CUDA 11.2 features the powerful link time optimization (LTO) feature for device code in GPU-accelerated applications. Device LTO brings the performance advantages of device code optimization that were only possible in the nvcc whole program compilation mode to the nvcc separate compilation mode, which was introduced in CUDA 5.0.
Separate compilation mode allows CUDA device kernel code to span across multiple source files whereas in whole program compilation mode all the CUDA device kernel code in the program is required to be in a single source file. Separate compilation mode introduced source code modularity to device kernel code and so was an important step for improving developer productivity. Separate compilation mode enabled developers to better design and organize device kernel code and to GPU-accelerate many more existing applications without significant code refactoring effort to move all the device kernel code to a single source file. It also improved developer productivity for large parallel application development by only requiring re-compilations of device source files with incremental changes.
The scope of CUDA compiler optimizations is generally limited to each source file that’s being compiled. In separate compilation mode, the scope of compile time optimization may be limited as the compiler does not have visibility to any device code referenced outside of a source file, as the compiler cannot take advantage of optimization opportunities that cross file boundaries.
In comparison, in the whole program compilation mode, all the device kernel code that is present in the program is in the same source file eliminating any external dependencies and allowing the compiler to perform optimizations that were not possible in separate compilation mode. Consequently, programs compiled in whole program compilation mode are usually more performant compared to those compiled in separate compilation mode.
With Device Link Time Optimization (LTO), which was previewed in CUDA 11.0, you can get the source code modularity of separate compilation along with the runtime performance of whole program compilation for device code. While the compiler may not be able to make globally optimal code transformations when optimizing separately compiled CUDA source files, the linker is in a better position to do so.
Compared to the compiler, the linker has a whole program view of the executable being built including source code and symbols from multiple source files and libraries. A whole program view of the executable enables the linker to choose the most performant optimization suitable for the separately compiled program. This Device Link Time Optimization is performed by linker and is a feature of the nvlink utility in CUDA 11.2. Applications with multiple source files and libraries can now be GPU-accelerated without compromising performance in separate compilation mode.
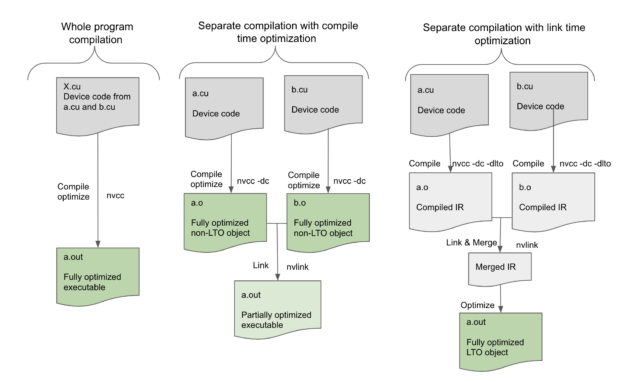
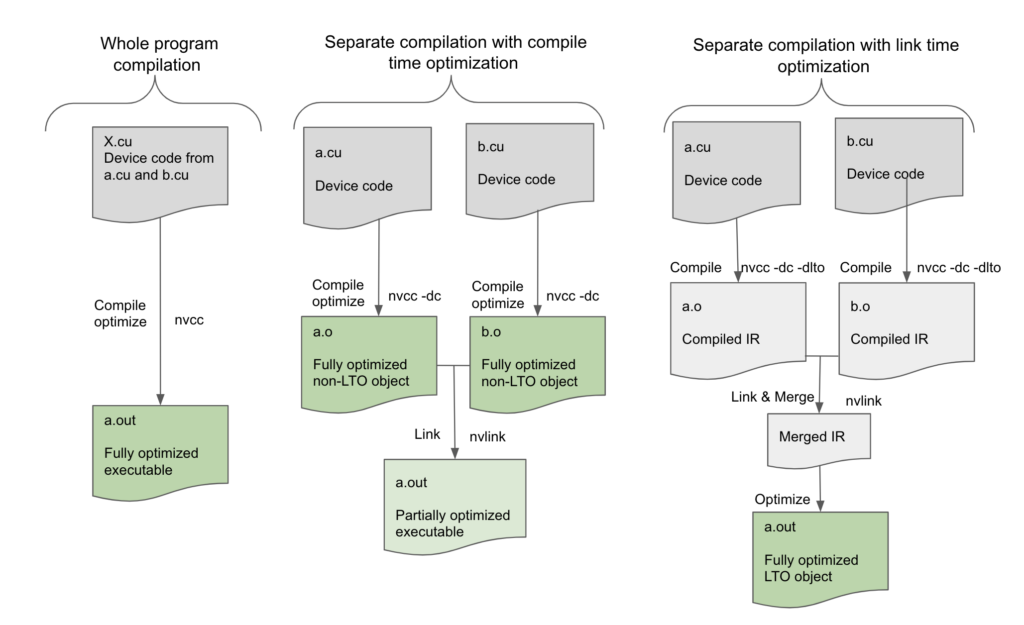
Figure 1, in nvcc whole program compilation mode the device program to be compiled in a single source file X.cu, without any unresolved external references to device functions or variables, can be fully optimized by the compiler at compile time. However, in separate compilation mode, the compiler can only optimize the device code within the individual source file being compiled leaving the final executable to be not as optimized as possible for there may be more optimization possible across the source files which the compiler cannot perform. Device Link Time Optimization bridges this gap by deferring optimization to the link step instead.
In device LTO mode, we store a high-level intermediate form of the code for each translation unit, and then at link time we merge all those intermediates to create a high-level representation of all the device code. This enables the linker to perform high-level optimizations like inlining across file boundaries, which not only eliminates the overhead of the calling conventions, but also further enables other optimizations on the inlined block of code itself. The linker can also take advantage of offsets that have been finalized. For instance, shared memory allocations are finalized, and the data offsets are known only at link time, so Device Link Time Optimization can now make low-level optimizations such as constant propagation or folding possible for device code. Even if a function is not inlined, the linker can still see both sides of a call for optimizing the calling convention. Hence, the quality of the code generated for separately compiled programs can be improved with device link time optimization and be as performant as if the program were compiled in whole program mode.
To understand the limitations of separate compilation and possible performance gains with device LTO, let’s look at an example from a MonteCarlo benchmark. There is a call to a device function get_domain() that is defined in another file:
In the below sample code, MC_Location::get_domain is not inlined in standard compilation mode as it is defined in another file, but will be
inlined using Device link optimization from CUDA 11.2
__device__ void MCT_Reflect_Particle(MonteCarlo *monteCarlo,
MC_Particle &particle){
MC_Location location = particle.Get_Location();
const MC_Domain &domain = location.get_domain(monteCarlo);
...
...
/* uses domain */
}
The function get_domain is part of another class, so it makes sense that it is defined in another file. But in separate compilation mode, the compiler will not know what get_domain() does or even where it exists when it is being called, therefore the compiler cannot inline the function and has to emit the call along with the parameter and return handling, while also saving space for things like the return address after the call. This in turn makes it unable to potentially optimize the subsequent statements that use the domain value. In device LTO mode, get_domain() can be fully inlined and the compiler can perform more optimizations thus eliminating the code for the calling convention and enabling optimizations based on the domain value.
In short, device LTO brings all the performance optimizations to the separate compilation mode that were previously only available in the whole program compilation mode.
Using device LTO
To use device LTO, add the option -dlto to both the compilation and link commands as shown below. Skipping the -dlto option from either of these two steps affects your results.
Compilation of cuda source files with -dlto option:
nvcc -dc -dlto *.cu
Linking of cuda object files with -dlto option:
nvcc -dlto *.o
Using -dlto option at compile time instructs the compiler to store a high-level intermediate representation (NVVM-IR) of the device code being compiled into the fatbinary. The -dlto option at link time will instruct the linker to retrieve the NVVM IR from all the link objects and merge them together into a single IR and perform optimization on the resulting IR for code generation. Device LTO works with any supported SM arch target.
Using device LTO with existing libraries
Device LTO can only take effect when both the compile and link steps use -dlto. If -dlto is used at compile time but not at link time then at link time each object is individually compiled to SASS and then linked as normal without any opportunity for optimization. If -dlto is used at link time but not at compile time, then the linker does not find the intermediate representations to perform LTO on and skips the optimization step linking the objects directly.
Device LTO works best if all the objects that contain device code are built with -dlto. However, it can still be used even if only some of the objects use -dlto, as in Figure 2.
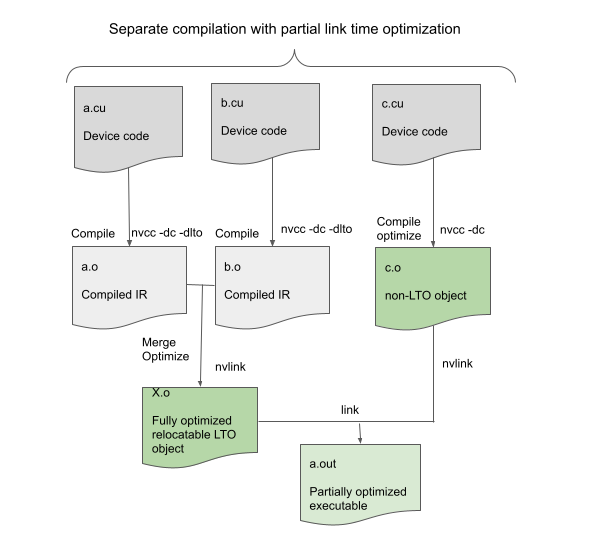
In that case, at link time, the objects built with -dlto are linked together to form a relocatable object, and then linked with the other non-LTO objects. This does not provide optimal performance but may still improve performance by optimizing within the LTO objects. This feature enables the usage of -dlto even with outside libraries that are not built with-dlto; it just means that the library code does not benefit from Device LTO.
Fine-grained per architecture device link optimization support
The global -dlto option is suitable when compiling for a single target architecture.
When you compile for multiple architectures with -gencode, specify exactly what intermediates to store into the fat binary. For example, to store Volta SASS and Ampere PTX in an executable, you would currently compile with following options:
nvcc -gencode arch=compute_70,code=sm_70
-gencode arch=compute_80,code=compute_80
With a new code target, lto_70, you can get fine-grained control to indicate which target architecture should store the LTO intermediary instead of SASS or PTX. For example, to store Volta LTO and Ampere PTX, you would compile with the following code example:
nvcc -gencode arch=compute_70,code=lto_70 -gencode arch=compute_80,code=compute_80
Performance results
What kind of performance impact can you expect with device LTO?
GPUs are sensitive to memory traffic and register pressure. As a result, the device optimizations generally have more impact than the corresponding host optimizations. As expected, we observed many applications benefiting from device LTO. In general, the speedup through device LTO depends on the CUDA application characteristics.
Figures 3 and 4 show graphs that are comparisons of the runtime performance and build time of an internal benchmark application and another real-world application, both Monte-Carlo applications in three compilation modes:
- Whole program compilation
- Separate compilation without device LTO
- Separate compilation with device LTO mode
The customer application that we tested had a single main computational kernel that accounted for 80%+ of the runtime, which called into hundreds of separate device functions spread across different translation units or source files. Manual inlining of the functions is effective but is cumbersome if you’d prefer to use separate compilation to maintain your traditional development workflow and library boundaries. In these situations, using device LTO to realize potential performance benefits without additional development effort is particularly attractive.
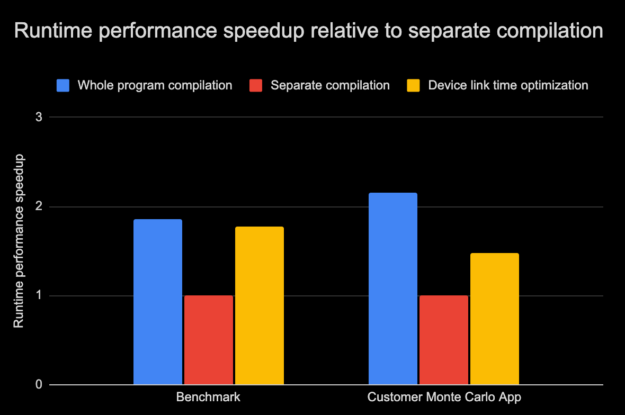
The runtime performance, as shown in Figure 3, of both the benchmark and the customer application with device LTO was close to whole program compilation mode overcoming the limitations posed by separate compilation mode. Remember that the performance gains are largely dependent on how the application itself is crafted. As we observed, in some cases, the gains were marginal. With another CUDA application suite, device LTO resulted in an average runtime performance speed-up of around 25%.
Later in this post, we cover more about the scenarios where device LTO is not particularly beneficial.
There is another aspect to device LTO in addition to GPU performance, and that is build time. The total build time using device LTO depends largely on the application size and other system factors. In Figure 4, the relative difference in the build time of the internal benchmark is compared against the customer application for the three different compilation modes as earlier. The internal benchmark comprises roughly 12 thousand lines of code whereas the customer application has tens of thousands of lines of code.
There are situations where the whole program mode compilation may be faster due to fewer passes required to compile and optimize those programs. In addition, smaller programs in whole program mode could sometimes compile faster because it has fewer compile commands and therefore fewer invocations of host compiler also. But large programs in whole program mode can pose higher optimization cost and memory usage. In such cases then compiling using separate compilation mode can be faster. This can be observed for the internal benchmark in Figure 4 where the whole program mode compilation time was faster by 17% while with the customer application, the whole program mode compilation was slower by 25%.
The limited range of optimizations and smaller translation units make compilation faster in separate compilation mode. Separate compilation mode also reduces the overall incremental build times when incremental changes are isolated to a few source files. When device link time optimization is enabled the compiler optimization phase is eliminated reducing the compile time significantly, thus speeding up compilation of separate compilation mode even further. But, at the same time, as the device code optimization phase is deferred to the linker and since the linker can perform more optimizations in separate compilation mode, the link time of separate compiled programs may be higher with device link time optimization. In Figure 4, we can observe the Device LTO build time was only slower by 7% with the benchmark but with the customer application, the build time was slower by almost 50%.
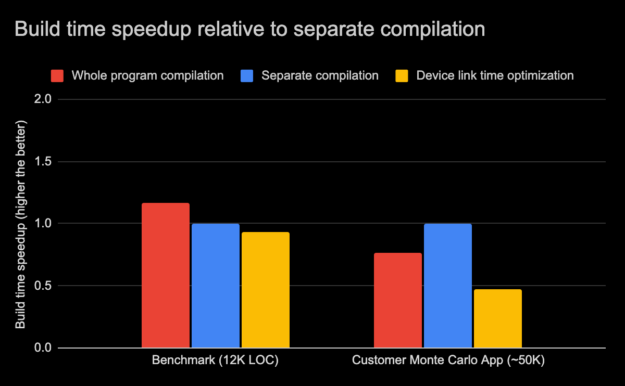
In 11.2, we have also introduced the new nvcc -threads option, which enables parallel compilation when targeting multiple architectures. That can help to reduce build times. In general, the total (compile and link) build time may vary for these compilation modes depending on a diverse set of factors. Nevertheless, because the compile time is significantly reduced using device LTO, we expect that the overall build of separate compilation mode with device link time optimization enabled should be comparable in most typical scenarios.
Limitations of device LTO
Device LTO is particularly powerful when it inlines device functions across file objects. However, in the case of some applications, the device code may all reside within a source file, in which case device LTO does not make much difference.
Indirect calls from function pointers such as callbacks do not benefit much from LTO, as those indirect calls cannot be inlined.
Be aware that device LTO performs aggressive code optimization and therefore it is not compatible with the usage of the -G NVCC command-line option for enabling symbolic debug support of device code.
For CUDA 11.2, device LTO only works with offline compilation. JIT LTO is not yet supported for device LTO intermediate forms.
File-scope commands like -maxrregcount or -use_fast_math are not compatible with device LTO as LTO optimizations cross file boundaries. If all files are compiled with the same option then everything is fine, but if they differ, then device LTO complains at link time. You can override these compilation attributes for device LTO by specifying -maxrregcount or -use_fast_math at link time, and then that value is used for all the LTO objects.
Even though using device LTO moves much of the time spent on optimization during compile time to link time, the overall build time is usually comparable between an LTO build and a non-LTO build, as the compile time is significantly reduced. However, it increases the amount of memory needed during link time. We believe that the benefits from device LTO should offset the limitations in the most common cases.
Try out device LTO
If you are looking to build GPU-accelerated applications in separate compilation mode without compromising performance or device source code modularity, device LTO is for you!
Using device LTO programs compiled in separate compilation mode can leverage the performance benefits of code optimizations that cross file boundaries and thus help close the performance gap relative to whole program compilation mode.
To assess and exploit the benefits of device LTO for your CUDA application, download the CUDA 11.2 Toolkit today and try it out. Also, please let us know what you think. We are always looking for ways to improve the CUDA application development and runtime performance tuning experience.
