This post is part of a series about generating accurate speech transcription. For part 2, see Speech Recognition: Customizing Models to Your Domain Using Transfer Learning. For part 3, see Speech Recognition: Deploying Models to Production.
Every day millions of audio minutes are produced across several industries such as Telecommunications, Finance, and Unified Communications as a Service (UCaaS). Each industry has its own jargon that need to be transcribed correctly for it to be useful for end users. Some Automatic Speech Recognition (ASR) use cases across these industries include – call center agents can get helpful resources based on their conversation with customers, companies can extract insights from customer calls to understand sentiment, and generating live captioning for video conferencing meetings.

In addition to delivering high accuracy across use cases, the speech recognition needs to run in real time.
In this post, we discuss how Riva helps achieve world-class speech recognition. Subsequent posts discuss how you can customize the speech recognition model and deploy it as an optimized skill:
- Customizing Speech Recognition Models to Your Domain Using TAO Toolkit
- Deploying Speech Recognition Models to Production Using Riva
Riva speech recognition
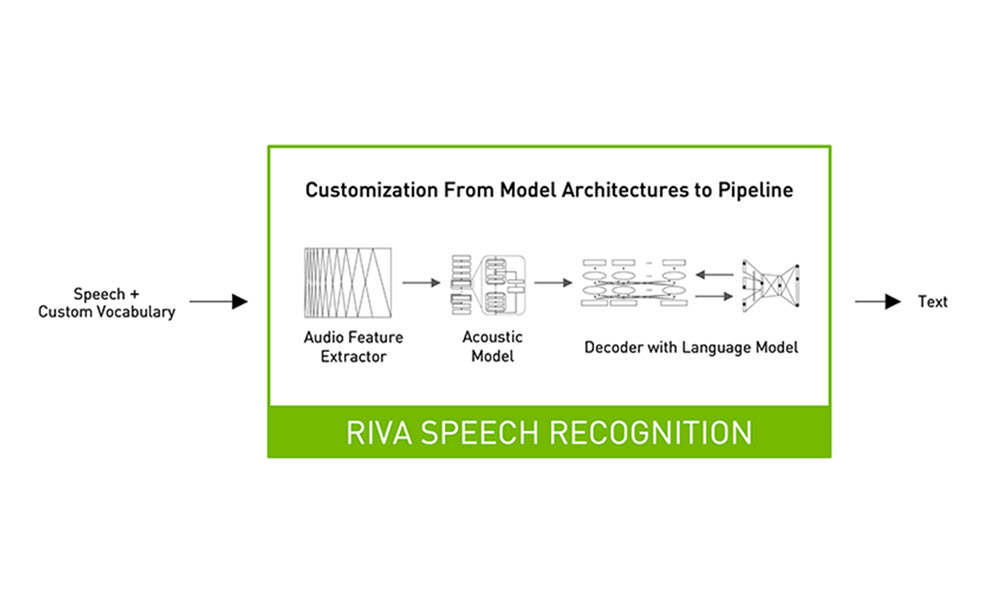
Riva is a speech AI SDK that provides flexibility to customize the speech pipeline at each step. This helps each enterprise adapt it to achieve the highest accuracy possible for their domain, and industry. Riva ensures the highest possible accuracy and also allows for real-time interactions with users.
High Accuracy
A typical Riva speech recognition pipeline includes a feature extractor that extracts audio features, an acoustic model and a beam search decoder based on n-gram language models for text prediction, and a punctuation model for text readability. Riva allows you to fine-tune models on domain specific datasets, bring in your own decoder as well as punctuation models. This can provide huge benefits for enterprises to achieve the highest accuracy possible.
Additionally, it includes text processing tools such as text normalization, which can be used to preprocess original transcripts, and inverse text normalization, which can be used to post process generated transcripts to improve readability of output. For example, inverse text normalization can be used to convert “in nineteen seventy” to “in 1970” in generated transcripts.
The models in Riva speech recognition pipeline are trained an expanding dataset with thousands of hours of open and real-world data representing telco, finance, healthcare, and education. These pipelines are trained for hundreds of thousands of hours on NVIDIA DGX systems. The training dataset includes a mix of data from noisy environments, spontaneous speech conversations, multiple English accents, and different sampling rates such as 8, 16, 32, 44, and 48 kHz. All these attributes contribute to generating a flexible, noise-robust and high-quality ASR solution out-of-the-box. This can be used as a baseline model for fine tuning to achieve faster model convergence and improving accuracy. If you want to learn how to finetune these models on your custom dataset check out the second post in this series, Speech Recognition: Customizing Models to Your Domain Using Transfer Learning.
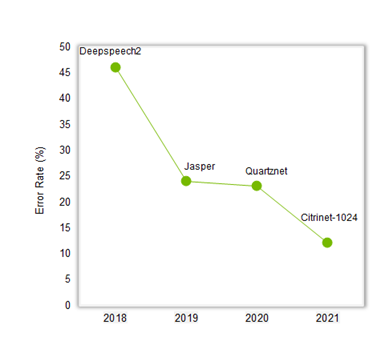
The graph in figure 2 shows the advancement in speech accuracy over the last three years with the combination of new model architectures such as Jasper, Quartznet and Citrinet, training recipes, and training data. The error rate has reduced by 4x from 46% to 12% for our real world test dataset that includes data from video conferencing, contact center and podcasts.
Real-Time Performance
To have human-like interactions, enterprises need to run speech AI models in real-time with multiple use cases requiring latency under 100 ms. Riva enables developers to deploy models as optimized services with a single command using Helm charts on Kubernetes cluster. These services are powered by NVIDIA TensorRT and NVIDIA Triton Inference Server and can run in just a few milliseconds. Riva supports running in the datacenter, at the edge and on embedded platforms.
For more information on deploying your custom models to production with NVIDIA Riva, check out the third post in this series Speech Recognition: Deploying Models to Production. Riva also supports scaling to hundreds of thousands of concurrent streams while staying within the 100ms bound for real-time ASR applications.
Refer to the Riva user guide for more detailed performance information.
