
CUDA 8 is one of the most significant updates in the history of the CUDA platform. In addition to Unified Memory and the many new API and library features in CUDA 8, the NVIDIA compiler team has added a heap of improvements to the CUDA compiler toolchain. The latest CUDA compiler incorporates many bug fixes, optimizations and support for more host compilers.
In this post we’ll take you on a tour of some of the new and improved features in CUDA C++ and the NVCC compiler.
Compile Time Improvements
Compiler performance is, in our opinion, the most important CUDA 8 compiler feature, because it’s something that will affect every developer. We implemented various optimizations such as refactoring texture support and aggressively eliminating dead code early in compilation. This results in NVCC compiling less code, and thus compilation takes less time and produces smaller binaries in general.
How much has the compile time improved? Figure 1 shows the compile time speedups for CUDA 8 for the following small “Hello World” program.
#include <cstdio>
__global__ void foo(void) { printf("Hello World!"); }
int main(void) { foo<<<1,1>>>(); cudaDeviceSynchronize(); return 0; }
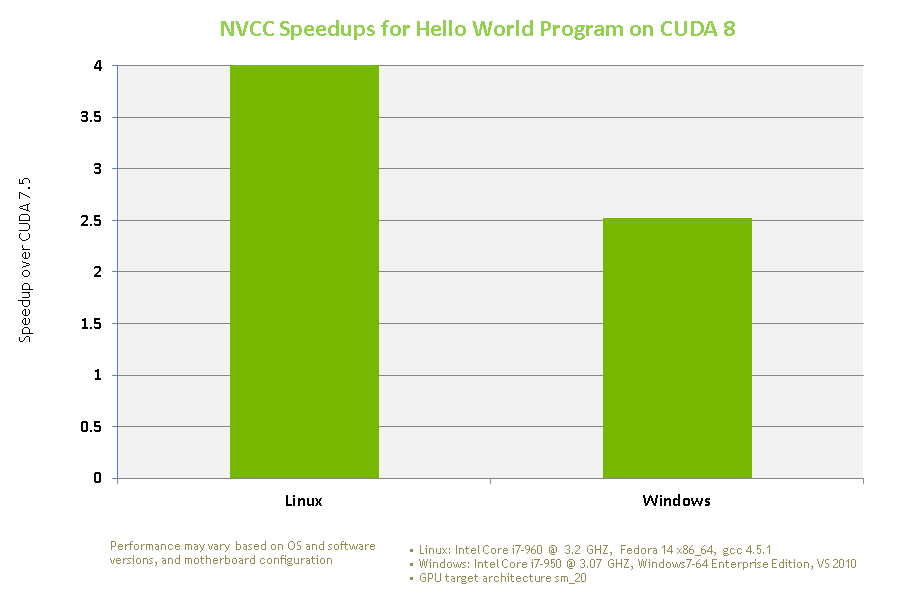
We see that the compile time for small “Hello World” like programs has improved dramatically in CUDA 8 compared to CUDA 7.5.
We also enhanced the template processing in the compiler front end to run more efficiently. This is particularly effective on modern C++ codes like Thrust and Eigen which use templates extensively. The end result is a much faster compiler, so you don’t have to be blocked waiting for the compiler to process your programs! Figure 2 shows that the compile time improvement impacts large real-world programs as well. Note especially the large improvement in template heavy codes like Thrust.
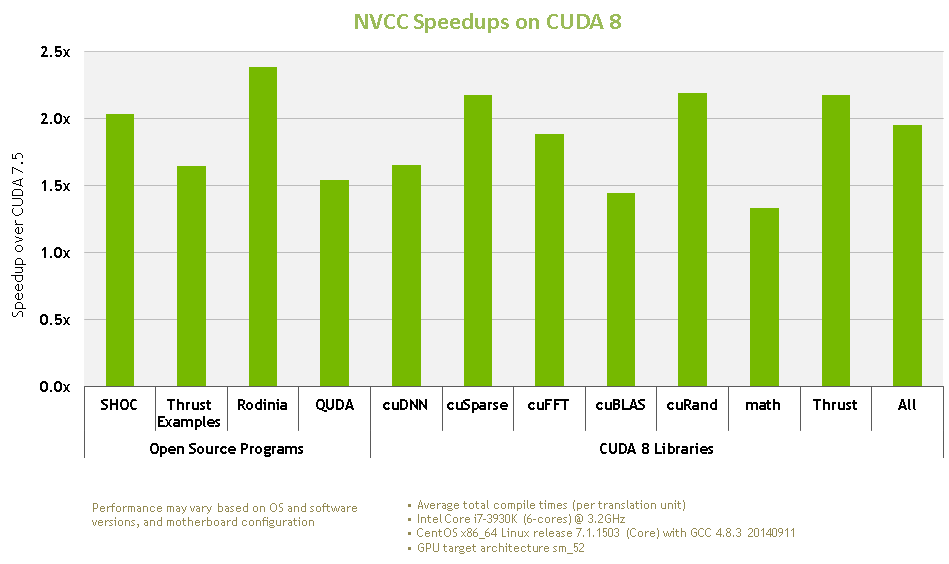
The NVIDIA compiler team is still actively working on reducing compile time further; expect more compile time improvements in the next CUDA toolkit.
Extended __host__ __device__ Lambdas
A C++ lambda expression creates a “closure object” whose operator() is defined inline in the body of the lambda expression. Lambda expressions are more powerful than plain functions because they can capture variables from the enclosing function or class scope; they are also more convenient because the operator() body can be defined closer to the point of use. The “closure type” defined by the lambda can be used in template instantiations just like any other type.
In CUDA 7.5, you can define __device__ lambdas in host code and use them to instantiate __global__ function templates. CUDA 8 now also supports __host__ __device__ lambdas in __global__ template instantiations. Since the lambda is marked __host__ __device__, it can be called from host code as well. This is very useful because it allows you to make a runtime decision whether to execute a lambda on the GPU or the CPU. In contrast, a __device__ lambda can only execute on the GPU so you can’t switch targets at run time.
As a concrete example, here’s an implementation of the saxpy BLAS function that can run on either the GPU or CPU based on a runtime threshold (first published in CUDA 8 Features Revealed).
void saxpy(float *x, float *y, float a, int N) {
using namespace thrust;
auto r = counting_iterator(0);
auto lambda = [=] __host__ __device__ (int i) {
y[i] = a * x[i] + y[i];
};
if(N > gpuThreshold)
for_each(device, r, r+N, lambda);
else
for_each(host, r, r+N, lambda);
}
Extended __host__ __device__ lambda is an experimental feature in CUDA 8, and requires the —expt-extended-lambda nvcc flag. When writing “middleware” templates that can be instantiated with arbitrary user code, it’s useful to be able to detect at compile time whether a type is generated from an extended __device__ or __host__ __device__ lambda. The CUDA 8 compiler provides builtin type trait functions for this purpose and also defines the macro __CUDACC_EXTENDED_LAMBDA__ when the —expt-extended-lambda flag is passed to nvcc, as shown in the following example.
int main(void)
{
#ifndef __CUDACC_EXTENDED_LAMBDA__
#error "please compile with --expt-extended-lambda"
#endif
auto d_lambda = [] __device__ { };
auto hd_lambda = [] __host__ __device__ { };
static_assert(__nv_is_extended_device_lambda_closure_type(
decltype(d_lambda)), "");
static_assert(__nv_is_extended_host_device_lambda_closure_type(
decltype(hd_lambda)), "");
}
There’s one caveat: __host__ __device__ lambdas may have worse performance in host code compared to plain unannotated host lambdas. Due to an implementation constraint, the CUDA compiler wraps the original extended __host__ __device__ lambda in an instance of std::function, in the host code sent to the host compiler. As a result, the host compiler may not be able to inline the body of the original __host__ __device__ lambda at the call site. If the __host__ __device__ lambda body is short and the lambda is being called frequently from host code, this may have a significant performance impact. To reduce the potential performance loss, we can try increasing the amount of code in the lambda body thereby reducing the overall impact of the indirect function call through std::function. Another option is to convert the lambda to a named ‘functor’ type that provides an operator(); a downside is that CUDA C++ requires the named functor type to be non-local if it participates in a __global__ template instantiation.
Capture *this By Value
When we define a lambda within a class member function, the C++ Standard says that any reference to a class member variable implicitly captures the this pointer by value instead of capturing the member variable by value. Because host memory is not accessible from GPU on many existing platforms, this can cause a run time crash. Let’s look at this seemingly innocuous program using a lambda.
#include <cstdio>
template <typename Function>
__global__ void kernel(Function f) { printf("value = %d", f()); }
struct Wrapper {
int x;
Wrapper() : x(10) { };
void doWork() {
// define a __device__ lambda, and launch “kernel” with it
auto lam1 = [=] __device__ { return x+1; };
kernel<<<1,1>>>(lam1);
cudaDeviceSynchronize();
};
};
int main(void) {
Wrapper w1;
w1.doWork();
}
Here we define a __device__ lambda in doWork() and pass it to an instantiation of the __global__ template kernel. The program builds without any warnings. We expect it to print 11, but instead it crashes after it starts to run on the GPU!
Why Does It Crash?
Let’s take another look at the body of the lambda. We see that it refers to the member variable x. When the compiler processes this lambda, it actually captures the this pointer by value, and the code in the device lambda accesses copy_of_this->x when it executes. Because the object w1 is created in host code (main function), the this pointer points to host memory, and so the program dies when it tries to read inaccessible host memory on the GPU.
Using *this Capture
While we have shown the problem for CUDA C++, a similar issue can occur with plain C++ if the lambda’s operator() is invoked after the object denoted by *this has been destroyed. The draft C++17 Standard solves this problem by providing a new *this capture mode that tells the compiler to make a copy of the *this object instead of capturing this by value. The CUDA 8 compiler implements *this capture for certain categories of lambdas. Here’s the same example with the *this capture mode specified.
#include <cstdio>
template <typename Function>
__global__ void kernel(Function f) { printf("value = %d", f()); }
struct Wrapper {
int x;
Wrapper() : x(10) { };
void doWork() {
// ‘*this’ capture mode tells compiler to make a copy
// of the object
auto lam1 = [=, *this] __device__ { return x+1; };
kernel<<<1,1>>>(lam1);
cudaDeviceSynchronize();
};
};
int main(void) {
Wrapper w1;
w1.doWork();
}
Et Voilá! This version runs without a crash and prints 11 as expected. Specifying *this in the lambda capture specification forced the compiler to capture a copy of the *this object itself when creating the lambda’s closure object, and the expression x+1 is transformed to (captured_copy_of_star_this).x + 1 . Since the object with the lambda closure type is passed by value from host to the kernel, the captured_copy_of_star_this resides in GPU-accessible memory and so the x field can be successfully accessed.
As a rule of thumb, always remember to consider the *this capture mode if:
- a lambda is defined within a member function and refers to member variables, and
- the lambda will be used in a
__global__function template instantiation.
Note that the *this capture mode is an experimental feature in CUDA 8 and is only supported for extended __device__ lambdas and for lambdas defined within device code, because nvcc does not yet support C++17. It also requires use of the --expt-extended-lambda nvcc command-line flag.
Function-Scope Static Variables
In CUDA 7.5, if you needed statically allocated device memory, you had to use global scope variables. Modern C++ style guidelines typically discourage global variables, because there’s no way to limit their visibility—any function may access and change their contents. For better encapsulation, CUDA 8 supports function-scope static device variables, as the following code shows.
class MyAlgorithm {
__device__ int *getSingleton(void) {
static int arr[1024] = { 1, 2, 3};
return arr;
}
public:
__device__ void doWork(int i, int val) {
int *p1 = getSingleton();
p1[i] = val;
}
};
In this example, we used a “singleton” array that is statically allocated and has its first 3 elements initialized to ‘1, 2, 3’. As we can see, this form offers better encapsulation compared to the old way of using global __device__ variables because only members and friends of MyAlgorithm can access the __device__ memory variable arr.
The lifetime of a function-scope static variable begins when the device code is loaded on the GPU and ends when the device code is unloaded (the same as file-scope __device__ variables). Even though a function-scope static variable appears lexically inside a function’s body, there is only one instance of the variable per GPU, irrespective of the number of GPU threads created at run time.
In CUDA 8, function-scope static variables cannot be dynamically initialized (this is the same as file scope __device__ variables). Also, these variables are implicitly allocated in __device__ memory, and the __device__ annotation is not required or allowed when declaring the variable.
Customizing #pragma unroll with Template Arguments
Unrolling loops is a very important compiler optimization. You can use the #pragma unroll <N> directive before a loop to ask the compiler to unroll the loop by N iterations. In CUDA 7.5, the “unroll factor” N had to be a constant literal (e.g. 2 or 32). This works great for non-template code when the unroll factor is a known constant, but there’s a problem if we want the unroll amount to depend on a template argument context, as the following example shows.
template <typename T, typename Function>
__device__ void apply_function(T *in, T *out, Function f1, size_t length) {
// Want to unroll this loop for performance
for (auto i = 0; i < length; ++i) {
out[i] += f1(in[i]);
}
}
__device__ void dowork(int *in, int *out, size_t length) {
auto light_lambda = [](int in) { /* few lines of code */ };
auto heavy_lambda = [](int in) { /* many lines of code */ };
apply_function(in, out, light_lambda, length);
apply_function(in, out, heavy_lambda, length);
}
We want to make the compiler unroll the loop in apply_function for performance; but we don’t want to specify the same unroll amount for every instantiation of apply_function because that may cause a code size explosion when apply_function is instantiated with heavy_functor. We can’t really do this if the unroll factor has to be a constant literal.
CUDA 8 solves this problem by allowing an arbitrary integral-constant-expression for the unroll block size N. Integral-constant-expression is precisely defined by the C++ Standard; a mental shorthand is that it’s an expression that can be evaluated to an integer at compile time. So for our use case, we can add a template argument to apply_function to specify the unroll amount as the following code shows.
template <int unrollFactor, typename T, typename Function>
__device__ void apply_function(T *in, T *out, Function f1, size_t length) {
// unroll loop by specified amount
#pragma unroll (unrollFactor)
for (auto i = 0; i < length; ++i) {
out[i] += f1(in[i]);
}
}
__device__ void dowork(int *in, int *out, size_t length) {
auto light_lambda = [] (int in) { /* few lines of code */ };
auto heavy_lambda = [] (int in) { /* many lines of code */ };
apply_function<64>(in, out, light_lambda, length);
apply_function<4>(in, out, heavy_lambda, length);
}
Here, we specified the unroll amount as 64 for light_lambda and 4 for the heavy_lambda case. One final tweak: the author of apply_function may want to put an upper limit on the unroll factor. She can do this by calling a constexpr function within the pragma itself, as the following example shows.
constexpr __host__ __device__ int mymin(int x, int y) { return x <= y ? x : y; }
template <int unrollFactor, typename T, typename Function>
__device__ void apply_function(T *in, T *out, Function f1, size_t length) {
// unroll loop by specified amount, up to 32 iterations
#pragma unroll mymin(unrollFactor, 32)
for (auto i = 0; i < length; ++i) {
out[i] += f1(in[i]);
}
}
__device__ void dowork(int *in, int *out, size_t length) {
auto light_lambda = [] (int in) { /* few lines of code */ };
auto heavy_lambda = [] (int in) { /* many lines of code */ };
apply_function<64>(in, out, light_lambda, length);
apply_function<4>(in, out, heavy_lambda, length);
}
Now the maximum unroll factor is limited to 32 by the call to the constexpr function mymin.
Improved nvstd::function (Polymorphic Functional Wrapper)
Standard C++ provides the std::function class to hold any callable entity, such as a lambda, functor or function pointer. Because std::function methods are provided by the host compiler library, they cannot be called from device code. CUDA C++ provides an alternative nvstd::function defined in the <nvfunctional> header. CUDA 8.0 updates nvstd::function so that it can now be used in both host and device code, as the following example shows.
#include <nvfunctional>
#include <cstdio>
__host__ __device__ void invoker(const nvstd::function<void()> &in) {
in();
}
__device__ void device_printer(void) { printf("second\n"); }
__global__ void kernel(void) {
invoker([] { printf("first\n"); });
invoker(device_printer);
}
void host_printer(void) { printf("fourth\n"); }
int main(void) {
kernel<<<1,1>>>();
cudaDeviceSynchronize();
invoker([] { printf("third\n"); });
invoker(host_printer);
}
This example uses nvstd::function objects in both host and device code, and initializes them from both lambdas and function pointers. One caveat: you still cannot pass nvstd::function objects initialized in host code to device code (and vice versa).
Runtime Compilation And Dynamic Parallelism
Runtime Compilation, originally released with CUDA 7, enables compilation of CUDA C++ device code at run time using the NVRTC library. A key application of Runtime Compilation is to specialize device code at run time, e.g. by replacing loop bounds or filter coefficients by literal constants. This helps the compiler generate better code. CUDA 8 adds two new Runtime Compilation features: support for dynamic parallelism and easier integration with template host code.
Dynamic Parallelism enables kernel launches from device code. This enables writing adaptive parallel algorithms that increase the amount of active parallel threads by launching child kernels, depending on the amount of work to be done. CUDA 8 now supports using Dynamic Parallelism in code compiled at run time, as Figure 3 shows.
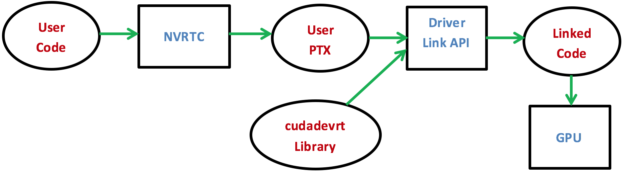
To use Runtime Compilation with device code that uses Dynamic Parallelism, first compile the code with the Runtime Compilation API, passing the –rdc=true flag to indicate the need to generate relocatable device code. Next, link the generated PTX against the cudadevrt library from the CUDA Toolkit using runtime linking with the CUDA driver API. The linked device code can now be loaded and run on the GPU using the CUDA Driver API.
Check out the NVRTC User Guide for a complete code example and build instructions.
Runtime Compilation And Template Host Code
Let’s look at a common scenario where the NVRTC API is invoked from a C++ source file. The code string contains a __global__ function template, so it would be nice to have an easy way to instantiate it based on template arguments in the C++ source function or class. CUDA 8 Runtime Compilation exposes new APIs to achieve this goal.
Here’s the code string and the corresponding template host function.
const char nvrtc_code[] = "template <typename T>"
"\n__global__ void kernel( /* params */) {"
"\n /* lots of code */"
"\n}";
template <typename T>
void host_launcher(void)
{
// customize and launch "kernel"
}
The body of host_launcher<T> must create and launch instantiations of kernel<T>. Since the kernel source code is in a string, the standard C++ template instantiation mechanism won’t do the job. The solution has two parts. The first part is a way to get the name of the type T that host_launcher is instantiated with (e.g. int, char, myClass). Second is to use the Runtime Compilation API to instantiate the kernel template with the given type name and get back the mangled name of the instantiated function in the generated PTX. The NVRTC compiler mangles names according to the IA64 ABI. Using the mangled name, you can query the CUDA Driver API to locate the kernel function and launch it. Let’s look at the steps in more detail.
Retrieving the Host Type Name
Given a type T, there are different platform-specific ways to get its name. For example, gcc and clang provide abi::__cxa_demangle(), while cl.exe provides UnDecorateSymbolName(). NVRTC provides nvrtcGetTypeName() as a thin wrapper around these platform-specific functions.
template <typename T>
void host_launcher(void){
// Get name for "T" and create the name of the kernel instantiation
std::string type_name;
nvrtcGetTypeName<T>(&type_name);
auto kernel_instantiation = std::string("kernel<") + type_name + ">";
}
The example code above extracts the type name for T by invoking nvrtcGetTypeName<T>(), and uses it to generate the name of the __global__ template kernel instantiation (kernel_instantiation).
Instantiating the __global__ template
The following complete host_launcher() function registers the kernel instantiation name with NVRTC by calling nvrtcAddNameExpression(), compiles the program by using nvrtcCompileProgram(), and extracts the mangled kernel name in the generated PTX with nvrtcGetLoweredName().
template <typename T>
void host_launcher(void)
{
// Get name for "T" and create the name of the kernel instantiation
std::string type_name;
nvrtcGetTypeName<T>(&type_name);
auto kernel_instantiation = std::string("kernel<") + type_name + ">";
// Register the kernel instantiation with NVRTC
nvrtcAddNameExpression(prog, kernel_instantiation.c_str());
// Compile the program
nvrtcCompileProgram(prog, ...);
// Get the mangled name of the kernel
const char *name;
nvrtcGetLoweredName(prog,
kernel_instantiation.c_str(), // name expression
&name ); // lowered name
}
For example, instantiating host_launcher<int> will create a __global__ template instantiation expression kernel<int>, and the mangled name in the generated PTX for the kernel will be _Z6kernelIiEvv. The mangled name can be passed to the CUDA Driver API to locate and launch the correct kernel function.
The NVRTC User Guide has complete code examples for all the new APIs we discussed here.
Get Started with CUDA 8 Today!
The CUDA Toolkit version 8.0 is available now, so download it now and try out the new features!The NVIDIA compiler team needs your feedback to guide future development. If there are improvements or new features that would help you or enable your next project, or if you have examples of code that doesn’t perform like you expect, please contact us via the comments below.
The team looks forward to your feedback. Happy CUDA Coding!