
Large language models (LLMs) have revolutionized the field of AI, creating entirely new ways of interacting with the digital world. While they provide a good generalized solution, they often must be tuned to support specific domains and tasks.
AI coding assistants, or code LLMs, have emerged as one domain to help accomplish this. By 2025, 80% of the product development lifecycle will make use of generative AI code generation, with developers acting as validators and orchestrators of backend and frontend components and integrations. You can tune an LLM for code tasks, streamline workflows for developers, and lower the barrier for novice coders. Code LLMs not only generate code, but can also fill in missing code, add documentation, and provide tips for solving hard problems.
This post explains how to deploy end-to-end code LLMs, including specific prompting guidelines, optimization techniques, and client-server deployment. We use NVIDIA Triton Inference Server and optimize using NVIDIA TensorRT-LLM, a comprehensive library for compiling and optimizing LLMs for inference. TensorRT-LLM incorporates many advanced optimizations while providing an intuitive Python API for defining and building new models.
The TensorRT-LLM open-source library accelerates inference performance on the latest LLMs on NVIDIA GPUs. It is used as the optimization backbone for LLM inference in NVIDIA NeMo, an end-to-end framework to build, customize, and deploy generative AI applications into production. The NeMo framework provides complete containers, including TensorRT-LLM and NVIDIA Triton Inference Server, for generative AI deployments. It is also included with NVIDIA AI Enterprise, a production-grade, secure, and supported software platform to streamline adoption.
What is AI-assisted coding?
Programmers spend a lot of time looking up workarounds for common problems, or skimming online forums for faster ways to write code. The key idea behind AI code assistants is to put the information that programmers need right next to the code they are writing. The tool tracks the code and comments in the file a programmer is working on, as well as other files that it links to or that have been edited in the same project. It sends all this text to an LLM as a prompt. It then predicts what the programmer is trying to do and suggests code to accomplish it.
Deploying your own AI coding assistant
To deploy your own AI coding assistant, you will need basic knowledge of deep learning inference and LLMs, along with:
- Hugging Face registered user access and general familiarity with the Transformers library
- Python
- NVIDIA TensorRT-LLM optimization library
- NVIDIA Triton with TensorRT-LLM backend
This tutorial uses StarCoder, a 15.5B parameter LLM trained on 80+ programming languages from The Stack (v1.2). The base model for StarCoder was trained on 1 trillion tokens sourced from 80+ programming languages, GitHub issues, Git Commits, and Jupyter Notebooks. StarCoder was fine-tuned on top of it using another 35B Python tokens, leading to the StarCoder model.
Given a request for code to solve a specific problem, StarCoder can generate the code from scratch. It also supports fill-in-the middle (FIM), or infilling, which enables the model to generate code conditioned on prefix and suffix code surrounding the insertion point (single-line infilling, return type prediction, and docstring generation, for example).
Prompts for code LLMs
This section features the optimization process. StarCoder was trained on code repositories from the public domain, so it can generate snippets in various languages. A code-based prompt for LLM is a prompt that asks the LLM to generate code in a specific language. The ideal prompt should be specific and clear, providing enough information for the LLM to generate a correct answer.
For example, you could issue a generic prompt such as:
Write a function that computes the square root.
# Use Newton's method,
# where x_(n+1) = 1/2 * (x_n + (y/x_n))
# y = number to find square root of
# x_0 = first guess
# epsilon = how close is close enough?
# Implement this in a function called newton_sqrt that has three parameters
# and returns one value.
Specifying the programming language and output will yield better results. For example:
Write Python code to compute the square root and print the result.
# To find the square root of a number in Python, you can use the math library and its sqrt function:
from math import sqrt
number = float(input('Enter a number: '))
square_root = sqrt(number)
print(f'The square root of {number} is approximately {square_root:.2f}.')
Prompt engineering for code LLMs
Prompt engineering consists of providing code blocks, single lines of code, or developer comments in order to improve coding suggestions for specific use cases. There are several guidelines to keep in mind with specific prompt engineering for code LLMs, including snippeting and example outputs.
Snippeting
In general, LLMs are limited in the size of their context window. This is especially relevant for code LLMs, as source code often consists of multiple files and long text, often not fitting within LLM context windows. Therefore, prompt engineering for code LLMs requires additional preparation for source code prior to prompting. This can include splitting files into smaller code snippets, choosing the most representative code samples, and using prompt optimization techniques to further decrease the number of input tokens.
Adding example outputs
Prompts that include example outputs and import instructions will yield the best results.
You’ll get average results with a prompt such as:
Write a function for calculating average water use per household.
Adding an example will yield much better results:
Write a function for calculating average water use per household.
Example output ["Smith", 20, "Lincoln", 30, "Simpson", 1500]
And your results will be even better by adding an example and specifying import instructions:
Write a function for calculating average water use per household.
Example input [['Last Name', 'Dishwasher', 'Shower', 'Yard'],
['Smith', 39, 52, 5],
['Lincoln', 25, 77, 18],
['Simpson', 28, 20, 0]]
Example output ["Smith", 32, "Lincoln", 40, "Simpson", 16]
Experiment
Use different prompts and update with finer details at each step to improve output. For example:
Write a function for calculating average water use per household.Write a function for calculating average water use per household. Add penalties for dishwasher time.Write a Python function for calculating average water use per household. Add penalties for dishwasher time. Input is family name, address, and number of gallons per specific use.
Overview of flow
To optimize an LLM with TensorRT-LLM, you must understand its architecture and identify which common base architecture it most closely resembles. StarCoder uses the GPT architecture, so this tutorial is based on the NVIDIA/TensorRT-LLM GPT example.
Use the converter and build scripts in this directory to compile StarCoder and prepare it for hardware acceleration. Note that the tokenizer is not handled directly by TensorRT-LLM. However, it is necessary to be able to classify it within a defined tokenizer family for runtime and for setting preprocessing and postprocessing steps in Triton.
Set up and build TensorRT-LLM
Start by cloning and building the TensorRT-LLM library. The easiest way to build TensorRT-LLM and retrieve all its dependencies is to use the included Dockerfile. These commands pull a base container and install all the dependencies needed for TensorRT-LLM inside the container. It then builds and installs TensorRT-LLM itself inside the container.
git lfs install
git clone -b v0.6.1 https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
git submodule update --init --recursive
make -C docker release_build
Retrieve model weights
Download the StarCoder model from Hugging Face and place it in the /examples directory.
cd examples
git clone https://huggingface.co/bigcode/starcoder
Convert model weights format
Before compilation, convert the model weights format from Hugging Face Transformer to FasterTransformer.
# Launch the Tensorrt-LLM container
make -C docker release_run LOCAL_USER=1
cd examples/gpt
python3 hf_gpt_convert.py -p 8 --model starcoder -i ../starcoder -o ./c-model/starcoder --tensor-parallelism 1 --storage-type float16
Compile the model
The next step is to compile the model into a TensorRT engine, using the converted weights from the previous step. Compilation has many options, such as precision and selecting which optimization features to enable (in-flight batching and KV caching, for example).
python3 examples/gpt/build.py \
--model_dir examples/gpt/c-model/starcoder/1-gpu \
--dtype float16 \
--use_gpt_attention_plugin float16 \
--use_gemm_plugin float16 \
--remove_input_padding \
--use_inflight_batching \
--paged_kv_cache \
--output_dir examples/gpt/out
Run the model
TensorRT-LLM includes a highly optimized C++ runtime for executing built LLM engines and managing processes like sampling tokens from the model output, managing the KV cache, and batching requests together. You can use that runtime directly to execute the model locally.
python3 examples/gpt/run.py --engine_dir=examples/gpt/out --max_output_len 100 --tokenizer examples/starcoder --input_text "Write a function that computes the square root."
You can experiment by using a more complex prompt, including the definition of the function name, parameters, and output.
python3 examples/gpt/run.py --engine_dir=examples/gpt/out --max_output_len 100 --tokenizer examples/starcoder --input_text "X_train, y_train, X_test, y_test = train_test_split(X, y, test_size=0.1)
# Train a logistic regression model, predict the labels on the test set and compute the accuracy score"
Deploy the model on NVIDIA Triton
We recommend using NVIDIA Triton Inference Server, an open-source platform that streamlines and accelerates the deployment of AI inference workloads to create a production-ready deployment of your LLM. This will help reduce setup and deployment time. The Triton Inference Server backend for TensorRT-LLM leverages the TensorRT-LLM C++ runtime for rapid inference execution and includes techniques like in-flight batching and paged KV caching. You can access Triton Inference Server with the TensorRT-LLM backend as a prebuilt container through the NVIDIA NGC catalog.
First, create a model repository so Triton can read the model and any associated metadata. The tensorrtllm_backend repository includes the skeleton of an appropriate model repository under all_models/inflight_batcher_llm/. In that directory are the following subfolders that hold artifacts for different parts of the model execution process:
/preprocessingand/postprocessing: Contain scripts for the Triton backend for Python for tokenizing the text inputs and detokenizing the model outputs to convert between strings and the token IDs on which the model operates./tensorrt_llm: A subfolder for storing the model engine that you previously compiled./ensemble: Defines a model ensemble that links the previous three components together and tells Triton how to flow data through them.
# After exiting the TensorRT-LLM docker container
cd ..
git clone -b v0.6.1 \
https://github.com/triton-inference-server/tensorrtllm_backend.git
cd tensorrtllm_backend
cp ../TensorRT-LLM/examples/gpt/out/* all_models/inflight_batcher_llm/tensorrt_llm/1/
Pay close attention to the parameter kv_cache_free_gpu_mem_fraction, which handles memory allocation for the KV cache during inference. This parameter is set with a number between 0 and 1, and allocates GPU memory accordingly. Setting this to 1 will fill the GPU memory capacity to the maximum.
Setting this parameter is especially important when deploying large LLMs or running multiple instances of TensorRT-LLM on a single GPU. Note that the default value is 0.85. In the case of StarCoder for this tutorial, we used a value of 0.2 to avoid filling GPU memory.
With the KV cache, intermediate data is cached and reused, avoiding recomputation. Instead of recomputing full key and value matrices in every iteration, intermediate feature maps are cached and reused in the next iteration. This reduces the computational complexity of the decoding mechanism. The memory consumption of the KV cache can easily fill terabytes of data for production-level LLMs.
python3 tools/fill_template.py --in_place \
all_models/inflight_batcher_llm/tensorrt_llm/config.pbtxt \
decoupled_mode:true,engine_dir:/all_models/inflight_batcher_llm/tensorrt_llm/1,\
max_tokens_in_paged_kv_cache:,batch_scheduler_policy:guaranteed_completion,kv_cache_free_gpu_mem_fraction:0.2,\
max_num_sequences:4
Another important parameter to note is the tokenizer. You need to specify the appropriate tokenizer, as well as which category type it best fits into, to define the preprocessing and postprocessing steps required for Triton. StarCoder uses code as input, rather than sentences, so it has unique tokens and separators.
As such, it is necessary to use the specific StarCoder tokenizer by setting the tokenizer_type to auto and the tokenizer_dir to /all_models/startcoder in the configuration files. You can set this by calling fill_template.py or editing the config.pbtxt file directly.
python tools/fill_template.py --in_place \
all_models/inflight_batcher_llm/preprocessing/config.pbtxt \
tokenizer_type:auto,tokenizer_dir:/all_models/startcoder
python tools/fill_template.py --in_place \
all_models/inflight_batcher_llm/postprocessing/config.pbtxt \
tokenizer_type:auto,tokenizer_dir:/all_models/startcoder
Launch Triton
To launch Triton, first spin up the Docker container, then launch the server script specifying the numbers of GPUs the model was built for by setting the world_size parameter.
docker run -it --rm --gpus all --network host --shm-size=1g \
-v $(pwd)/all_models:/all_models \
-v $(pwd)/scripts:/opt/scripts \
nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3
# Log in to huggingface-cli to get tokenizer
huggingface-cli login --token *****
# Install python dependencies
pip install sentencepiece protobuf
# Launch Server
python /opt/scripts/launch_triton_server.py --model_repo /all_models/inflight_batcher_llm --world_size 1
Send requests
To send requests to and interact with the running server, you can use one of the Triton client libraries or send HTTP requests to the generated endpoint.
To get started with a simple request, use the following curl command to send HTTP requests to the generated endpoint:
curl -X POST localhost:8000/v2/models/ensemble/generate -d \
'{
"text_input": "write in python code that plots in a image circles with different radiuses",
"parameters": {
"max_tokens": 100,
"bad_words":[""],
"stop_words":[""]
}
}'
You can also use the more fully featured client script to interact with the running server.
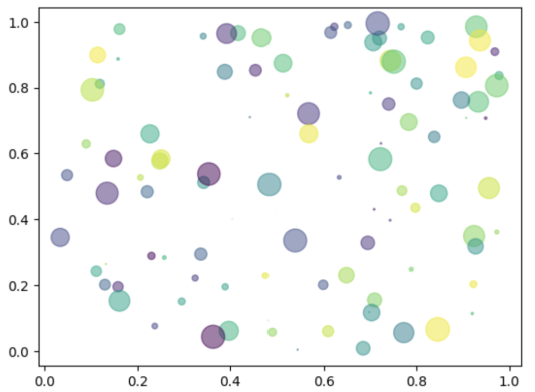
Running the command above will generate the code below. The resulting plot is shown in Figure 1.
import numpy as np
import matplotlib.pyplot as plt
# Fixing random state for reproducibility
np.random.seed(19680801)
N = 100
r0 = 0.6
x = np.random.rand(N)
y = np.random.rand(N)
area = np.pi * (10 * np.random.rand(N))**2 # 0 to 10 point radiuses
c = np.random.rand(N)
plt.scatter(x, y, s=area, c=c, alpha=0.5)
plt.show()
Get started
With baseline support for many popular LLM architectures, NVIDIA TensorRT-LLM and NVIDIA Triton make it easy to deploy, optimize, and run a variety of code LLMs. To get started, download and set up the NVIDIA/TensorRT-LLM open-source library on GitHub, and experiment with the different example LLMs. You can also download the StarCoder model and follow the steps in this post for hands-on experience.
