Every year, as part of their coursework, students from the University of Warsaw, Poland get to work under the supervision of engineers from the NVIDIA Warsaw office on challenging problems in deep learning and accelerated computing. We present the work of three M.Sc. students—Alicja Ziarko, Paweł Pawlik, and Michał Siennicki—who managed to significantly reduce the latency in TorToiSe, a multi-stage, diffusion-based, text-to-speech (TTS) model.
Alicja, Paweł, and Michał first learned about the recent advancements in speech synthesis and diffusion models. They chose the combination of classifier-free guidance and progressive distillation, which performs well in computer vision, and adapted it to speech synthesis, achieving a 5x reduction in diffusion latency without a regression in speech quality. Small perceptual speech tests confirmed the results. Notably, this approach does not require costly training from scratch of the original model.
Why speed up diffusion-based TTS?
Since the publication of WaveNet in 2016, neural networks have become the primary models for speech synthesis. In simple applications, such as synthesis for AI-based voice assistants, synthetic voices are almost indistinguishable from human speech. Such voices can be synthesized orders of magnitudes faster than real time, for instance with the NVIDIA NeMo AI toolkit.
However, achieving high expressivity or imitating a voice based on a few seconds of recorded speech (few-shot) is still considered challenging.
Denoising Diffusion Probabilistic Models (DDPMs) emerged as a generative technique that enables the generation of images of great quality and expressivity based on input text. DDPMs can be readily applied to TTS because a frequency-based spectrogram, which graphically represents a speech signal, can be processed like an image.
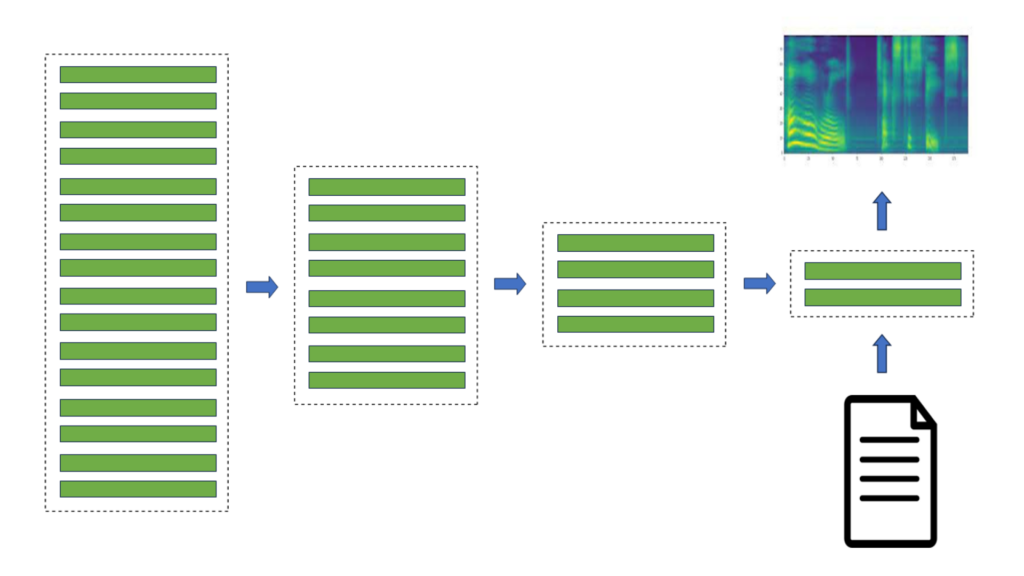
For instance, in TorToiSe, which is a guided diffusion-based TTS model, a spectrogram is generated by combining the results of two diffusion models (Figure 1). The iterative diffusion process involves hundreds of steps to achieve a high-quality output, significantly increasing latency compared to state-of-the-art TTS methods, which severely limits its applications.
In Figure 1, the unconditional diffusion model iteratively refines the initial noise until a high-quality spectrogram is obtained. The second diffusion model is further conditioned on the text embeddings produced by the language model.
Methods for speeding up diffusion
Existing latency reduction techniques in diffusion-based TTS can be divided into training-free and training-based methods.
Training-free methods do not involve training the network used to generate images by reversing the diffusion process. Instead, they only focus on optimizing the multi-step diffusion process. The diffusion process can be seen as solving ODE/SDE equations, so one way to optimize it is to create a better solver like DDPM, DDIM, and DPM, which lowers the number of diffusion steps. Parallel sampling methods, such as those based on Picard iterations or Normalizing Flows, can parallelize the diffusion process to benefit from parallel computing on GPUs.
Training-based methods focus on optimizing the network used in the diffusion process. The network can be pruned, quantized, or sparsified, and then fine-tuned for higher accuracy. Alternatively, its neural architecture can be changed manually or automatically using NAS. Knowledge distillation techniques enable distilling the student network from the teacher network to reduce the number of steps in the diffusion process.
Distillation in diffusion-based TTS
Alicja, Paweł, and Michał decided to use the distillation approach based on promising results in computer vision and its potential for an estimated 5x reduction in latency of the diffusion model at inference. They have managed to adapt progressive distillation to the diffusion part of a pretrained TorToiSe model, overcoming problems like the lack of access to the original training data.
Their approach consists of two knowledge distillation phases:
- Mimicking the guided diffusion model output
- Training another student model
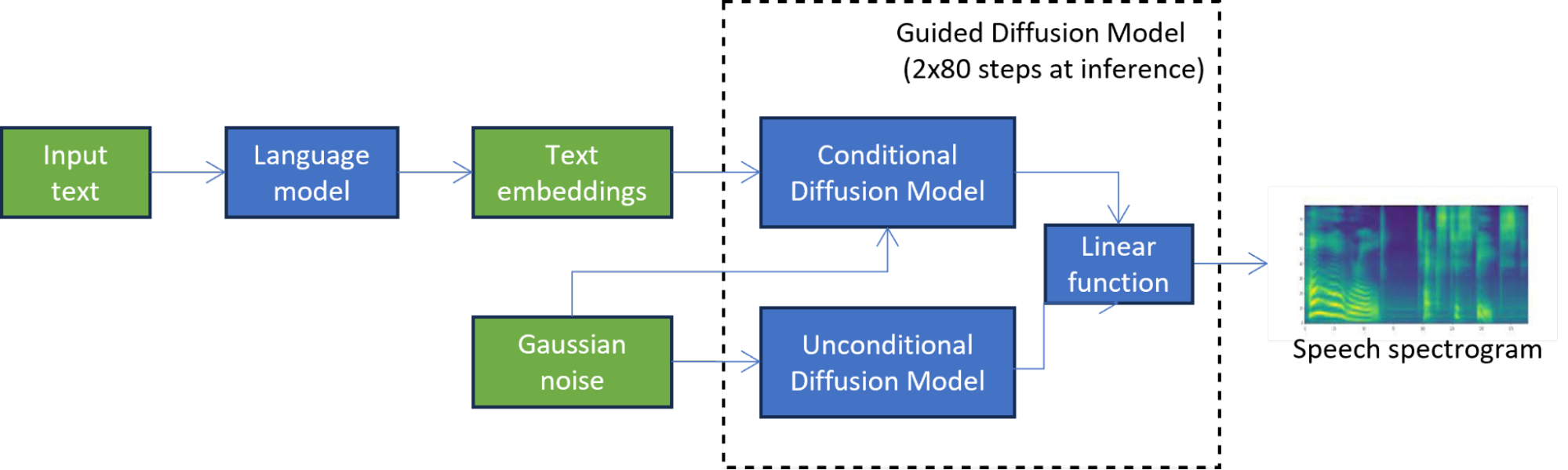
In the first knowledge distillation phase (Figure 2), the student model is trained to mimic the output of the guided diffusion model at each diffusion step. This phase reduces latency by half by combining the two diffusion models into one model.
To address the lack of access to the original training data, text embeddings from the language model are passed through the original teacher model to generate synthetic data used in distillation. The use of synthetic data also makes the distillation process more efficient because the entire TTS, guided diffusion pipeline does not have to be invoked at each distillation step.
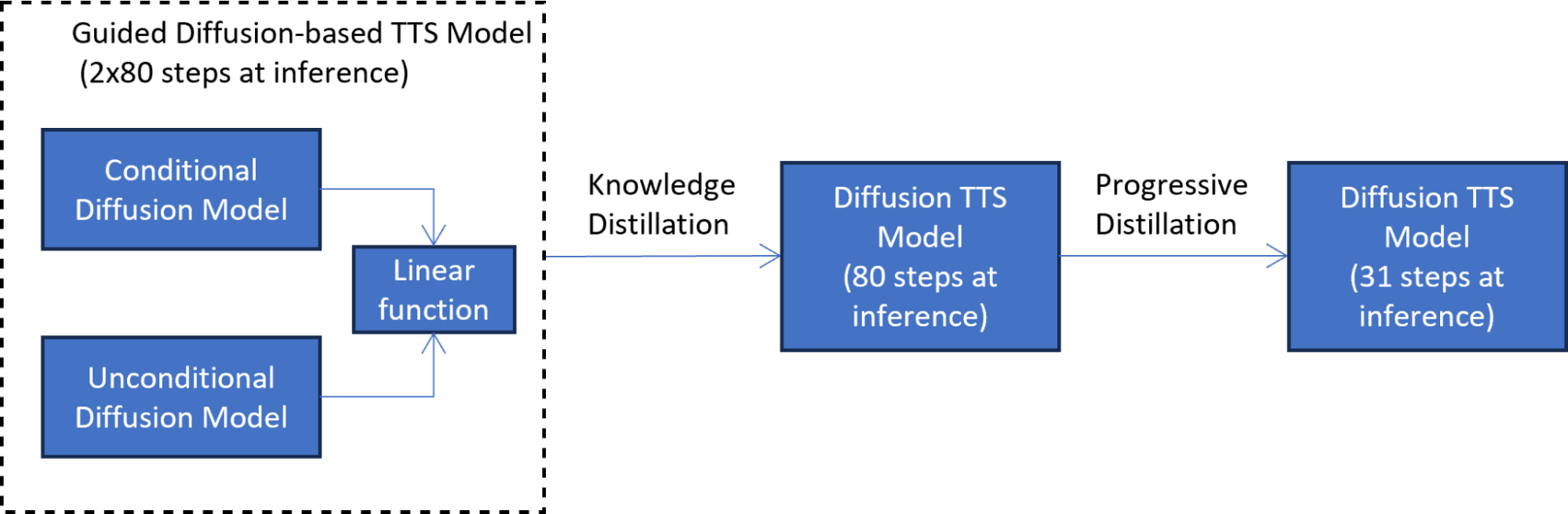
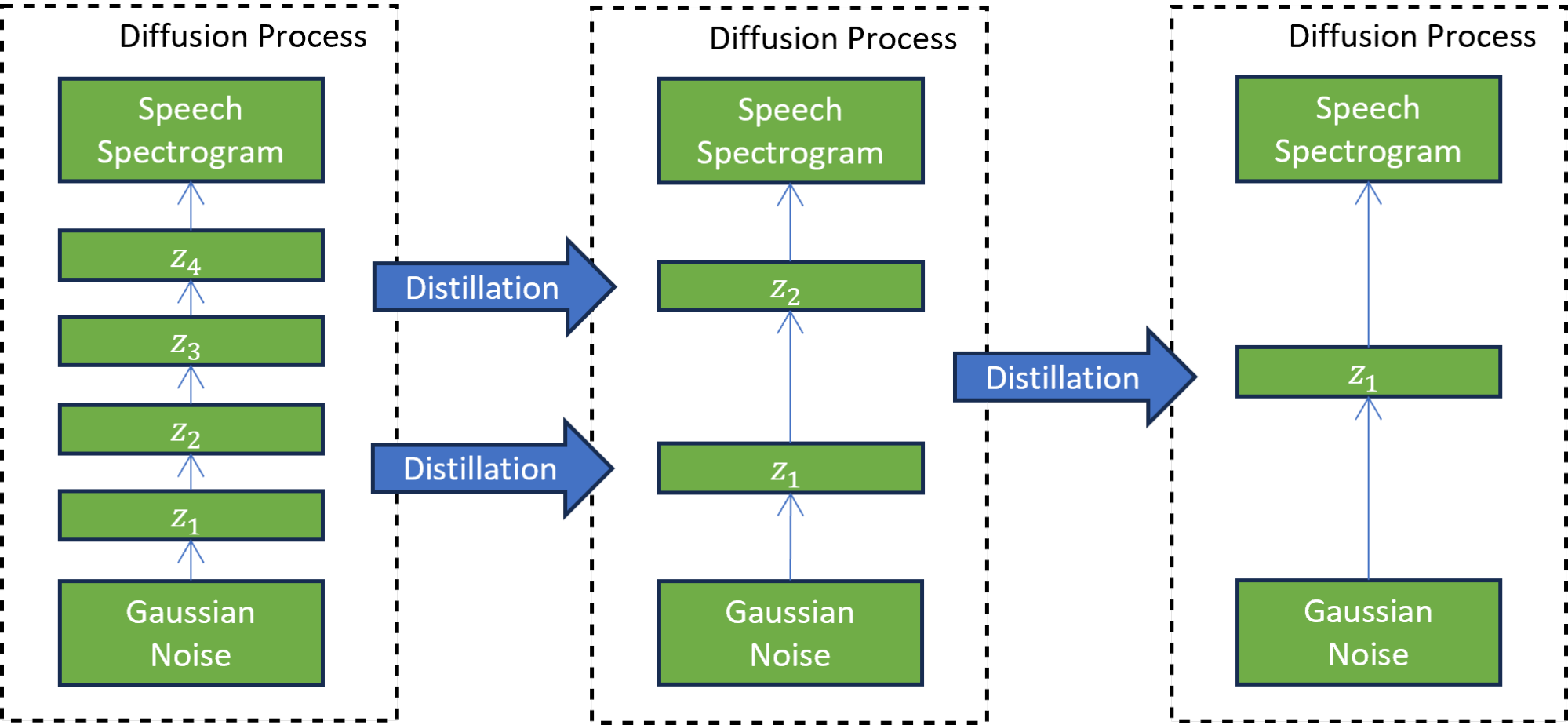
In the second progressive distillation phase (Figure 3), the newly trained student model serves as a teacher to train another student model. In this technique, the student model is trained to mimic the teacher model while reducing the number of diffusion steps by a factor of two. This process is repeated many times to further reduce the number of steps, while each time, a new student serves as the teacher for the next round of distillation.
A progressive distillation with seven iterations reduces the number of inference steps 7^2 times, from 4,000 steps on which the model was trained to 31 steps. This reduction results in a 5x speedup compared to the guided diffusion model, excluding the text embedding calculation cost.
The perceptual pairwise speech test shows that the distilled model (after the second phase) matches the quality of speech produced by the TTS model based on guided distillation.
As an example, listen to audio samples in Table 1 generated by the progressive distillation-based TTS model. The samples match the quality of the audio samples from the guided diffusion-based TTS model. If we simply reduced the number of distillation steps to 31, instead of using progressive distillation, the quality of the generated speech deteriorates significantly.
Speaker | Guided diffusion-based TTS model (2×80 diffusion steps) | Diffusion-based TTS after progressive distillation (31 diffusion steps) | Guided diffusion-based TTS model (naive reduction to 31 diffusion steps) |
|---|---|---|---|
| Female 1 | Audio | Audio | Audio |
| Female 2 | Audio | Audio | Audio |
| Female 3 | Audio | Audio | Audio |
| Male 1 | Audio | Audio | Audio |
Conclusion
Collaborating with academia and assisting young students in shaping their future in science and engineering is one of the core NVIDIA values. Alicja, Paweł, and Michał’s successful project exemplifies the NVIDIA Warsaw, Poland office partnership with local universities.
The students managed to solve the challenging problem of speeding up the pretrained, diffusion-based, text-to-speech (TTS) model. They designed and implemented a knowledge distillation-based solution in the complex field of diffusion-based TTS, achieving a 5x speedup of the diffusion process. Most notably, their unique solution based on synthetic data generation is applicable to pretrained TTS models without access to the original training data.
We encourage you to explore NVIDIA Academic Programs and try out the NVIDIA NeMo Framework to create complete conversational AI (TTS, ASR, or NLP/LLM) solutions for the new era of generative AI.