of generative AI.
To overcome these challenges, enterprises must scale their RAG-based generative AI infrastructure. To perform efficiently, this infrastructure must be properly sized and architected across the entire data center stack: accelerated computing, fast networking, network-connected storage, and enterprise AI software.
Generative AI is a new and fast-growing field. As RAG expands to support new modalities such as video, data processing needs continue to grow rapidly. NVIDIA generative AI microservices, combined with multi-node NVIDIA GPU compute inference, accelerated Ethernet networking, and network-connected storage, demonstrate efficient RAG inferencing at enterprise scale.
To learn more about how to scale your RAG-based generative AI applications, don’t miss NVIDIA GTC 2024:
- Enabling Enterprise Generative AI with Optimized Ethernet AI Networking NVIDIA GTC session
- All Retrieval-Augmented Generation GTC sessions
You can experience the sessions in-person by registering for NVIDIA GTC or access the session on-demand.
