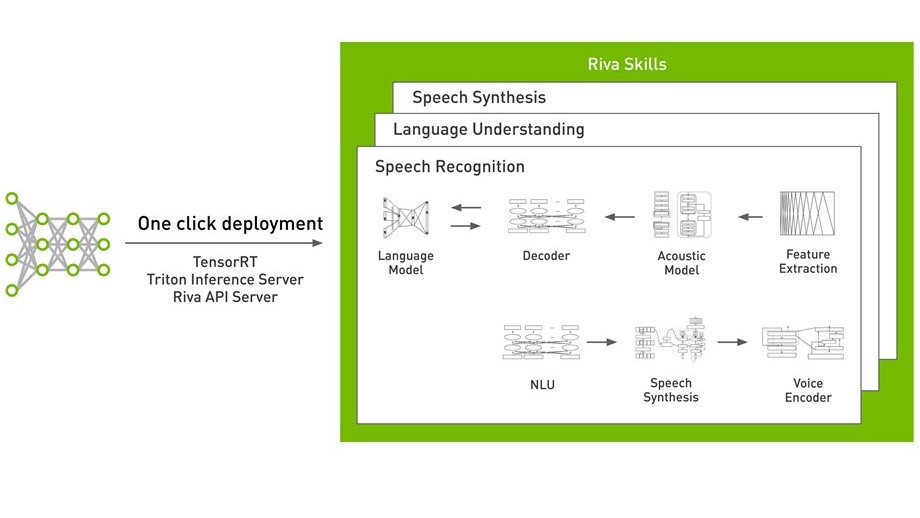
This post is part of a series about generating accurate speech transcription. For part 1, see Speech Recognition: Generating Accurate Domain-Specific Audio Transcriptions Using NVIDIA Riva. For part 2, see Speech Recognition: Customizing Models to Your Domain Using Transfer Learning.
NVIDIA Riva is an AI speech SDK for developing real-time applications like transcription, virtual assistants, and chatbots. It includes pretrained state-of-the-art models in NGC, the TAO toolkit for fine-tuning models on your domain, and optimized skills for high-performance inference. Riva makes it simpler to deploy the models using Riva containers in NGC or on Kubernetes using Helm charts. Riva skills are powered by NVIDIA TensorRT and served through NVIDIA Triton Inference Server.
In this post, we discuss the following topics:
- Setting up Riva
- Configuring Riva and deploying your model
- Inferencing with your model
- Key takeaways
The contents of this post are available in a Jupyter notebook, which you can download to follow along. For more information about Riva, see Introducing NVIDIA Riva: A GPU-Accelerated SDK for Developing Speech AI Applications.
Setting up Riva
Before setting up NVIDIA Riva, make sure you have the following installed on your system:
- python >= 3.6.9
- docker-ce > 19.03.5
- nvidia-docker2 3.4.0-1: Installation Guide
If you followed along in part 2, you should have all the prerequisites already installed.
The first step in setting up Riva is to install the NGC Command Line Interface Tool.
To log in to the registry, you must get access to the NGC API Key.
With the tools set up, you can now go ahead and download Riva from the Riva Skills Quick Start resource available on NGC. To download the package, you can use the following command (the latest version of which can be found on the previously mentioned Riva Skills Quick Start resource):
ngc registry resource download-version "nvidia/riva/riva_quickstart:1.6.0-beta"
The downloaded package has the following assets to help you get started:
- asr_lm_tools: These tools can be used to fine-tune language models.
- nb_demo_speech_api.ipynb: Getting started notebook for Riva.
- riva_api-1.6.0b0-py3-none-any.whl and nemo2riva-1.6.0b0-py3-none-any.whl: Wheel files to install Riva and a tool to convert a NeMo model to a Riva model. For more information, see the Inferencing with your model section later in this post.
- Quick start scripts (riva_*.sh, config.sh): Scripts to initialize and run a Triton Inference Server to serve Riva AI Services. For more information, see Configuring Riva and Deploying your model.
- Examples: Sample gRPC-based client code.
Configuring Riva and deploying your model
You might be wondering where to start. To streamline the experience, NVIDIA makes helps in customizing deployment with Riva by offering a config file to tweak everything you might want to tweak, using Riva AI services. For this walkthrough, you rely on the task-specific Riva ASR AI service.
For this walkthrough, we discuss only a few tweaks. Because you are working with just ASR, you can safely disable NLP and TTS.
# Enable or Disable Riva Services service_enabled_asr=true service_enabled_nlp=false service_enabled_tts=false
If you are following along from part 2, you can set the use_existing_rmirs param to true. We discuss this more later in this post.
# Locations to use for storing models artifacts riva_model_loc="riva-model-repo" use_existing_rmirs=false
You can choose the pretrained models to download from the model repository to run without customization.
########## ASR MODELS ##########
models_asr=(
### Punctuation model
"${riva_ngc_org}/${riva_ngc_team}/rmir_nlp_punctuation_bert_base:${riva_ngc_model_version}"
...
### Citrinet-1024 Offline w/ CPU decoder,
"${riva_ngc_org}/${riva_ngc_team}/rmir_asr_citrinet_1024_asrset3p0_offline:${riva_ngc_model_version}"
)
If you have RIVA models from when you were following Part 2 of this series, first build it into an intermediate format called Riva Model Intermediate Representation (RMIR) format. You can do this using Riva Service Maker. Service Maker is a set of tools that aggregates all the necessary artifacts (models, files, configurations, and user settings) for Riva deployment to a target environment.
Do this with the riva-build and riva-deploy commands. For more information, see Deploying Your Custom Model into Riva.
docker run --rm --gpus 0 -v <path to model>:/data <name and version of the container> -- \
riva-build speech_recognition /data/asr.rmir:<key used to encode the model> /data/<name of the model file>:<key used to encode the model> --offline \
--chunk_size=1.6 \
--padding_size=1.6 \
--ms_per_timestep=80 \
--greedy_decoder.asr_model_delay=-1 \
--featurizer.use_utterance_norm_params=False \
--featurizer.precalc_norm_time_steps=0 \
--featurizer.precalc_norm_params=False \
--decoder_type=greedy
docker run --rm --gpus 0 -v <path to model>:/data <name and version of the container> -- \
riva-deploy -f /data/asr.rmir:<key used to encode the model> /data/models/
Now that you have the model repository set up, the next step is to deploy the model. Although you can do this manually, we recommend using the prepackaged scripts for your first experience. The Quick Start scripts riva_init.sh and riva_start.sh are the two scripts that can be used to deploy the models using the exact configuration in config.sh.
bash riva_init.sh bash riva_start.sh
When you run riva_init.sh:
- The RMIR files for the model that you selected in
config.share downloaded from NGC in the directory that you specified. - For each of the RMIR model files, a corresponding Triton Inference Server model repository is generated. This process may take some time, depending on the number of services and the model that you selected.
To use your custom model, copy the RMIR files to the directory that you specified in config.sh (for $riva_model_loc). To deploy the model, run riva_start.sh. A riva-speech container is spun up with the models loaded from your selected repository to the container. Now, you can start sending inference requests.
Inferencing with your model
To make the most out of NVIDIA GPUs, Riva takes advantage of NVIDIA Triton Inference Server and NVIDIA TensorRT. In a conversational setting, applications optimize for as low of a latency as possible, but to use more compute resources, the batch size, that is, the number of requests being synchronously processed must be increased, which naturally increases latency. NVIDIA Triton can be used to serve multiple inference requests running on multiple models on multiple GPUs thus easing this issue.
You can query these models using a gRPC API in three broad steps: Import libs, set up the grpc channel, and get the response.
First, import all dependencies and load the audio. In this case, you are reading audio from a file. We also have a streaming example in the examples folder.
import argparse
import grpc
import time
import riva_api.audio_pb2 as ra
import riva_api.riva_asr_pb2 as rasr
import riva_api.riva_asr_pb2_grpc as rasr_srv
import wave
audio_file = "<add path to .wav file>"
server = "localhost:50051
wf = wave.open(audio_file, 'rb')
with open(audio_file, 'rb') as fh:
data = fh.read()
To install all the Riva-specific dependencies, you can use the .whl file provided in the package.
pip3 install riva_api-1.6.0b0-py3-none-any.whl
Next, create a grpc channel to the Riva endpoint and configure it to use the audio appropriate for your use case.
channel = grpc.insecure_channel(server) client = rasr_srv.RivaSpeechRecognitionStub(channel) config = rasr.RecognitionConfig( encoding=ra.AudioEncoding.LINEAR_PCM, sample_rate_hertz=wf.getframerate(), language_code="en-US", max_alternatives=1, enable_automatic_punctuation=False, audio_channel_count=1 )
Finally, send an inference request to the server and get the response.
request = rasr.RecognizeRequest(config=config, audio=data) response = client.Recognize(request) print(response)
Key takeaways
This API can be used to build your applications. You can install Riva on a single bare-metal system and get started with this exercise or deploy it at scale using Kubernetes and the provided Helm chart.
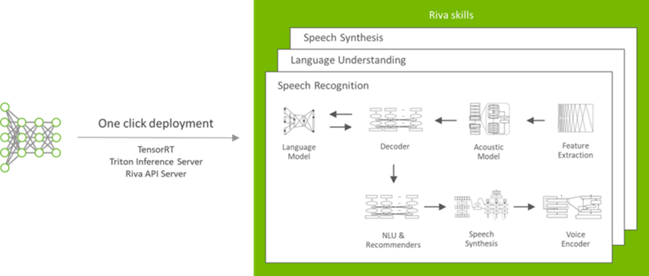
With this Helm chart, you can do the following:
- Pull the Riva Services API server, Triton Inference Server, and other necessary Docker images from NGC.
- Generate the Triton Inference Server model repository and start the NVIDIA Triton Server with the selected configuration.
- Expose the Inference Server and Riva server endpoints to be served as Kubernetes services.
For more information, see Deploying Riva ASR Service on Amazon EKS.
Conclusion
Riva is an end-to-end GPU-accelerated SDK for developing speech applications. In this series, we discussed the significance of speech recognition in industries, walked you through customizing speech recognition models on your domain to deliver world-class accuracy, and showed you how to deploy optimized services that can run in real-time using Riva.
For more information about other interesting Riva solutions, see all Riva posts on the Technical Blog.