
NVIDIA recently unveiled new breakthroughs in NVIDIA Riva for speech AI, and NVIDIA NeMo for large-scale language modeling (LLM). Riva is a GPU-accelerated Speech AI SDK for enterprises to generate expressive human-like speech for their brand and virtual assistants. NeMo is an accelerated training framework for speech and NLU, that now has the capabilities to develop large-scale language models with trillions of parameters.
These advancements in speech and language AI make it simple for enterprises and research organizations to build state-of-the-art conversational AI capabilities customized for their industries and domains.
NVIDIA Riva
NVIDIA announced a new version with custom voice capability, where enterprises can easily create a unique voice to represent their brand with just 30 minutes of speech data.
Additionally, NVIDIA announced Riva Enterprise, a paid program that includes NVIDIA Expert support for enterprises that require large-scale Riva deployments. Riva is still available for free to customers and partners with smaller workloads.
Highlights include:
- Create a new neural voice with 30 mins of audio data in a day on A100.
- Fine-grained control to generate expressive voices.
- 12x higher performance with Fastpitch + HiFiGAN on A100 vs Tacotron2 + WaveGlow on V100.
- World-class speech recognition with support for five other languages.
- Scale to hundreds and thousands of real-time streams.
- Run in any cloud, on-premises, and at the edge.
Sign up to receive the latest news and updates about Riva Enterprise for large-scale deployments.
Developing applications with Riva
For more information about components in the Riva workflow, see Introducing NVIDIA Riva: A GPU-Accelerated SDK for Developing Speech AI Applications.
Next, follow this tutorial to build your own end-to-end speech recognition service:
- Part 1: Speech Recognition: Generating Accurate Domain-Specific Audio Transcriptions Using NVIDIA Riva
- Part 2: Speech Recognition: Customizing Models to Your Domain Using Transfer Learning
- Part 3: Speech Recognition: Deploying Models to Production
For more tutorials on building speech apps like virtual assistants and transcription with entity recognition, see Riva Getting Started.
Learn more at the Conversational AI Demystified GTC session.
NVIDIA NeMo framework, Triton multi-GPU multi-node inference, and Megatron 530B
NVIDIA also launched capabilities for building, customizing, and deploying large language models for enterprises. The NeMo framework is a new capability for training large language models (LLM) up to trillions of parameters.
It includes advancements in Megatron, an open-source project led by NVIDIA researchers to develop techniques for efficiently training LLMs. Enterprises can use the NeMo framework to customize LLMs, such as the Megatron 530B, and deploy with NVIDIA Triton inference server across multiple GPUs and nodes.
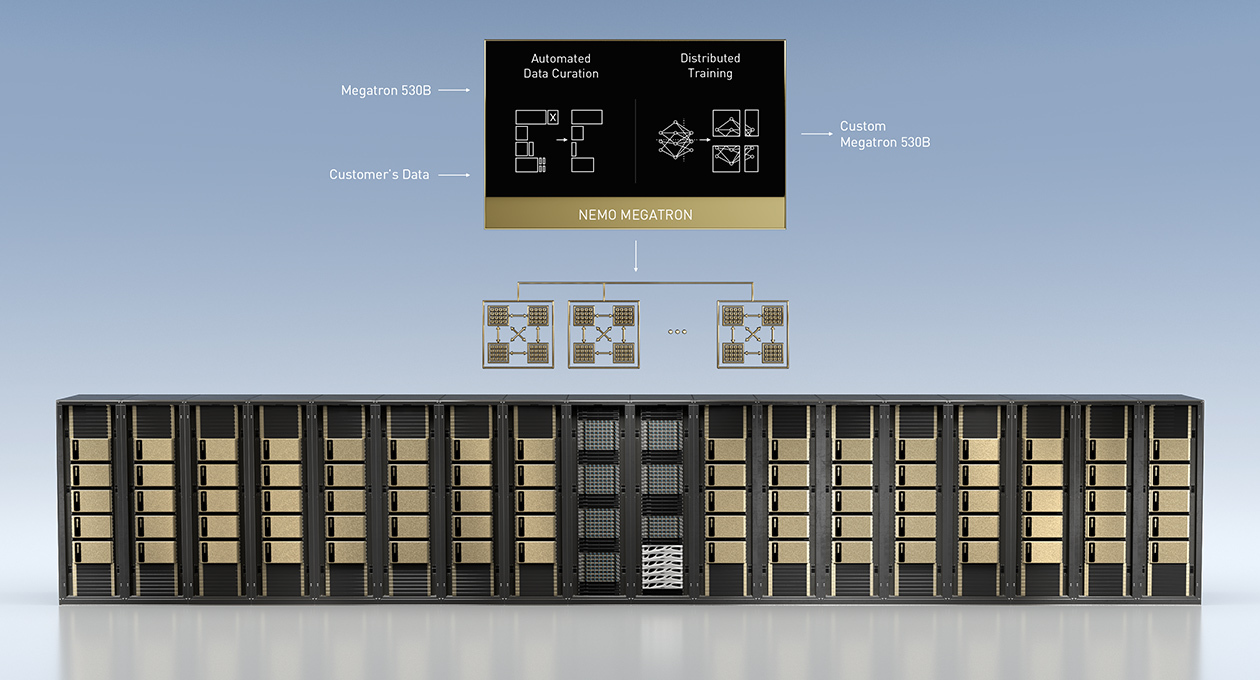
Highlights include:
- Automate data curation across a huge dataset, containing billions of pages of text.
- Train models such as Megatron 530B for new domains and languages.
- Scale from a single node to supercomputers, which includes tens of DGX A100 systems.
- Export to multiple nodes and GPUs, for real-time inference with NVIDIA Triton inference server.
Sign up to receive more information about the latest the NeMo framework release.
Learn more at the following GTC sessions:
NVIDIA NeMo: Speech Recognition, Speech Synthesis, and NLP Updates
A Step-by-step Guide to Building Large Custom Language Models
