
The CUDA 11.5 C++ compiler addresses a growing customer request. Specifically, how to reduce CUDA application build times. Along with eliminating unused kernels, NVRTC and PTX concurrent compilation help address this key CUDA C++ application development concern.
The CUDA 11.5 NVCC compiler now adds support for Clang 12.0 as a host compiler. We have also included a limited preview release of 128-bit integer support, which is becoming essential in high-fidelity computations.
This technical walkthrough on the CUDA C++ compiler toolchain complements the CUDA Programming Guide and provides a broad overview of new features being introduced in the CUDA 11.5 toolkit release.
NVRTC concurrent compilation
NVRTC compilation proceeds through three main stages:
Parser -> NVVM optimizer -> PTX CompilerSome of these stages are not thread-safe, so NVRTC would previously serialize concurrent compilation requests from multiple user-threads using a global lock.
In CUDA 11.5, the NVRTC implementation was enhanced to provide partially concurrent compilation support. This is done by removing the global lock and using per-stage locks, leading to different threads to be concurrently executing different stages of the compilation pipeline.
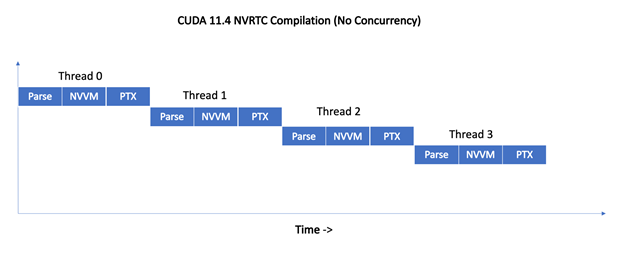
Figure 1 shows how NVRTC, before CUDA 11.5, serializes simultaneous compilation requests from four threads.
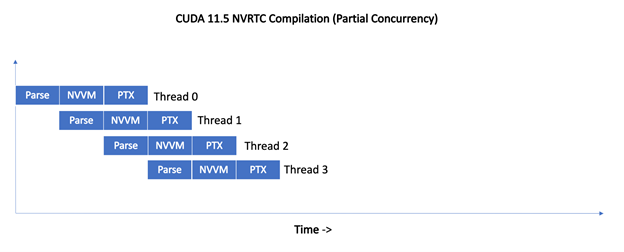
With 11.5, NVRTC does not serialize compilation requests. Instead, the compilation requests from different threads are pipelined, enabling different stages of the compilation pipeline to proceed concurrently.
The graph in Figure 3 shows the total compilation time for compiling a set of 100 identical sample NVRTC programs, split over the available number of threads.
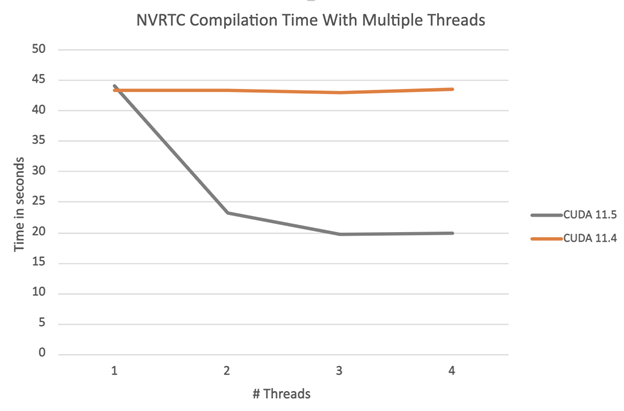
As expected, with CUDA 11.4 NVRTC, the total compilation time does not change as the number of threads increases, while compilation is serialized with a global NVRTC lock. With CUDA 11.5 NVRTC, the total compilation time is reduced as the number of threads increases. We will continue to make individual stage threads safer, which should enable nearly linear speedup for this example.
PTX concurrency compilation
PTX compilation along the JIT compilation path, as well as, using the PTX static library, proceeds through multiple internal phases. The previous implementation of these phases did not guarantee concurrent compilation from multiple threads. Instead, the PTX compiler used a global lock to serialize concurrent compilations.
In CUDA 11.5 and the R495 driver, the PTX compiler implementation now uses finer-grained local locks, rather than a global lock. This enables concurrent execution of multiple compilation requests, and significantly improves compilation time.
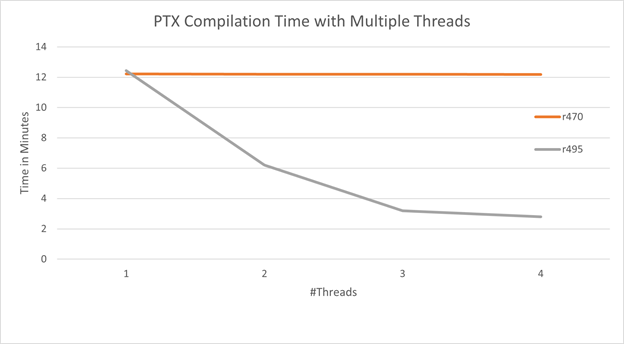
The following graph shows the total compilation time for compiling 104 identical sample programs split over a given number of threads through cuLinkAddData with CU_JIT_INPUT_PTX as CUjitInputType.
As expected with the R470 CUDA driver, the total compilation time does not change as the number of threads increase as compilation is serialized with a global lock. With the R495 CUDA driver, the total compilation time reduces as the number of threads increases.
Eliminating unused kernels
Separate compilation mode enables CUDA kernel functions and device functions to be shipped as CUDA device code libraries and be linked against any user application using nvlink, the device linker. The generated device program is then loaded and executed on the GPU at run time.
Before CUDA 11.5, nvlink could not determine whether it was safe to remove unused kernels from the linked device program, as these kernel functions could be referenced from host code.
Consider a library that defines four kernel functions:
//library.cu
__global__ void AAA() { /* code */ }
__global__ void BBB() { /* code */ }
__global__ void CCC() { /* code */ }
__global__ void DDD() { /* code */ }The library is built and shipped:
$nvcc -rdc=true library.cu -lib -o testlib.aThe user code refers to a single kernel from the library:
//user.cu
extern __global__ void AAA();
int main() { AAA<<<1,1>>>(); }The code is linked:
$nvcc -rdc=true user.cu testlib.a -o userWith CUDA 11.4 for instance, the linked device program would contain all four kernel bodies, even though only a single kernel (‘AAA’) is used in the linked device program. This can be burdensome for applications linking against larger libraries.
Increased binary sizes and application load times are not the only problems with redundant device code. When using device link time optimization, unused kernels not removed before optimization can lead to longer build times, and potentially impede code optimizations.
With CUDA 11.5, the CUDA compiler will track references to kernels from host code, and propagate this information to the device linker (nvlink). nvlink then removes the unused kernels from the linked device program. For the previous example, the unused kernels BBB, CCC, and DDD will get eliminated from the linked device program.
In CUDA 11.5, this optimization is disabled by default, but can be enabled by adding the -Xnvlink -use-host-info option to the NVCC command line:
$nvcc -rdc=true user.cu testlib.a -o user -Xnvlink -use-host-infoIn subsequent CUDA toolkit releases, the optimization will be enabled by default, and an opt-out flag will be provided.
Here are some caveats. In CUDA 11.5, the compiler analysis for kernel references will be conservative for the following scenarios. The compiler may consider some kernels that are not actually referenced from host code as referenced:
- If a template instantiation is referenced from host code, all instances of the template are considered as referenced from host code.
template<typename T>
__global__ void foo() { }
__device__ void doit() { foo<void><<<1,1>>>(); }
int main() {
// compiler will mark all instances of foo template as referenced
// from host code, including "foo<void>", which is only actually
// referenced from device code
foo<int><<<1,1>>>();
}- Any reference outside the body of a
__global__ or __device__function is considered as a host code reference.
__global__ void foo() { }
__device__ auto *ptr = foo; // foo is considered as referenced
// from host code.- When a reference to a function is template-dependent, all kernels with that name are considered host referenced.
__global__ void foo(int) { }
namespace N1 {
template <typename T>
__global__ void foo(T) { }
}
template<typename T>
void doit() {
// the reference to 'foo' is template dependent, so
// both ::foo and all instances of ::N1::foo are
// considered as referenced from host code.
foo<<<1,1>>>(T{});
}Another caveat, is that when the device link step is deferred to host application startup (JIT linking), instead of at build time, unused kernels will not be removed.
// With nonvirtual architecture (sm_80), NVLink is invoked
// at build time, and kernel pruning will occur.
$nvcc -Xnvlink -use-host-info -rdc=true foo.cu bar.cu -o foo -arch sm_80
// With virtual architecture (compute_80), NVLink is not invoked
// at build time, but only during host application startup.
// kernel pruning will not occur.
$nvcc -Xnvlink -use-host-info -rdc=true foo.cu bar.cu -o foo -arch compute_80In CUDA 11.5, nvlink does not yet use the information about unused kernels during device link time optimization. Our goal is to enable nvlink to use this information to delete unused kernels, reduce optimizer time, and improve generated code quality by reducing code bloat.
Limited 128-bit integer support
The 11.5 CUDA C++ compiler has support for 128-bit integer data types for platforms where the host compiler supports 128-bit integers. Basic arithmetic, logical and bitwise operations would work on 128-bit integers. Support for 128-bit integer variants of CUDA math intrinsics and CUDA math functions are planned for future releases.
Similarly, debug support for 128-bit integers and integration with developer tools will be in a subsequent release. For now, we are seeking your early feedback on this preview feature on the Developer Forum.
NVRTC static library
CUDA 11.5 provides a static version of the NVRTC library. Some applications may prefer to link against the static NVRTC library to guarantee stable performance and functionality during deployment. Static library users will also want to statically link-in the static versions of the NVRTC built-in library and the PTX compiler library. For more information about linking the static NVRTC library, see the NVRTC User Guide.
__builtin_assume
CUDA 11.5 improves code generation for loads and stores when __builtin_assume is applied to the results of address space predicate functions such as __isShared(pointer). For other supported functions, see Address Space Predicate Functions.
Without an address space specifier, the compiler generates generic load and store instructions, which requires a few extra instructions to compute the specific memory segment before performing the actual memory operation. Using __builtin_assume(expr) hints the compiler with the address space of generic pointers potentially improving the performance of the code.
Correct Usage:
bool b = __isShared(ptr);
__builtin_assume(b); // OK: Proof that ptr is a pointer to shared memory
Incorrect Usage:
These hints are ignored unless the boolean expression is stored in a separate variable:
__builtin_assume(__isShared(ptr)); // IGNOREDAs with other __builtin_assume, if the expression is not TRUE, then the behavior is undefined. If you are interested in learning more about __builtin_assume, see the CUDA 11.2 Compiler post.
Pragma diagnostic control
In CUDA 11.5, the NVCC CUDA compiler frontend has added support for numerous pragmas that offer more control over diagnostic messages.
You can use the following pragmas to control the compiler diagnostics for specific error numbers:
#pragma nv_diag_suppress // suppress the specified diagnostic
// message
#pragma nv_diag_warning // make the specified diagnostic a warning
#pragma nv_diag_error // make the specified diagnostic an error
#pragma nv_diag_default // restore the specified diagnostic level
// to default
#pragma nv_diag_once // only report the specified diagnostic once
Uses of these pragmas have the following form:
#pragma nv_diag_xxx error_number, error_number …To learn how to use these pragmas with more detailed caveats, see the CUDA Programming guide. The following example suppresses the “declared but never referenced” warning on the declaration of foo:
#pragma nv_diag_suppress 177
void foo()
{
int xxx=0;
}The pragmas nv_diagnostic push and nv_diagnostic pop may be used to save and restore the current diagnostic pragma state:
#pragma nv_diagnostic push
#pragma nv_diag_suppress 177
void foo()
{
int xxx=0;
}
#pragma nv_diagnostic pop
void bar()
{
int xxx=0;
}None of these pragmas have any effect on the host compiler.
Deprecation note: Diagnostic pragmas without the nv_ prefix have been deprecated. For example, #pragma diag_suppress support will be removed from all future releases. Using these diagnostic pragmas will elicit warning messages like this:
pragma "diag_suppress" is deprecated, use "nv_diag_suppress" insteadThe macro __NVCC_DIAG_PRAGMA_SUPPORT__ can facilitate the transition to the use of the new macros:
#ifdef __NVCC_DIAG_PRAGMA_SUPPORT__
#pragma nv_diag_suppress 177
#else
#pragma diag_suppress 177
#endifNew option -arch=all|all-major
Before the CUDA 11.5 release, if you wanted to generate code for all supported architectures, you had to list all the targets in --generate-code options. If a newer version is added, or an old version is retired, the --generate-code options must be changed accordingly. Now the new option -arch=all|all-major provides a simpler and efficient way to do the same.
If -arch=all is specified, NVCC embeds a compiled code image for all supported architectures (sm_*), and a PTX program for the highest major virtual architecture.
If -arch=all-major is specified, NVCC embeds a compiled code image for all supported major versions (sm_*0), starting from the earliest supported sm_x architecture (sm_35 for this release), and a PTX program for the highest major virtual architecture.
For example, a simple -arch=all option is equivalent to the following long list of options for this release:
-gencode arch=compute_35,\"code=sm_35\"
-gencode arch=compute_37,\"code=sm_37\"
-gencode arch=compute_50,\"code=sm_50\"
-gencode arch=compute_52,\"code=sm_52\"
-gencode arch=compute_53,\"code=sm_53\"
-gencode arch=compute_60,\"code=sm_60\"
-gencode arch=compute_61,\"code=sm_61\"
-gencode arch=compute_62,\"code=sm_62\"
-gencode arch=compute_70,\"code=sm_70\"
-gencode arch=compute_72,\"code=sm_72\"
-gencode arch=compute_75,\"code=sm_75\"
-gencode arch=compute_80,\"code=sm_80\"
-gencode arch=compute_86,\"code=sm_86\"
-gencode arch=compute_87,\"code=sm_87\"
-gencode arch=compute_80,\"code=compute_80\"A simple -arch=all-major option is equivalent to the following long list of options for this release:
-gencode arch=compute_35,\"code=sm_35\"
-gencode arch=compute_50,\"code=sm_50\"
-gencode arch=compute_60,\"code=sm_60\"
-gencode arch=compute_70,\"code=sm_70\"
-gencode arch=compute_80,\"code=sm_80\"
-gencode arch=compute_80,\"code=compute_80\"For all supported virtual architectures, see the Virtual Architecture Feature List. For all supported real architectures, see the GPU Feature List.
Deterministic code generation
In previous CUDA toolkits, the mangled name of an internal linkage variable or function in device code changes on every nvcc invocation, even if there was no change to the source code. Certain software management and build systems check whether the generated program bits have changed. The prior nvcc compiler behavior caused such systems to trigger and incorrectly assume that there was a semantic change in the source program; for example, potentially triggering redundant dependent builds.
The NVCC compiler behavior has been changed to be deterministic in CUDA 11.5. For example, consider this test case:
//--
static __device__ void foo() { }
auto __device__ fptr = foo;
int main() { }
//--With CUDA 11.4, compiling the same program twice generates slightly different names in the PTX:
//--
$cuda-11.4/bin/nvcc -std=c++14 -rdc=true -ptx test.cu -o test1.ptx
$cuda-11.4/bin/nvcc -std=c++14 -rdc=true -ptx test.cu -o test2.ptx
$diff -w test1.ptx test2.ptx
13c13
< .func _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv
---
> .func _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv
16c16
< .visible .global .align 8 .u64 fptr = _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv;
---
> .visible .global .align 8 .u64 fptr = _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv;
18c18
< .func _ZN57_INTERNAL_39_tmpxft_00000a46_00000000_7_test_cpp1_ii_main3fooEv()
---
> .func _ZN57_INTERNAL_39_tmpxft_00000a4e_00000000_7_test_cpp1_ii_main3fooEv()
$
//--With CUDA 11.5, compiling the same program twice generates identical PTX:
//--
$nvcc -std=c++14 -rdc=true -ptx test.cu -o test1.ptx
$nvcc -std=c++14 -rdc=true -ptx test.cu -o test2.ptx
$diff -w test1.ptx test2.ptx
$
//--Conclusion
Learn more about the CUDA 11.5 Toolkit by reading the Revealing New Features in the CUDA 11.5 Toolkit post. To exploit the new compiler toolchain features covered in this post, download and use the CUDA 11.5 Toolkit.
Provide us your feedback on the Developer Forum, specifically which of these features were the most important to you and why. Let us know if you are able to leverage the concurrent compilation support in NVRTC and PTX for your existing code base. Contact us to share other improvements that you would like to see in future CUDA toolkit releases.