
AI is transforming computing, and inference is how the capabilities of AI are deployed in the world’s applications. Intelligent chatbots, image and video synthesis from simple text prompts, personalized content recommendations, and medical imaging are just a few examples of AI-powered applications.
Inference workloads are both computationally demanding and diverse, requiring that platforms be able to process many predictions on never-seen-before data quickly as well as run inference on a breadth of AI models. Organizations looking to deploy AI need a way to evaluate the performance of infrastructure objectively across a breadth of workloads, environments, and deployment scenarios. This is true for both AI training and inference.
MLPerf Inference v3.1, developed by the MLCommons consortium, is the latest edition of an industry-standard AI inference benchmark suite. It complements MLPerf Training and MLPerf HPC. MLPerf Inference v3.1 measures inference performance across a variety of important workloads, including image classification, object detection, natural language processing, speech recognition, and recommender systems, across common data center and edge deployment scenarios.
MLPerf Inference v3.1 includes two important updates to better reflect modern AI use cases:
- The addition of a large language model (LLM) test based on GPT-J–an open source, 6B-parameter LLM–to represent text summarization, a form of generative AI.
- An updated DLRM test with a new model architecture and a substantially larger dataset that mirrors the DLRM update introduced in MLPerf Training v3.0. The update better reflects the scale and complexity of modern recommender systems.
Powered by the full NVIDIA AI Inference software stack, including the latest TensorRT 9.0, NVIDIA made submissions in MLPerf Inference v3.1 using a wide array of products. These included the debut submission of the NVIDIA GH200 Grace Hopper Superchip, which extended the great per-accelerator performance delivered by the NVIDIA H100 Tensor Core GPU. NVIDIA also submitted the NVIDIA L4 Tensor Core GPU for mainstream servers, as well as both the NVIDIA Jetson AGX Orin and Jetson Orin NX platforms for edge AI and robotics.
The rest of this post provides highlights of the NVIDIA submissions as well as a peek into how these exceptional results were achieved.
Grace Hopper Superchip extends NVIDIA Hopper inference performance
The NVIDIA GH200 Grace Hopper Superchip combines the NVIDIA Hopper GPU and the NVIDIA Grace CPU through the coherent NVLink-C2C at 900 GB/s to create a single superchip. That’s 7x higher than PCIe Gen5 at 5x lower power. It also incorporates up to 576 GB of fast access memory through the combination of 96 GB of HBM3 GPU memory and up to 480 GB of low-power, high-bandwidth LPDDR5X memory.
The GH200 Grace Hopper Superchip has integrated power management features that enable the GH200 to take advantage of the energy efficiency of the Grace CPU to balance efficiency and performance. For more information, see NVIDIA Grace Hopper Superchip Architecture In-Depth and the NVIDIA Grace Hopper Superchip Architecture whitepaper.
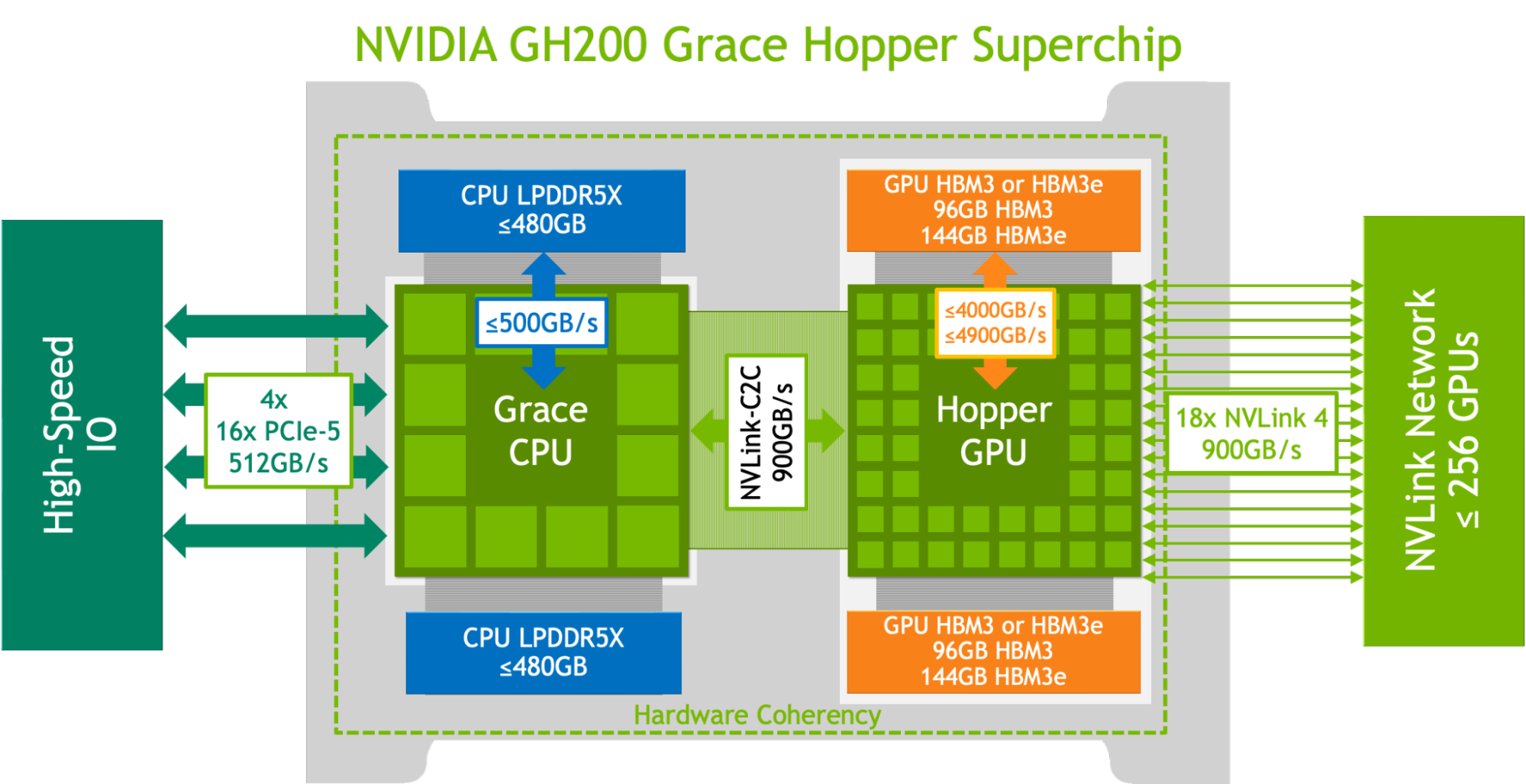
The NVIDIA GH200 Grace Hopper Superchip is designed for the versatility required to deliver leading performance across compute and memory-intensive workloads. It also delivers substantially higher performance on the most demanding frontier workloads, such as large transformer-based models with hundreds of billions or trillions of parameters, recommender systems with multi-terabyte embedding tables, and vector databases.
In addition to being built for the most intensive AI workloads, the GH200 Grace Hopper Superchip also shines on the popular, mainstream workloads tested by MLPerf Inference. It ran every test, demonstrating its seamless support for the full NVIDIA software stack. It extended the exceptional performance achieved by NVIDIA’s single H100 SXM submission on every workload.
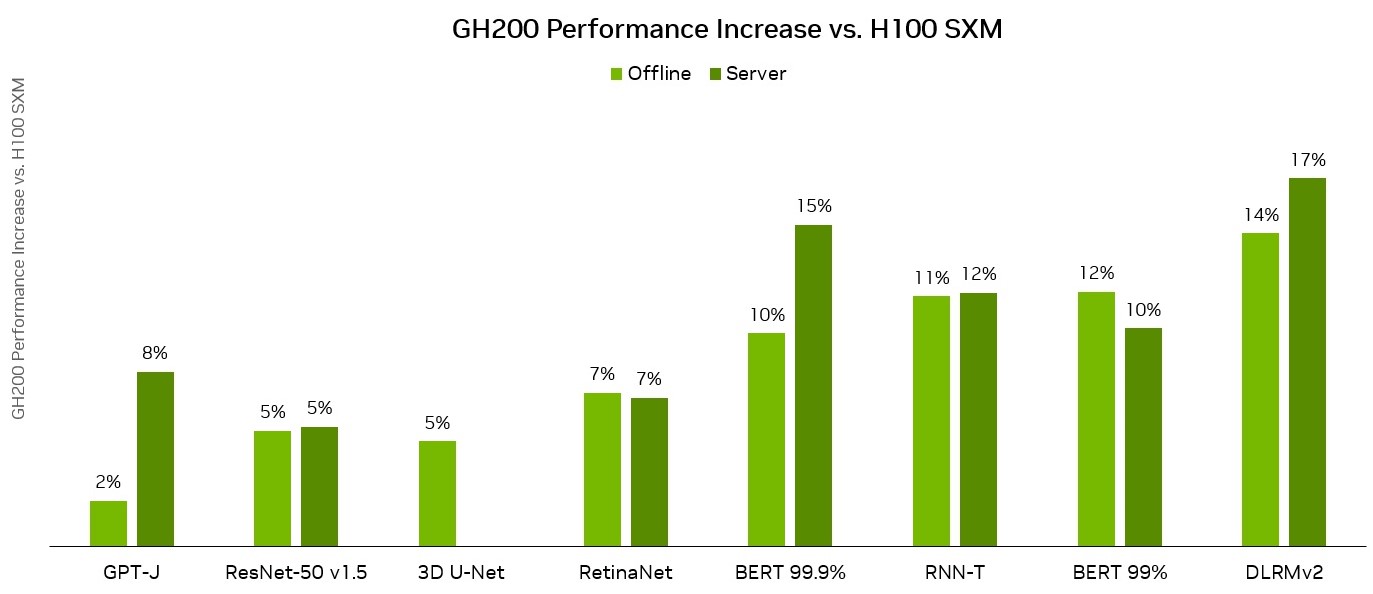
MLPerf Inference: Datacenter v3.1, Closed. Submission IDs: NVIDIA 3.1-0107(1xH100 SXM), 3.1-0110(1xGH200 Grace Hopper Superchip)
The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. For more information, see www.mlcommons.org.
The GH200 Grace Hopper Superchip incorporates 96 GB of HBM3 and provides up to four TB/s of HBM3 memory bandwidth, compared to 80 GB and 3.35 TB/s for H100 SXM, respectively. This larger memory capacity, as well as greater memory bandwidth, enabled the use of larger batch sizes for workloads on the NVIDIA GH200 Grace Hopper Superchip compared to the NVIDIA H100 SXM. For example, both RetinaNet and DLRMv2 ran with up to double the batch sizes in the Server scenario and 50% greater batch sizes in the Offline scenario.
The GH200 Grace Hopper Superchip’s high-bandwidth NVLink-C2C link between the NVIDIA Hopper GPU and the Grace CPU enables fast communication between the CPU and GPU, which can help boost performance.
For example, in the MLPerf DLRMv2 workload, transferring a batch of tensors over PCIe takes approximately 22% of the batch inference time on H100 SXM. The GH200 Grace Hopper Superchip, however, performed the same transfer using just 3% of the inference time as a result of NVLink-C2C.
Thanks to higher memory bandwidth and larger memory capacity, the Grace Hopper Superchip delivered up to 17% higher per-chip performance advantage compared to the H100 GPU on MLPerf Inference v3.1 workloads. These results showcase the performance and versatility of both the GH200 Grace Hopper Superchip and the NVIDIA software stack.
Optimizing GPT-J 6B for LLM inference
To represent LLM inference workloads, MLPerf Inference v3.1 introduces a new test based on the GPT-J 6B model: an LLM with 6B parameters. The task tested by the new benchmark is text summarization using the CNN/DailyMail dataset.
The NVIDIA platform delivered strong results on the GPT-J workload, with GH200 Grace Hopper Superchip delivered the highest per-accelerator performance on both the Offline and Server scenarios on a per-accelerator basis. The NVIDIA L4 GPU also delivered strong performance, outpacing the best CPU-only result up to 6x in a 1-slot PCIe card with a thermal design power (TDP) of just 72 Watts.
To achieve these results, NVIDIA software for LLM inference intelligently applies both FP8 and FP16 precisions to increase performance while also meeting target accuracy requirements.
A key challenge for performing GPT-J inference is the high memory consumption of the key-value (KV) cache in the transformer block. By storing the KV cache in the FP8 data format, the NVIDIA submission significantly increased the batch size used. This boosted GPU memory utilization and enabled better use of the immense compute performance of NVIDIA GPUs.
Enabling DLRM-DCNv2 submissions
MLPerf Inference v3.1 introduced an update to the DLRMv1 model used in prior versions of the benchmark. This DLRMv2 model replaces the interactions layer with a three-layer DCNv2 cross network. DLRMv2 also uses multi-hot categorical inputs rather than one-hot, which are synthetically generated from the Criteo Terabyte Click Logs Dataset.
One of the challenges of recommender inference arises from fitting the embedding tables on the system. By converting the model to FP16 precision, including the embedding table, we could both improve performance and halve the memory footprint of the embedding table, reducing it to 49 GB. This enables the entire embedding table to fit within a single H100 GPU.
To enable our submission on the L4 GPU, which has 24 GB of memory, NVIDIA software intelligently splits the embedding table between GPU and host memory using row-frequency data obtained by analyzing the training dataset. Using this data, NVIDIA software can minimize memory transfers between the host CPU and GPU by storing the most frequently used embedding table rows on the GPU.
The NVIDIA platform demonstrated exceptional results on DLRMv2, with GH200 showing up to a 17% increase compared to the great performance delivered by H100 SXM.
Maximizing parallelism on NVIDIA Jetson Orin with Programmable Vision Accelerator
The Jetson AGX Orin series and Jetson Orin NX series are embedded modules for edge AI and robotics, based on the NVIDIA Orin system-on-chip (SoC). To deliver exceptional AI performance and efficiency across a range of use cases, Jetson Orin incorporates many compute engines:
- A GPU based on the NVIDIA Ampere Architecture, with third-generation Tensor Cores
- Two second-generation, fixed-function NVIDIA Deep Learning Accelerators (NVDLA v2.0)
- One second-generation Programmable Vision Accelerator (PVA v2.0).
These accelerators can be used to offload the GPU and enable additional AI inference performance on the Jetson Orin modules.
NVDLA is a fixed-function accelerator optimized for deep learning operations and is designed to do full hardware acceleration of convolutional neural network inferencing.
For the first time in MLPerf Inference v3.1, we demonstrate the concurrent use of the PVA alongside GPU and DLA for inference. The second-generation PVA provides dedicated hardware for various computer vision kernels such as filtering, warping, and fast Fourier transforms (FFT). It also supports advanced programmed kernels, which can serve as the backend runtime of TensorRT custom plug-ins.
With the 23.08 Jetson CUDA-X AI Developer Preview, we’ve included a sample PVA SDK. This package provides runtime support for a non-maximum suppression (NMS) layer. It demonstrates that the PVA can serve as a highly capable accelerator, complementing the powerful Jetson Orin GPU.
NVIDIA has developed a TensorRT custom NMS PVA plug-in as a reference for Jetson Orin users and it was included as part of the NVIDIA MLPerf Inference v3.1 submission.
In the NVIDIA MLPerf Inference v3.0 RetinaNet submission on NVIDIA Orin platforms, the GPU handled all outputs from the ResNext + FPN backbone from the GPU as well as from the two DLAs.
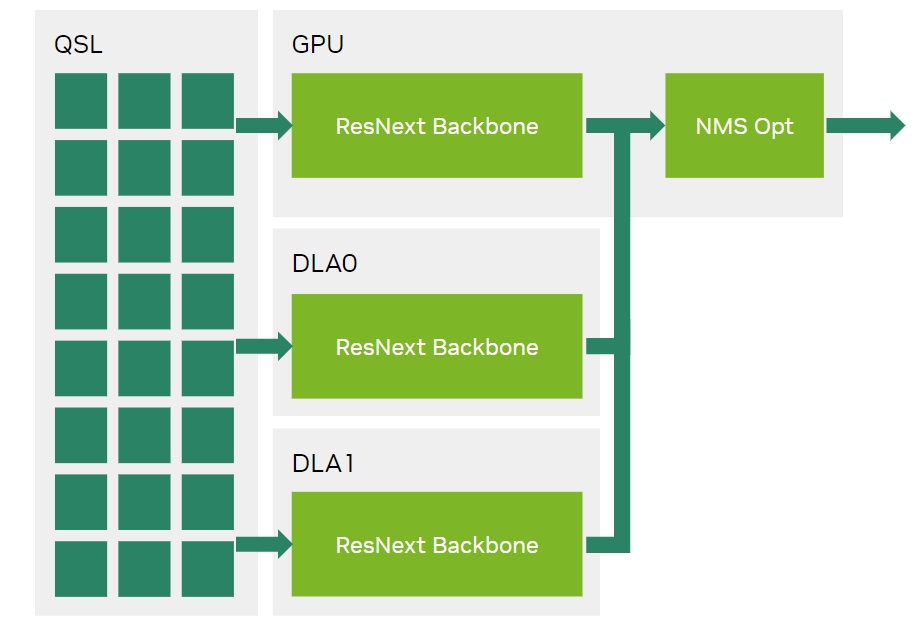
Figure 5 shows how, in MLPerf Inference v3.0 submissions, the GPU was responsible for outputs from the ResNext+FPN backbone from both the GPU and the DLAs.
By using the NMS PVA plug-in, the NMS operator is now offloaded from GPU to PVA, enabling three fully parallel inference flows on Jetson Orin AGX and Jetson Orin NX. The output from the ResNext and the FPN backbone running on the two DLAs is now consumed by the two PVAs running the NMS PVA plug-in inside the end-to-end RetinaNet TensorRT engine.
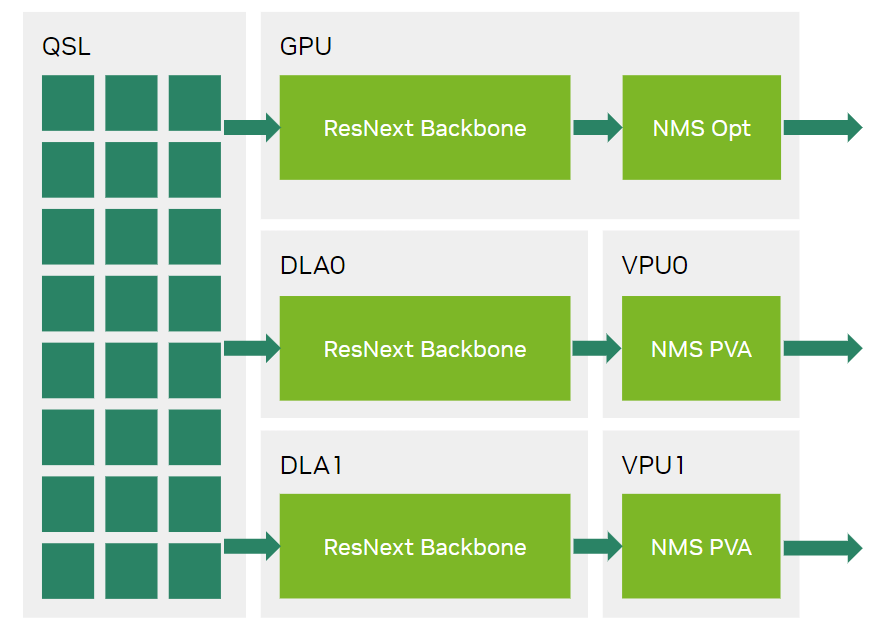
In Figure 6, the NVIDIA MLPerf Inference v3.1 submission enables computations to run fully in parallel through optimized use of Jetson Orin PVAs.
This careful use of PVA along with GPU and DLA boosts performance by 30% on both the Jetson AGX Orin 64GB and the Jetson Orin NX 16GB modules. When this use of PVA is coupled with a newly optimized NMS Opt GPU plug-in, Jetson AGX Orin delivers 61% higher performance and 38% better power efficiency on the RetinaNet workload. The Jetson Orin NX 16GB showed an even larger gain, with an 84% performance boost on the same test.
Algorithmic optimizations further improve BERT performance
In MLPerf Inference v3.1, NVIDIA made a submission on the BERT Large workload using the L4 GPU in the open division using techniques developed by the OmniML team. OmniML is a startup acquired by NVIDIA in early 2023 that brought expertise in machine learning algorithmic model optimization for use cases spanning cloud platforms to edge devices.
The open division submission on BERT applied structured pruning with distillation techniques to improve the performance by up to 4.7x while maintaining 99% accuracy. This submission demonstrates the potential of algorithmic optimizations for enhancing significantly the already exceptional performance of the NVIDIA platform.
NVIDIA deployed a proprietary, automatic, structured pruning tool that uses a gradient-based sensitivity analysis to prune the model to the given target FLOPs and fine-tune it with distillation to recover most of the accuracy. The number of transformer layers, attention heads, and linear layer dimensions were pruned in all the transformer layers in the model while the embedding dimension was kept unchanged.
Compared to the original MLPerf Inference BERT INT8 model, our pruned model reduced the number of parameters by 4x and the number of FLOPs by 5.6x. This model has a varying number of heads and linear layer dimensions in each layer. The resulting TensorRT engine built from the pruned model is 3.4x smaller, 177 MB compared to 607 MB.
The fine-tuned model is quantized to INT8 precision using the same technique employed in the NVIDIA closed division submission. The submission also employed distillation during quantization-aware training (QAT) to achieve an accuracy that is 99% or higher.
| Scenario | Closed Division | Open Division | Speedup |
| Offline samples/sec | 1029 | 4609 | 4.5x |
| Server samples/sec | 899 | 4265 | 4.7x |
| Single Stream p90 Latency (ms) | 2.58 | 0.82 | 3.1x |
To understand better how each of the model optimizations affects performance, NVIDIA performed a stacking analysis and applied different model optimization methods individually (Figure 8).
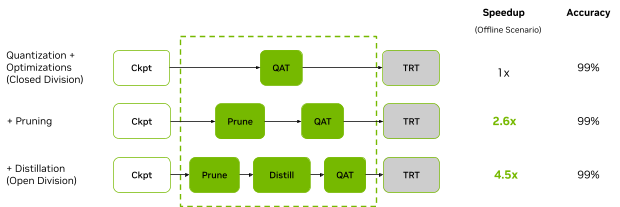
Figure 7 shows that, through model pruning and distillation, the NVIDIA open division submission on the BERT workload using L4 provides a 4.5x speedup compared to the same GPU running the closed division workload in the offline scenario.
Each model optimization method applied can be easily integrated with each other. Together, they yielded a substantial performance improvement compared to the baseline model.
NVIDIA accelerated computing boosts performance for inference and AI training workloads
In its MLPerf debut, the GH200 Grace Hopper Superchip turned in exceptional performance on all workloads and scenarios in the closed division of the data center category, boosting performance by up to 17% on the NVIDIA single-chip H100 SXM submission. The NVIDIA software stack fully supports the GH200 Grace Hopper Superchip today.
For mainstream servers, the L4 GPU showed delivery of a large performance leap over CPU-only offerings in a compact, low-power, PCIe add-in card.
For edge AI and robotics applications, the Jetson AGX Orin and Jetson Orin NX modules achieved great performance. Software optimizations helped to further unlock the potential of the powerful NVIDIA Orin SoC that powers those modules. It boosted performance on RetinaNet, a popular AI network for object detection, by up to 84%.
In this round, NVIDIA also submitted results in the open division, providing a first look at the potential for model optimizations to speed inference performance dramatically while still achieving excellent accuracy.
The latest MLPerf Inference v3.1 benchmarks show that the NVIDIA accelerated computing platform continues to deliver leadership performance and versatility. There’s innovation at every layer of the technology stack, from cloud to edge, at the speed of light.
