
This week’s Model Monday release features the NVIDIA-optimized code Llama, Kosmos-2, and SeamlessM4T, which you can experience directly from your browser.
With NVIDIA AI Foundation Models and Endpoints, you can access a curated set of community and NVIDIA-built generative AI models to experience, customize, and deploy in enterprise applications.
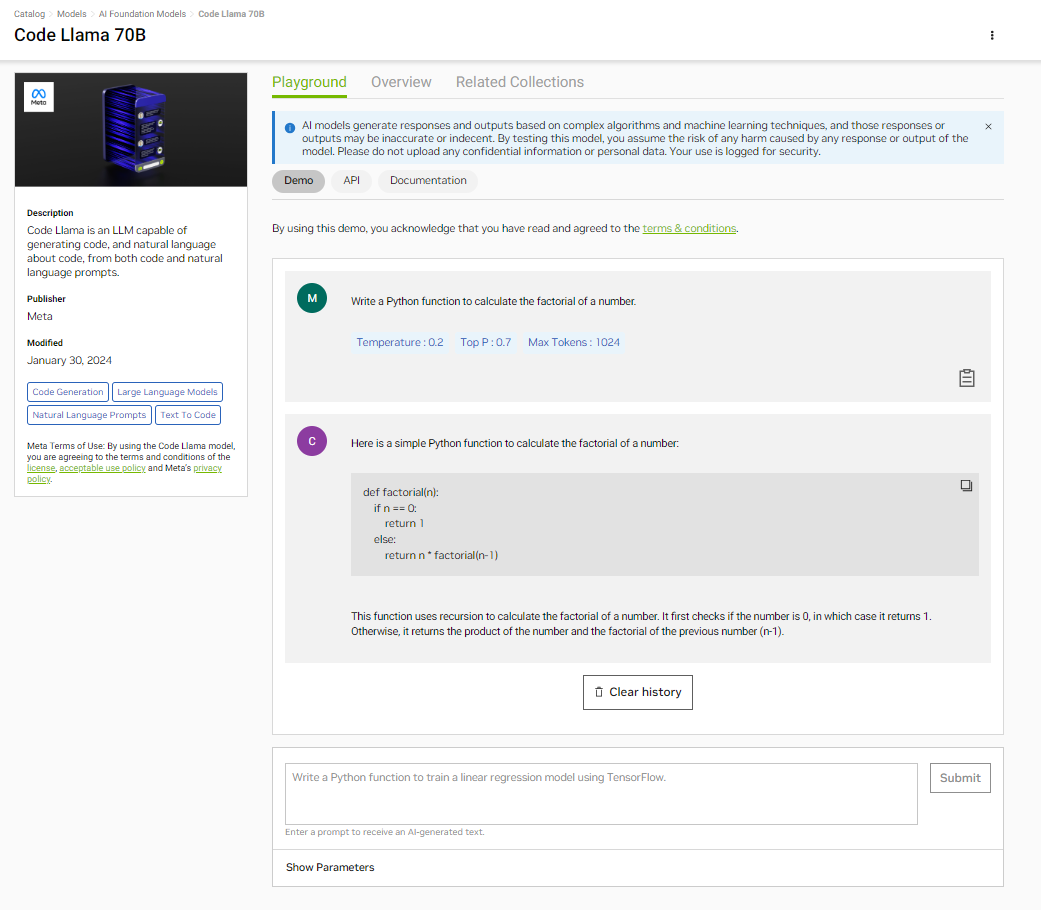
Code Llama 70B
Meta’s Code Llama 70B is the latest, state-of-the-art code LLM specialized for code generation. It builds on the Llama 2 model, offering improved performance and adaptability. This model can generate code from natural language, translate code between programming languages, write unit tests, and assist in debugging.
The large context length of 100K tokens enables Code Llama 70B to process and generate longer and more complex code, making it valuable for more comprehensive code generation and improved performance in handling intricate coding tasks. This open-source model can be used for various applications, such as code translation, summarization, documentation, analysis, and debugging.
The Code Llama 70B model optimized with NVIDIA TensorRT-LLM is available through the NGC catalog.
Kosmos-2
The latest multimodal large language model (MLLM) from Microsoft Research, Kosmos-2, takes a leap in visual perception using language models. It specializes in linking elements of language (such as words or phrases in input or output) to sections in images using bounding boxes. It ultimately enables tasks like visual grounding, grounded question-answering, multimodal referring, and image captioning.
Kosmos-2 builds on Kosmos-1, which supports perceiving multimodal input and in-context learning. Kosmos-2 was trained using a web-scale dataset of grounded image-text pairs, known as the GrIT, which includes text spans and bounding boxes that link specific regions in an image to relevant text. Figure 2 showcases its capabilities.
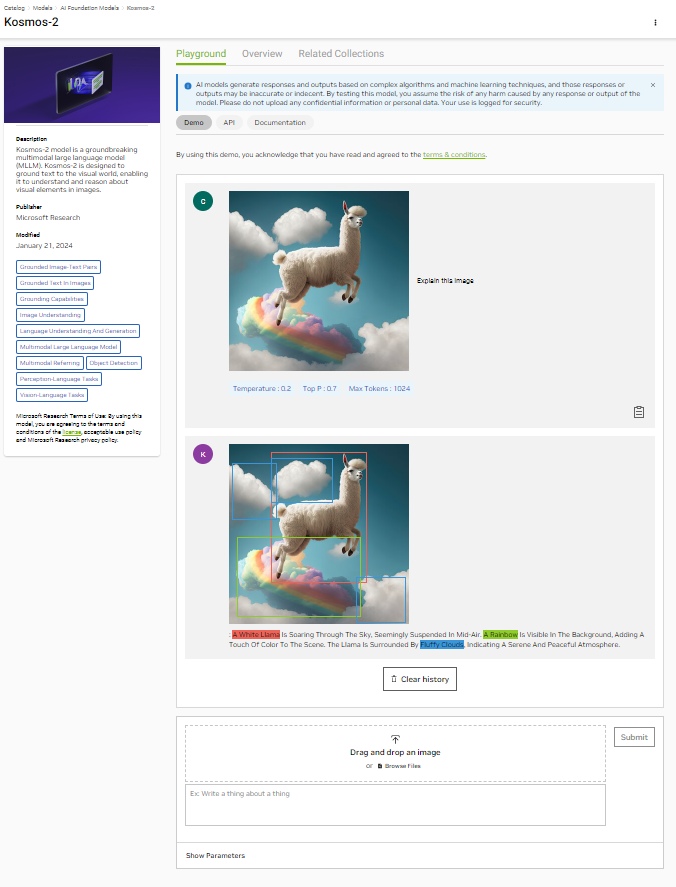
Compared to previous MLLMs that aim to achieve a similar goal, KOSMOS-2 excels in zero-shot phrase grounding and referring expression comprehension capabilities on popular academic benchmark datasets. If you’re an AI developer looking to push the boundaries of multimodal perception with large language models (LLMs), Kosmos-2 is for you.
SeamlessM4T
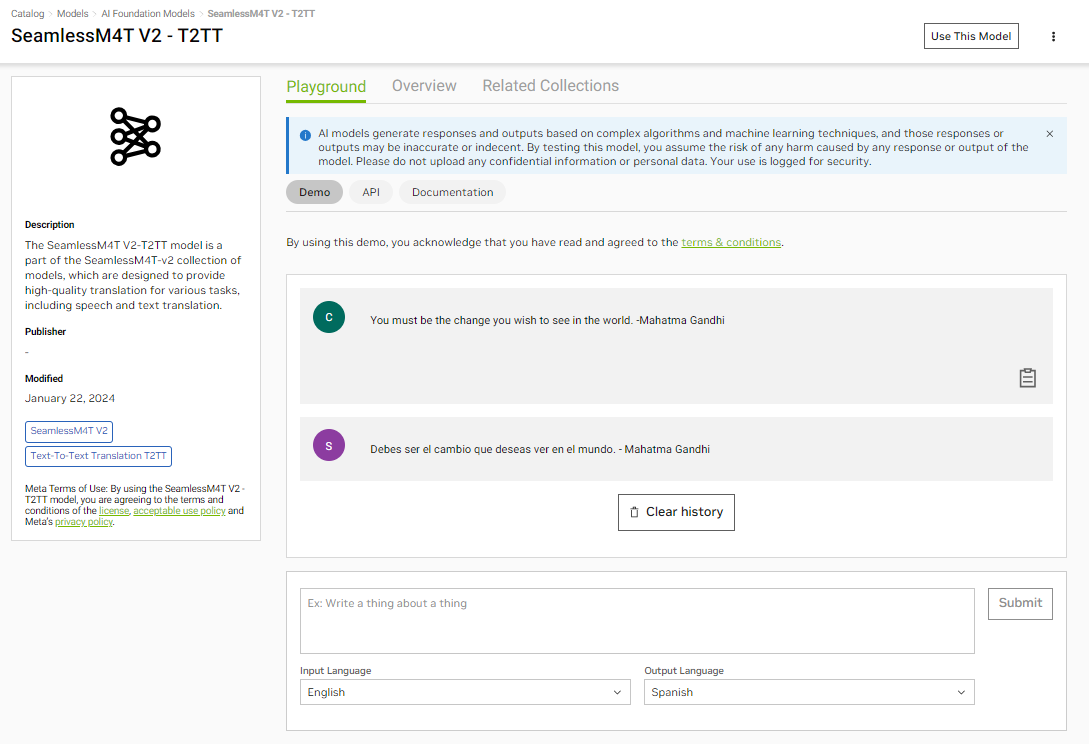
Meta’s SeamlessM4T is a multimodal foundation model capable of translating both speech and text, simplifying the process for enterprises to overcome communication obstacles. This fosters the exchange of knowledge and promotes international business efforts in today’s global economy.
This family of models supports automatic speech recognition (ASR), speech-to-text translation, and text-to-text translation for nearly 100 languages. The models also support language switching, enabling seamless communication for multilingual speakers as they naturally change languages during a conversation.
NVIDIA has optimized the SeamlessM4T text-to-text model. Figure 2 shows the model translating the speaker’s multilingual speech into Spanish.
Enterprise use cases for the model are many, including facilitating seamless interactions with international clients and partners. In customer service, real-time translation of customer queries and support responses can ensure effective communication across language barriers and for global teams collaborating on projects.
Kosmos-2 user interface
You can experience Kosmos-2 directly from your browser using a simple user interface on the NVIDIA NGC catalog. Visit the Kosmos-2 playground in the NGC catalog, type in your prompts, and see the results generated from the models running on a fully accelerated stack. Video 1 shows the NVIDIA AI Foundation model interface used to answer user prompts from the image using Kosmos-2 running on a fully accelerated stack.
Kosmos-2 API
You can also use the API to test the model. Sign in to the NGC catalog, then access NVIDIA cloud credits to experience the models at scale by connecting your application to the API endpoint.
Use the Python example below to call the API and visualize the results. The code uses requests, PIL, and IPython modules. If these aren’t available, you can use pip for installation, preferably in a virtual environment. To follow along, first set up a Jupyter Notebook.
!pip install requests ipython pillow
Step 1: Obtain the NGC catalog API key
In the NGC catalog API tab, select Generate Key. You will be prompted to sign up or sign in.
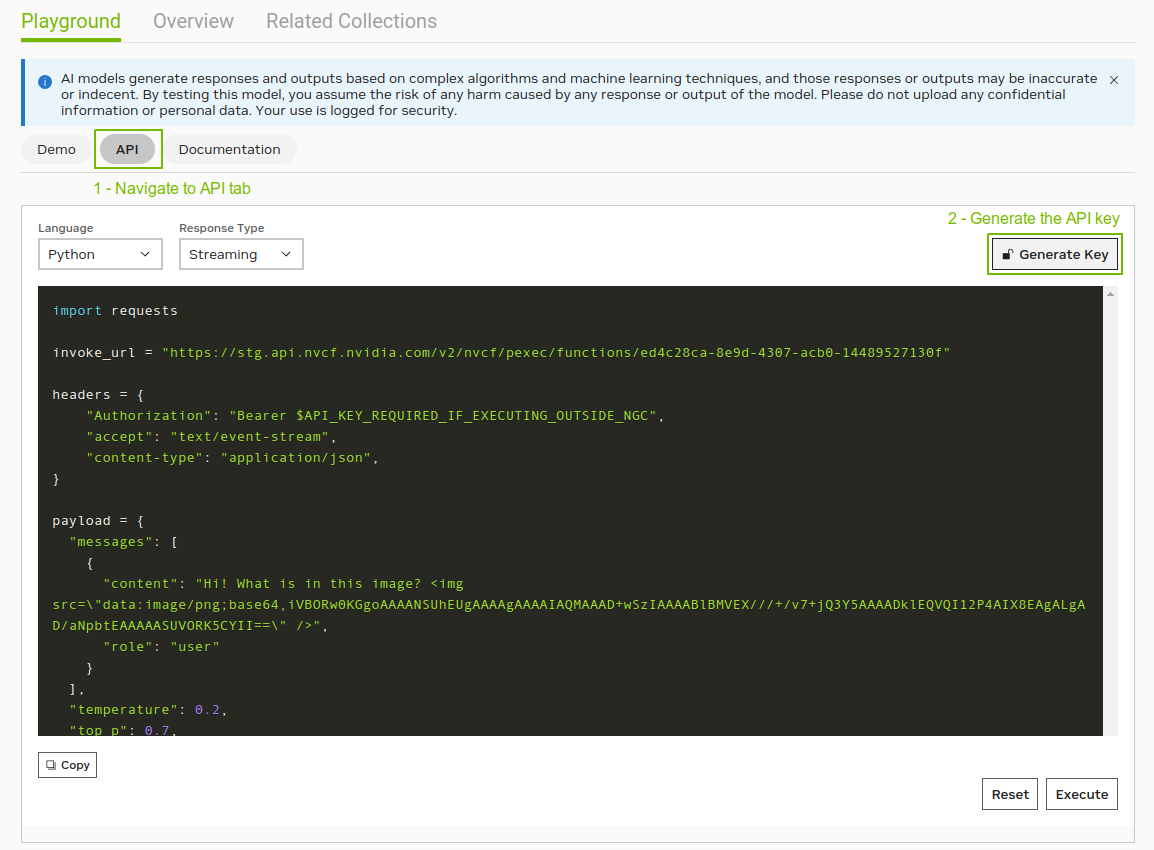
Next, set the API key in your code:
# Will be used to issue requests to the endpoint
API_KEY = “nvapi-xxxx“
Step 2: Encode the image in Base64 format
To provide image inputs as part of your request, you must encode them in Base64 format. This example uses an image from the COYO-700M image-text pair dataset.
import os
import base64
# Fetch an example image from
!wget -cO - https://www.boredart.com//wp-content/uploads/2014/06/Beautiful-Pictures-From-the-Shores-of-the-Mythical-Land-421.jpg > scenery.png
# Encode the image in base64
with open(os.path.join(os.getcwd(), "scenery.png"), "rb") as image_file:
encoded_string = base64.b64encode(image_file.read())
# Optionally, Visualize the image
from IPython import display
display.Image(base64.b64decode(encoded_string))

Step 3: Send an inference request
The Kosmos-2 model can perform tasks like visual grounding, grounded question answering, multimodal referring, and grounded image captioning. The task to perform is determined by the inclusion of special tokens. Below, the special token <grounding> tells the model to link certain phrases in the text, to sections in the image. These phrases are enclosed in <phrase> tokens, shown in the output.
import requests
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/0bcd1a8c-451f-4b12-b7f0-64b4781190d1"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
headers = {
"Authorization": "Bearer {}".format(API_KEY),
"Accept": "application/json",
}
payload = {
"messages": [
{
"content": "<grounding>This scenery<img src=\"data:image/png;base64,{}\" />".format(encoded_string.decode('UTF-8')),
"role": "user"
}
],
"bounding_boxes": True,
"temperature": 0.2,
"top_p": 0.7,
"max_tokens": 1024
}
# re-use connections
session = requests.Session()
response = session.post(invoke_url, headers=headers, json=payload)
while response.status_code == 202:
request_id = response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
response = session.get(fetch_url, headers=headers)
response.raise_for_status()
response_body = response.json()
response_body
In Kosmos-2, expressions are represented as links in the Markdown format: (bounding boxes), for example. The bounding boxes are represented as sequences of coordinates. This API returns a response in the format shown below. It includes the output text, bounding box coordinates corresponding to phrases in the completion, and some additional metadata.
{'id': 'cfbda798-7567-4409-ba55-6ba9a10294fb',
'choices': [{'index': 0,
'message': {'role': 'assistant',
'content': 'is a fantasy landscape with <phrase>a tree</phrase> and <phrase>a temple</phrase> by <phrase>the lake</phrase>',
'entities': [{'phrase': 'a tree',
'bboxes': [[0.359375, 0.015625, 0.765625, 0.796875]]},
{'phrase': 'a temple',
'bboxes': [[0.078125, 0.421875, 0.234375, 0.890625]]},
{'phrase': 'the lake',
'bboxes': [[0.203125, 0.765625, 0.828125, 0.953125]]}]},
'finish_reason': 'stop'}],
'usage': {'completion_tokens': 32, 'prompt_tokens': 70, 'total_tokens': 102}}
Given the image and the prompt, “This scenery,” the Kosmos-2 API generated the caption, “is a fantasy landscape with a tree and a temple by the lake.” It also generated bounding box coordinates.
Step 4: Visualize the output
If you consider the image as a 2D grid laid out on X-Y plane, the bounding box coordinates are defined as [Top X, Top Y] and [Bottom X, Bottom Y]. These coordinates are expressed as percentages relative to the total width and total height of the image, respectively. To visualize them, render them on the image:
from PIL import Image, ImageDraw, ImageFont
from IPython.display import display
# Extract the entities from the message body.
# This includes a list of phrases and corresponding bounding boxes
data = response_body['choices'][0]['message']['entities']
# Load your image
image = Image.open(os.path.join(os.getcwd(), "scenery.png"))
draw = ImageDraw.Draw(image)
width, height = image.size
# Set font type and size for phrases
font = ImageFont.load_default().font_variant(size=10)
def get_textbox_dim(text_string, font):
'''
Calculate the width and height of a text string with a given font.
'''
_, descent = font.getmetrics()
text_width = font.getmask(text_string).getbbox()[2]
text_height = font.getmask(text_string).getbbox()[3] + descent
return (text_width, text_height)
# Iterate through all entities, and draw each phrase & box
for item in data:
phrase = item['phrase']
for bbox in item['bboxes']:
# Convert percentages to pixel coordinates
x1, y1, x2, y2 = bbox
x1, x2 = x1 * width, x2 * width
y1, y2 = y1 * height, y2 * height
# Draw the bounding box for entities
draw.rectangle([(x1, y1), (x2, y2)], outline="red", width=2)
# Determine size of the text for background
text_size = get_textbox_dim(phrase, font)
# Draw text background
draw.rectangle([x1, y1, x1 + text_size[0], y1 + text_size[1]], fill="black")
# Draw the phrase
draw.text((x1, y1), phrase, fill="white", font=font)
# Display the image in Jupyter Notebook
display(image)
Figure 6 shows a visualization of the Kosmos-2 output, given the image and the prompt, “This scenery.” The bounding boxes highlight entities in its completion: “is a fantasy landscape with a tree and a temple by the lake.” This example shows the remarkable capability of Kosmos-2 to describe the image and link-specific phrases in completion to its visual aspects.

Similarly, by enclosing specific phrases in the prompt with <phrase> and </phrase> tokens, you can direct Kosmos-2 to focus on and link these phrases in comprehension or question-answering tasks. An example prompt for visual question-answering might be, “<grounding>Question: What color are the <phrase>leaves on the tree</phrase>? Answer:”, to which the model responds with “red”.
Get started
Put the models to work on any GPU or CPU with NVIDIA Triton Inference Server, open-source software that standardizes AI model deployment and execution across every workload. Triton is part of the NVIDIA AI platform and available with NVIDIA AI Enterprise, an end-to-end AI runtime software platform, is designed to accelerate the data science pipeline and streamline the development and deployment of production-grade generative AI applications.
NVIDIA AI Enterprise provides the security, support, stability, and manageability to improve productivity of AI teams, reduce total cost of AI infrastructure, and ensure a smooth transition from POC to production. Security, reliability, and enterprise support are critical when AI models are ready to deploy for business operations.
Try the Kosmos-2 and SeamlessM4T models through the user interface or the API. If these models are the right fit for your applications, optimize the models with NVIDIA TensorRT-LLM.
If you’re building an enterprise application, sign up for an NVIDIA AI Enterprise trial to get support for taking your application to production.
