

The artificial production of human speech, also known as speech synthesis, has always been a fascinating field for researchers, including our AI team at Axel Springer SE. For a long time, people have worked on creating text-to-speech (TTS) systems that reach human level. Following the field’s transition to deep learning with the introduction of Google WaveNet in 2006, it has almost reached this goal.
Currently, TTS is gaining a lot of momentum in the research community. The technology is becoming more accessible through various open-source projects such as the ones from Mozilla, NVIDIA, or Espnet and also because of many public datasets such as LJ Speech or M-AILABS. Neural speech synthesis is an interesting deep learning field for researchers as it shares features from both natural language processing (NLP) and computer vision. It also covers many exciting research areas such as GANs, autoregressive flows, teacher-student networks, and seq2seq models with advanced attention mechanisms.
Although the domain is still dominated by the big tech companies, the growing market is far from exhausted. The potential applications range from chatbots to the automatization of audio content in news media. One obvious example of a TTS application for news media is a Read Aloud feature for a news article that makes it possible to listen while commuting. In fact, this feature is already offered by some newspapers, though they mainly use external TTS services to power their applications.
As Europe’s largest digital publisher, we decided to go one step further by building up our own technology in-house and creating a custom brand voice instead of relying on third-party providers. In this post, we give you a brief introduction into the mechanics of modern neural speech synthesis. We also share some insights about creating our own TTS technology called ForwardTacotron, a TTS solution that is specifically focused on robust and fast speech synthesis. In fact, we even open-sourced it. You can find the ForwardTacotron project on GitHub.
Here are two examples that you can achieve with the ForwardTacotron model:
Example 1: Here’s a paragraph read by a synthesized voice.
The artificial production of human speech, also known as speech synthesis, has always been a fascinating field for researchers, including our AI team at Axel Springer SE. For a long time, people have worked on creating text-to-speech (TTS) systems that reach human level. And since its transitioning to deep learning with the introduction of Google’s WaveNet in 2006, it has almost reached this goal.
You can also control the voice speed.
Example 2: Here’s a tongue-twister.
Peter Piper picked a peck of pickled peppers.
A peck of pickled peppers Peter Piper picked.
If Peter Piper picked a peck of pickled peppers,
Where’s the peck of pickled peppers Peter Piper picked?
For further samples, see the ForwardTacotron project page.
Modern TTS: Autoregressive end-to-end models
Back in 2006, Google WaveNet was the first neural network for TTS and it raised speech synthesis to a new level. In fact, the technology is still used in the Google Cloud API. The idea behind WaveNet is to predict the audio signal with an autoregressive convolutional network with many layers and various dilation rates. Autoregression means that for each prediction, the model is taking into account its previous predictions (Figure 1), which requires it to unroll the inference sequentially, slowing it down.

Researchers have found it hard to reproduce Google’s amazing results as the model seems to depend on subtle design choices and advanced text processing for feature generation that has not been made public.
Tacotron: An alternative approach
As a more accessible, alternative approach, Google also introduced an end-to-end TTS system, Tacotron, that can be trained on raw text and audio pair data with little preprocessing. The problem reduces to predicting spectrograms from text (often translated to phonemes), which then can be converted to an audio signal with a vocoder algorithm, such as Griffin-Lim, or a neural model, such as WaveRNN.
A spectrogram can be produced from an audio signal by sliding a short-term Fourier transformation over it. For voice processing, the spectrograms are usually normalized according to a mel frequency basis to make sounds of equal distance sound equally distant to the human ear, which is then called a mel spectrogram or mel. Figure 2 shows an example mel of a male utterance.
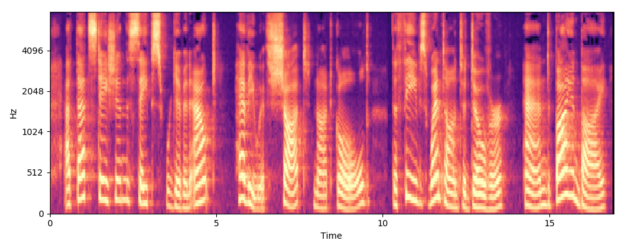
Clear patterns emerge that are specific to the voice and prosody of the speaker, which makes the mel spectrogram a good feature representation for deep learning. Predicting these mels from text is a classical seq2seq problem with some interesting particularities:
- First, the input text is much shorter than the target sequence.
- Second, there is a clear alignment from text to mel frames.
- Third, the target sequence is high-dimensional with a usual depth of 80.
Nevertheless, the model of choice for such a seq2seq problem is a classic attentive encoder-decoder network, which is the backbone of Tacotron.
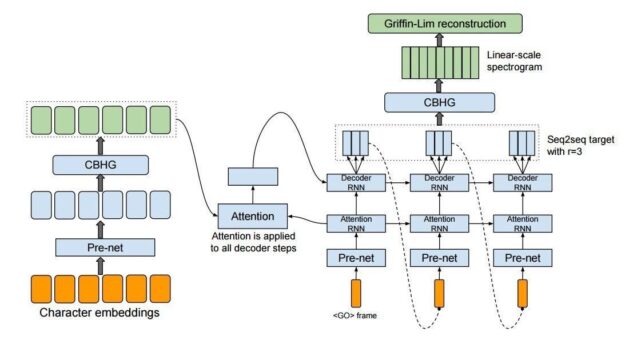
In a nutshell, Tacotron encodes the text (or phoneme) sequence with a stack of convolutions plus a recurrent network and then decodes the mel frames autoregressively with a large attentive LSTM. Figure 3 shows the exact architecture, which is well-explained in the original paper, Tacotron: Towards End-to-End Speech Synthesis.
Towards non-autoregressive TTS
Although autoregressive models work well for speech synthesis in terms of audio quality, they are slow due to the sequential inference of more than 100K steps for an utterance. Consequently, research has been dedicated to the development of non-autoregressive feed-forward models to speed up inference. Vocoders have been especially sped up by magnitudes using non-autoregressive methods based on knowledge distillation, flow-based generation, and GANs.
With fast, modern, non-autoregressive vocoders, the mel prediction is becoming the bottleneck of speech synthesis. Another problem with attention-based mel prediction models is the lack of controllability. That is, the voice speed and prosody of the generated voice is determined by the autoregressive generation.
To solve these problems, researchers from Microsoft proposed the first non-autoregressive mel prediction model, called FastSpeech. The researcher’s novel idea was to solve the alignment problem of phonemes and spectrogram by estimating for each phoneme how many mel frames should be predicted. This is handled by a separate duration predictor module that is trained on ground truth phoneme durations. These durations can be extracted from the attention alignments of an already trained autoregressive model. At inference time, the FastSpeech model uses its trained duration predictor to expand each phoneme accordingly so that the full mel spectrogram can be generated in a single forward pass of all layers.
For more information, see FastSpeech: Fast, Robust and Controllable Text to Speech.
ForwardTacotron
The original FastSpeech model consists of 12 self-attentive transformer layers, which can be memory consuming. For self-attention, the space complexity goes with the square of sequence length. To remove this complexity, we re-implemented the main idea using the recurrent Tacotron architecture without its autoregressive attentive part, so that it can predict mels in a single forward pass (Figure 4). We called the model ForwardTacotron because it combines ideas from the FastSpeech paper with the Tacotron architecture.
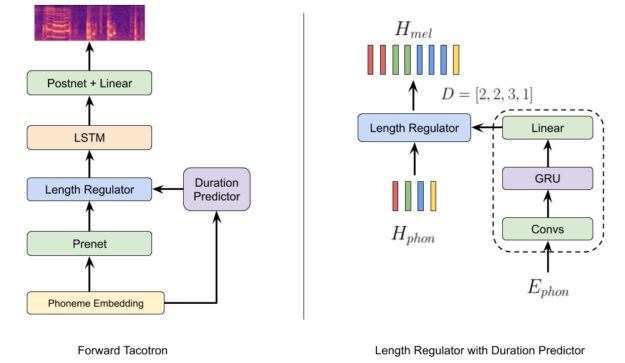
The key module is a length regulator borrowed from FastSpeech, which expands the phoneme embeddings according to the predicted duration. In contrast to FastSpeech, we decided to separate the duration predictor module from the rest of the model as it turned out to improve the mel quality. Due to the lack of attention, the memory requirement grows linearly with sequence length, which makes it possible to predict complete articles at one time with the model. Predictions are not only robust but fast. For example, the generation of a sentence takes 0.04s on an NVIDIA GeForce RTX 2080.
Another main difference to FastSpeech is that ForwardTacotron does not rely on knowledge distillation. This means that it is trained on the original mel targets and not on the predictions of the attentive model that extracts the durations. We use Tacotron purely as a duration extractor, which works well even when it is trained for relatively few steps.
Implementation and training
Because we wanted to shorten our time-to-development, we based our ForwardTacotron implementation on Fatchord’s Tacotron repository, which also contains a WaveRNN vocoder that produces high fidelity audio from the spectrograms. This sped up our development process immensely.
We also trained ForwardTacotron with the LJSpeech dataset on an NVIDIA Quadro RTX 8000. It took us 18 hours and 190K steps to produce a good model. You can find the model weights on the ForwardTacotron GitHub repo. We also provide a Colab Notebook with pretrained models to play around with. Of course, you can also use ForwardTacotron to train it on your own data. We provide detailed instructions to train your own model as well as some recommendations for training including proper monitoring, which is not included in the Fatchord implementation.
Future research directions
At Axel Springer AI, we do active research to further improve non-autoregressive speech synthesis. Some concrete ideas are to apply GANs to produce more realistic mels and to find simpler methods to extract the phoneme durations; for example, using a speech-to-text model.
Because the inference of ForwardTacotron is fast, the bottleneck of speech synthesis is the autoregressive WaveRNN vocoder. Thus, we are in the process of switching from WaveRNN to non-autoregressive vocoders, such as MelGAN. Such neural vocoders have been greatly improved recently and reach audio quality comparable to their autoregressive counterparts, while being orders of magnitudes faster. Other variants include parallel WaveNet, parallel WaveGAN, and WaveGlow.
Finally, an interesting research direction is to develop a non-autoregressive forward model without ad-hoc extraction of the attention alignments. The preliminary research looks interesting. For example, AlignTTS uses dynamic programming to find the attention alignments.
