Many of today’s speech synthesis models lack emotion and human-like expression. To help tackle this problem, a team of researchers from the NVIDIA Applied Deep Learning Research group developed a state-of-the-art model that generates more realistic expressions and provides better user control than previously published models.
Named “Flowtron”, the model debuted publicly for the first time as the narrator of the newly released I AM AI opening keynote video at GTC Digital 2020. The model is described in a preprint paper available on arXiv.
“The ability to generate speech that emulates human expression has been a long-time goal for speech synthesis models,” said Rafael Valle, Senior Research Scientist, who developed the model with fellow researchers Ryan Prenger and Kevin Shih. ”Flowtron brings us closer to this goal.”
The newly released model builds on the group’s previous paper “WaveGlow: A Flow-based Generative Network for Speech Synthesis.”
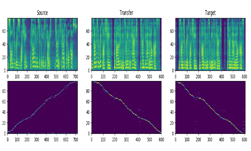
What makes Flowtron unique is its added capabilities for customization. The model allows users to influence speech variation and apply unique styles to voices through style transfer, similar to computer vision style transfer models. Unlike other models, Flowtron is optimized by maximizing the likelihood of the training data, which makes training simple and stable.
“Flowtron learns an invertible function that maps a distribution over speech characteristics (mel spectrograms) to a latent z-space parametrized by a simple distribution (Gaussian) and conditioned on an input text sample. With this formalization, we can generate samples containing specific speech characteristics manifested in mel-spectrogram-space by finding and sampling the corresponding region in z-space,” the researchers explained.
Invertible models like Flowtron can be easier to train, because they can learn the distribution of the real-world training data directly. As a result, the flow-based approach to text-to-spectrogram generation provides more realism and more expressivity than current state-of-the-art speech synthesis models. Flowtron achieves this by giving users control over non-textual characteristics, enabling them to make a monotonic speaker sound expressive.
“Flowtron produces expressive speech without labeled data or ever seeing expressive data during training,” Valle said. “In Mellotron, we added pitch and rhythm control, but it still lacked emotion, and we wanted to avoid collecting emotion labeled data.”
Training Flowtron took less than 48 hours with the cuDNN-accelerated PyTorch deep learning framework on a single NVIDIA DGX-1 with eight NVIDIA V100 GPUs.
The following audio samples demonstrate Flowtron’s ability to make a monotonic speaker sound expressive.
For developers interested in fine-tuning Flowtron to their own speakers, the researchers released pre-trained Flowtron models using the public LJ Speech and LibriTTS datasets.
“Flowtron pushes text-to-speech synthesis beyond the expressive limits of voice assistants,” Valle said. “It opens new avenues for speech synthesis in human-computer interaction and the arts, where realism and expressivity are essential.”
The researchers published their code in the NVIDIA/flowtron GitHub repo and more samples are available on the NVIDIA ADLR group page.
The NVIDIA Research team consists of more than 200 scientists around the globe, focusing on areas including AI, computer vision, audio, self-driving cars, robotics, and graphics.